为什么需要进行全文搜索呢?
一个表中有a、b、c多个字段。我们使用sql进行like搜索的时候,往往只能匹配某个字段。或者是这样的形式:a LIKE “%关键词%”or b LIKE “关键词”
这样子根本没法实现全文搜索,如果需要搜索整个表中所有出现过关键词”手机”的商品,一般要匹配商品的标题字段。而如果商品描述中出现”手机”关键词,则没法去匹配。
全文搜索,就是不限制搜索某个字段,是对数据库中所有的内容做匹配,是全文级别的搜索。是针对所有内容都进行匹配。这需要预先建立好索引数据结构。比如记录哪个文档中出现过某个关键词。
其实在11年的时候就已经研究过sphinx,理解还比较粗浅。
那个时候没有在生产环境中使用过。当时研究的是,安装sphinxSE存储引擎来实现。在本地电脑上搭建。sphinx作为mysql的一个存储引擎,结合到了mysql数据库中去。这样子查询sql不用做很多变动。
到2013年,才放到公司生产环境中使用。于是,自己完整搭建了一个sphinx环境。
sphinx充当什么角色?
帮助建立全文索引结构。查询的时候直接从这个索引结构中查询,可以快速实现查询。
sphinx是建立如下的倒排索引结构(学过倒排索引,估计大体是这样子):
关键词 此关键词出现文档编号(也就是mysql表中的主键值)
中国 8,9,10....
我 20,10...
.. ....
这样当你输入关键词"中国"进行查询的时候。马上就能从右边的文档列表中知道,哪些文档包含这个词语。
我对分词的理解是:所有涉及到全文索引的、分词。最终目标都是为了建立上面这样的倒排索引结构,那为什么要建立这样的结构,就是为了搜索某个词
语的时候,快速查询。
sphinx的实现原理
它可以从mysql数据库中获取数据,然后分词,对每个词语建立索引结构,可以理解成像下面这样的形式
比如,从mysql中获取到句子"我是中国人"
从这个内容中提取关键词,建立像下面这样的索引结构
关键词 此关键词出现文档编号(也就是mysql表中的主键值,对应就知道哪一行)
中国 8,9,10....
我 20,10...
什么样的词语作为关键词呢?"中国"还是"中国人"
所以就涉及到一个切词标准,切词方法又是一门细分领域的学科,分很多种切词算法。
因为sphinx是国外人编写的,默认只支持一元分词法,一元分词法就是:为每个字符都建立一个索引项(放在中文中就是每个汉字建立索引项)。
sphinx可以使用一元分词法,也就是每个汉字都作为关键词加入索引中去。
疑问:官方的sphinx默认是不是只支持一元分词法,或者是可以配置最小切割词语。比如配置最小字符是1,2,3,4。
有个min_word_len可以配置大于等于这个长度的单词才能被索引(联想mysql数据库中针对索引也有类似的设置)
比如设置长度为3,则句子中的"he is my wife",he 和my这两个单词不会建立索引。因为这两个单词长度为2。
使用一元分词法,将这个配置项设置为1才行。
一元分词法,不需要使用词典来分词,因为无非就是按照一个一个字符来切。由于涉及到中文分词,需要用到词典,分发版sphinx-for-chinese和coreseek将sphinx改成可以配置分词词典的方式了,也就是可以配置一个分词词典,使用这个词典里面的词语来作为分词标准。在这个词典里面出现的词语,就会被加入索引中去。
两种方式来使用sphinx的查询服务
第一种是直接使用sphinx提供的api接口来操作。
第二种是安装一个sphinxSE,这个可以看成是一个以mysql存储引擎嵌入mysql的sphinx客户端。最终由它来完成与sphinx服务器的请求。还可以实现sql关联查询。
我觉得还是使用api形式的方式比较灵活自由,相互独立起来,减少系统之间相互影响。这种还很方便做分布式sphinx服务器(安装多个sphinx服务端)
下面这张图是以前整理的文档中拿过来,不清楚从网上哪里来的了,因为2年前的学习了。

这次在公司生产环境,使用的是api的形式提供查询,这种情况是不需要安装sphinxSE存储引擎。
说道这个sphinx,以前一直不知道怎么读比较好。后来才知道读作:斯芬克斯。
斯芬克斯(sphinx)是希腊神话里一个带翼的怪物。这个软件取这个名字,不知道取其什么含义。
选择哪个分发版本
sphinx是俄罗斯人写的。对英文、俄文这样切词就比较好。但是对中文仍然是问题,里面内置的分词方法并不支持中文分词,这跟中文特殊性有关。一般中文分词,都需要专门的分词办法。国外的软件不会帮你做这方面。
因为sphinx是开源的,所以完全可以修改源码,于是有人就修改原版的sphinx,加上了自己适合中文分词的部分。
网上有人就建议了:暂时不要选择原版Sphinx(对中文分词的支持不是很好). Sphinx for chinese和coreseek建议这两个中选择一个。
我也是在linux上安装了原版的后,后面改用了sphinx-for-chinese。
sphinx-for-chinese在linux的安装过程,这里暂时不详细归纳了。重点归纳我在实际使用中,觉得需要注意的地方
关于配置文件:sphinx.conf
配置文件在安装目录的etc目录下面,如下

安装好后,会有如下几个目录

etc目录是配置文件放的目录,这是很多linux软件的一个约定习惯。
一般看到etc这个目录都会是配置文件目录
bin目录是一些辅助工具。服务进程程序searchd和索引操作工具indexer在这个目录下面。
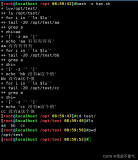
1、启动sphinx服务
/data/installsoft/sphinx-for-chinese/bin/searchd -c /data/installsoft/sphinx-for-chinese/etc/sphinx.conf
searchd是sphinx的服务进程。-c 后面指定sphinx服务启动时使用哪个配置文件。
不像其他软件那样,启动的时候需要手动指定端口,只要使用-c指定配置文件,配置文件中配置好了端口的。
2、建立索引
/data/installsoft/sphinx-for-chinese/bin/indexer -c /data/installsoft/sphinx-for-chinese /etc/sphinx.conf --all --rotate
使用”安装目录/bin/search”这个命令行工具来测试搜索某个词语。
search与searchd的区别:searchd是服务进程。官方提供search只是为了方便测试用的。这个程序使用的时候,并不依赖于searchd服务进程是否启动。只要索引数据存储就能使用。可以通俗理解,它是去读取索引文件获取搜索结果。
切词方式的选择
sphinx内置默认是支持一元分词法,也就是每个字符都建立索引项。
是一个没法完美的问题。一般也是多种分词方法结合起来。我当时使用的就是一元分词,因为数据量小,为每个汉字建立索引项,整个索引数据也小,省去折腾搜索不精准的问题了(每个汉字都建立了索引,无效的数据当然也是有的)。
sphinx服务端口
sphinx在版本0.9.9开始,官方已在IANA获得正式授权的9312端口,以前版本默认的是3312。
了解了切词方式,那么对sphinx的切词就会更加容易理解了。
本文未完待续,只表示当时的想法,以后还会完善