看完前两篇博客之后,想必大家对于Lucene的使用都有了一个比较清晰的认识了。如果对Lucene的知识点还是有点模糊的话,个人建议还是先看看这两篇文章。
全文检索 Lucene(1)
全文检索 Lucene(2)
下面来谈一谈使用Lucene查询的分页机制。

分页原理
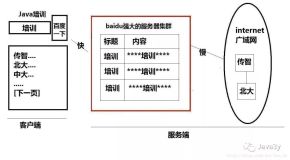
分页就是为了给用户展现一个逻辑性更强,页面更加紧凑的视图效果。相比于数据库实现的分页,Lucene就显得有点逊色了。毕竟数据库是原生支持的,这点没法改变。
这里说的对Lucene实现的分页机制其实并不是真正的分页,不妨这样想,当我们的TopDocs的大小设置很大,我们的电脑势必会出现内存不足的情况,即使有虚拟内存技术,这也是没办法消除的。这样的话查询机制就会崩溃。这一点我们待会再讲。
Dao层代码实现
由于本例是基于全文检索 Lucene(2)的延伸,所以就不再重新贴出那么多的代码了。这里仅仅是核心逻辑。
页面对象
/**
* @Date 2016年8月1日
*
* @author Administrator
*/
package domain;
import java.util.List;
/**
* @author 郭瑞彪
*
*/
public class Page<T> {
private List<T> lists;
private int totalResults;
public List<T> getLists() {
return lists;
}
public void setLists(List<T> lists) {
this.lists = lists;
}
public int getTotalResults() {
return totalResults;
}
public void setTotalResults(int totalResults) {
this.totalResults = totalResults;
}
@Override
public String toString() {
return "Page [lists=" + lists + ", totalResults=" + totalResults + "]";
}
}
分页方法
/**
* 从索引库中查询
*
* <br>
* 支持分页技术
*
* @param queryString
* 查询字符串
* @return
*/
public Page search(String queryString, int firstResult, int maxResult) {
try {
// 1.queryString -->>Query
String[] queryFields = new String[] { "title", "content" };
Analyzer analyzer = new StandardAnalyzer();
analyzer.setVersion(Version.LUCENE_6_0_0.LUCENE_6_1_0);
QueryParser queryParser = new MultiFieldQueryParser(queryFields, analyzer);
Query query = queryParser.parse(queryString);
// 2. 查询,得到topDocs
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcher();
TopDocs topDocs = indexSearcher.search(query, 100);
// 3.处理结果并返回
int totalHits = topDocs.totalHits;
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List<Article> articles = new ArrayList<Article>();
int upperBound = (firstResult + maxResult) < scoreDocs.length ? (firstResult + maxResult)
: scoreDocs.length;
firstResult = (firstResult >= 0 ? firstResult : 0);
for (int i = firstResult; i < upperBound; i++) {
ScoreDoc scoreDoc = scoreDocs[i];
Document doc = indexSearcher.doc(scoreDoc.doc);
Article a = ArticleDocumentUtils.document2Article(doc);
articles.add(a);
}
LuceneUtils.closeIndexSearcher(indexSearcher);
// 处理查询结果,返回一个封装好的页面对象
Page<Article> page = new Page();
page.setLists(articles);
page.setTotalResults(totalHits);
return page != null ? page : null;
} catch (Exception e) {
throw new RuntimeException("ArticleIndexDao-->> search方法出错!\n" + e);
}
}核心释义
我对分页的理解:
以Java面向对象的思维,页面本身就是一个对象。我们不妨现在就打开一个搜索引擎,搜索一下。看看页面结果。大概就能知道底层有什么东西了。
一般来说,做分页一定要知道总的记录数,然后是从哪一页开始分页。这是很有必要的。而且边界值我们也需要好好的进行维护。
int upperBound = (firstResult + maxResult) < scoreDocs.length ? (firstResult + maxResult)
: scoreDocs.length;
firstResult = (firstResult >= 0 ? firstResult : 0);Lucene伪分页:
下面接着上面没说完的关于Lucene的伪分页。我们也可以从代码中看出
// 2. 查询,得到topDocs
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcher();
TopDocs topDocs = indexSearcher.search(query, 100);
// 3.处理结果并返回
int totalHits = topDocs.totalHits;
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (int i = firstResult; i < upperBound; i++) {
ScoreDoc scoreDoc = scoreDocs[i];
Document doc = indexSearcher.doc(scoreDoc.doc);
Article a = ArticleDocumentUtils.document2Article(doc);
articles.add(a);
}我们可以看出indexSearcher.search(query, 100);。我们还是查询到了小于等于前100得分项的记录,想象一个这个100设置成10000000000000000呢?结果会怎么样? 估计电脑会受不了的吧。
所以从这里也可以看出,不是任何情况都是适合适用Lucene的,搜们要根据需求来决定。