一:背景
--->随着互联网技术的高速发展,企业对计算机系统的计算,存储能力要求越来越高,最简单的明证就是出现一些诸如:高并发,海量存储这样的词汇。在这样的背景下,单纯依靠少量高性能主机来完成计算任务已经不能满足企业需求,企业的IT架构逐步从集中式向分布式过渡,所谓的分布式:把一个计算任务分解成若干个计算单元,并且分派到若干不同的计算机中去执行,然后汇总计算结果的过程。
---->ZooKeeper 是一个开源分布式协调服务,独特的Leader-Follower的集群结构,很好的解决了分布式单点问题。目前主要用于诸如:统一命名服务、配置管理、锁服务、集群管理等场景
二:zookeeper的概念
--->ZooKeeper是针对分布式应用的高性能协调服务,是高效可靠的协同工作系统
--->提供的功能包括配置维护,名字服务,分布式同步,组服务。
--->ZooKeeper的目标就是封装好复杂,易出错的关键服务。将简单易用的接口和性能高效,功能稳定的系统提供给用户
--->ZooKeeper是Hadoop的正式子项目。高性能。
--->分布式协调服务,它是解决分布式数据一致性问题。
三:zookeeper的服务的应用
A顺序一致性
(1)从一个客户端发起一个事务请求,最终会严格按照发起的顺序被应用到Zookeeper中
B原子性
(1)所有事务请求的处理结果,在整个集群的所有机器上应用情况是一致的。
C单一视图
(1)无论客户端,链接到zookeeper集群中哪个服务上,看到的服务端数据都是一样的。
D可靠性
(1)一旦服务端完成了客户端一个事务,并响应了客户端,对服务端的状态改变是会保存下来的。除非另一个事务对它做了修改。
E实时性
(1)zookeeper保证在一段时间内客户端最终一定能从服务端读取最新的数据状态
F高性能
(1)吞吐量很大,一个3台机子的zookeeper集群可以达到12-13万的qps
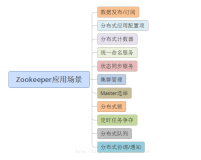
四:zookeeper的服务的应用场景
(1)发布定阅。
--->一方把数据发布出来,另一方通过某种手段可以得到这些数据。
--->通常数据订阅有两种方式:推模式和拉模式,推模式一般是服务器主动向客户端推送消息。拉模式是客户端主动去服务器获取数据(通常采用定时轮询的方式)
--->zk集群采用推拉模式相结合。发布者将数据发布到zk集群节点上,订阅者通过一定的方法告诉服务器,我对哪儿节点的数据感兴趣,那服务器在这些节点的数据发生变化时,就通知客户端,客户端得到通知后可以去服务器获取数据信息。
(2)负载均衡
(3)命名服务
(4)分布式协调/通知
--->心跳检测
(5)集群管理
(6)Master选举
(7)分布式锁
(8)分布式队列
五:zookeeper的设计目标
zookeeper致力于提供一个高性能,高可用,且具有严格的顺序访问控制能力(主要是写操作的严格顺序性)的分布式协调服务。高性能使得Zookeeper能够应用于那些对系统吞吐有明确要求的大型分布式系统中,高可用使得分布式的单点问题得到了很好的解决,而严格的顺序访问控制使得客户端能够基于Zookeeper实现一些复杂的同步原语。
●目标一:简单的数据模型
--->Zookeeper使得分布式程序能够通过一个共享的,树型结构的名字空间进行相互协调。这里所说的树型结构的名字空间,是指Zookeeper服务器内存中的一个数据模型,尤其一系列被称为ZNode的数据节点组成,总的来说,其数据模型类似于一个文件系统,而ZNode之间的层级关系,就像文件系统的目录结构一样。不过和传统的磁盘文件系统不同的是,Zookeeper将全量数据存储在内存中,以此来实现提高服务器吞吐,减少延迟的目的。
●目标二:可以构建集群
--->一个ZooKeeper集群通常由一组机器组成,一般3~5台机器就可以组成一个可用的ZooKeeper集群了
--->组成Zookeeper集群的每台机器都会在内存中维护当前的服务器状态,并且每台机器之间都互相保持着通信。值得一提的是,只要集群中存在超过一半的机器能够正常工作,那么整个集群就能够正常对外服务。
--->Zookeeper的客户端程序会选择和集群中任意一台机器共同来创建一个TCP连接,而一旦客户端和某台Zookeeper服务器之间的链接断开后,客户端会自动链接到集群中的其他机器。
●目标三:顺序访问
--->对于来自客户端的每个更新请求,Zookeeper都会分配一个全局唯一的递增编号,这个编号反映了所有事务操作的先后顺序,应用程序都可以使用ZooKeeper的这个特性来实现更高层次的同步原语。
●目标四:高性能
--->由于ZooKeeper将全量数据存储在内存中,并直接服务于客户端的所有非事务请求,因此它尤其适用于以读操作为主的应用场景,作者曾经一3台3.4.3版本的ZooKeeper服务器组成集群进行性能压测,100%读请求的场景下压测结果是12-13W的QPS
一:ZooKeeper简介
2016-02-23
1228
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议》和
《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
本文涉及的产品
简介:
一:背景 --->随着互联网技术的高速发展,企业对计算机系统的计算,存储能力要求越来越高,最简单的明证就是出现一些诸如:高并发,海量存储这样的词汇。在这样的背景下,单纯依靠少量高性能主机来完成计算任务已经不能满足企业需求,企业的IT架构逐步从集中式向分布式过渡,所谓的分布式:把一个计算任务分解成若干个计算单元,并且分派到若干不同的计算机中去执行,然后汇总计算结果的过程。

目录
相关文章
|
4月前
|
存储
负载均衡
网络协议
|
11月前
|
存储
消息中间件
分布式计算
|
分布式计算
Java
Hadoop
flink hadoop 从0~1分布式计算与大数据项目实战(4)zookeeper内部原理流程简介以及java curator client操作集群注册,读取
flink hadoop 从0~1分布式计算与大数据项目实战(4)zookeeper内部原理流程简介以及java curator client操作集群注册,读取
228
0
0
|
存储
设计模式
负载均衡

|
存储
分布式计算
Hadoop
|
Dubbo
应用服务中间件
API
|
存储
分布式计算
网络协议
|
存储
网络协议
Java
ZooKeeper简介
ZooKeeper简介
ZooKeeper:分布式应用的协调服务
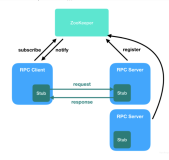
ZooKeeper是一个分布式的开源协调服务,用于分布式应用程序。它公开了一组简单的原子操作,分布式应用程序可以构建这些原子操作,以实现更高级别的服务,以实现同步,配置维护以及组和命名。
1306
0
0
热门文章
最新文章
1
云效 AppStack + 阿里云 MSE 实现应用服务全链路灰度
2
云原生最佳实践系列 6:MSE 云原生网关使用 JWT 进行认证鉴权
3
云原生最佳实践系列 3:基于 SpringCloud 应用玩转 MSE
4
云原生最佳实践系列2:基于 MSE 云原生网关同城多活
5
阿里云微服务引擎及 API 网关 2024 年 3 月产品动态
6
KubeSphere 核心实战之三【在kubesphere平台上部署ElasticSearch、应用商店部署RabbitMQ和应用市场部署Zookeeper】(实操篇 3/4)
7
ZooKeeper分布式协调服务详解:面试经验与必备知识点解析
8
nacos常见问题之Serverless 应用引擎2.0不支持 MSE nacos如何解决
9
【ZooKeeper系列】那ZooKeeper为什么还采用ZAB协议
10
云效AppStack+阿里云MSE实现应用服务全链路灰度
1
ZooKeeper基本架构
148
2
ZooKeeper应用案例
150
3
云效AppStack+阿里云MSE实现应用服务全链路灰度
121399
4
阿里云微服务引擎 MSE 及 API 网关 2024 年 02 月产品动态
459
5
Kafka【环境搭建 02】kafka_2.11-2.4.1 基于 zookeeper 搭建高可用伪集群(一台服务器实现三个节点的 Kafka 集群)
140
6
阿里云微服务引擎及 API 网关 2024 年 2 月产品动态
626
7
阿里云微服务引擎 MSE 2024 年 01 月产品动态
201
8
【基础回顾】在回归任务中常见的损失函数比较(mse、mae、huber)
101
9
Zookeeper实现分布式服务配置中心
48
10
使用KMS为MSE-Nacos敏感配置加密的最佳实践
92262



