Lucene是apache开源的一个全文检索框架,很是出名。今天先来分享一个类似于HelloWorld级别的使用。
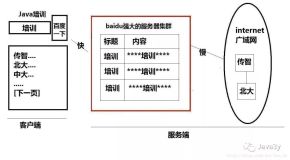
工作流程

依赖
我们要想使用Lucene,那就得先引用人家的jar包了。下面列举一下我使用到的jars.
-
lucene-analyzers-common-6.1.0.jar: 分析器支持 -
lucene-core-6.1.0.jar: 全文检索核心支持 -
lucene-highlighter-6.1.0.jar: 检索到的目标词的高亮显示 -
lucene-memory-6.1.0.jar: 索引存储相关的支持 -
lucene-queries-6.1.0.jar: 查询支持 -
lucene-queryparser-6.1.0.jar: 查询器支持
Lucene HelloWorld
下面就着手实现一个级别为HelloWorld的小例子。实现一个基于文章内容的查询。
Article.java
/**
* @Date 2016年8月1日
*
* @author Administrator
*/
package domain;
/**
* @author 郭瑞彪
*
*/
public class Article {
private Integer id;
private String title;
private String content;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTitle() {
return title;
}
@Override
public String toString() {
return "Article [id=" + id + ", title=" + title + ", content=" + content + "]";
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
创建索引库
@Test
public void createIndex() throws Exception {
// 模拟一条文章数据
Article a = new Article();
a.setId(1);
a.setTitle("全文检索");
a.setContent("我们主要是做站内搜索(或叫系统内搜索),即对系统内的资源进行搜索");
// 建立索引
Directory dir = FSDirectory.open(Paths.get("./indexDir/"));
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(new StandardAnalyzer());
IndexWriter indexWriter = new IndexWriter(dir, indexWriterConfig);
Document doc = new Document();
doc.add(new StringField("id", a.getId().toString(), Field.Store.YES));
doc.add(new TextField("title", a.getTitle(), Field.Store.YES));
doc.add(new TextField("content", a.getContent(), Field.Store.YES));
indexWriter.addDocument(doc);
indexWriter.close();
}从索引库中获取查询结果
@Test
public void search() throws Exception {
String queryString = "资源";
Analyzer analyzer = new StandardAnalyzer();
analyzer.setVersion(Version.LUCENE_6_1_0);
QueryParser queryParser = new QueryParser("content", analyzer);
Query query = queryParser.parse(queryString);
// IndexReader indexReader =
// DirectoryReader.open(FSDirectory.open(Paths.get("./indexDir/")));
DirectoryReader directoryReader = DirectoryReader.open(FSDirectory.open(Paths.get("./indexDir/")));
IndexReader indexReader = directoryReader;
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
TopDocs topDocs = indexSearcher.search(query, 10);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List<Article> articles = new ArrayList<Article>();
for (int i = 0; i < scoreDocs.length; i++) {
ScoreDoc scoreDoc = scoreDocs[i];
Document doc = indexSearcher.doc(scoreDoc.doc);
Article a = new Article();
a.setId(Integer.parseInt(doc.get("id")));
a.setTitle(doc.get("title"));
a.setContent(doc.get("content"));
System.out.println(a.toString());
articles.add(a);
}
// 显示结果
System.out.println("总的记录数为: " + topDocs.totalHits);
System.out.println(articles.toString());
for (Article a : articles) {
System.out.println("-----------搜索结果如下-----------------");
System.out.println(">>>id: " + a.getId());
System.out.println(">>>title:" + a.getTitle());
System.out.println(">>>content:" + a.getContent());
}
indexReader.close();
analyzer.close();
}查询结果
总的记录数为: 4
-----------搜索结果如下-----------------
>>>id: 1
>>>title:全文检索
>>>content:我们主要是做站内搜索(或叫系统内搜索),即对系统内的资源进行搜索
-----------搜索结果如下-----------------
>>>id: 2
>>>title:全文检索2
>>>content:我们主要是做站内搜索(或叫系统内搜索),即对系统内的资源进行搜索,hahahahahhaha
总结
Lucene全文检索的功能可以这么简单的实现,但是里面有更多的用法等着我们去挖掘。