Learning to Track: Online Multi-Object Tracking by Decision Making
ICCV 2015
本文主要是研究多目标跟踪,而 online 的多目标检测的主要挑战是 如何有效的将当前帧检测出来的目标和之前跟踪出来的目标进行联系。本文将 online MOT problem 看做是 MDPs 问题,用一个 MDP 来建模一个物体的生命周期。学习物体相似性的度量 就等价于学习MDP的一个策略,而该策略的学习可以用RL 的方式进行,能够兼顾 online 和 offline 方式的优点。与此同时,本文算法可以处理物体的出现和消失的情况,即将该过程转化为 MDP的状态转移问题。
1. Introduction
首先介绍的是 MOT 的重要意义和广泛的应用,然后提出各个其他算法基本都是 batch mode 的进行跟踪。进一步的指出这种算法模式不适合需要 online 的应用场景,如:机器人导航 和 自动驾驶等问题。
然后提出对于 online mode 中tracking-by-detection方法的主要挑战是:how to associate noisy object detections in the current video frame with previously tracked objects ? 任何数据联系算法的基础都是物体检测和目标的相似性函数的计算。为了排除联系过程中的模糊现象,要尽可能的利用一切有用的信息来协助进行联系,如:appearance,location,motion等等。
最近的MOT算法可以大致分为两类:
首先是,offline-learning,在进行跟踪之前就进行学习,从gt轨迹有监督的学习到物体检测和目标之间的相似性函数。所以,offline-learning 是静态的:他没有考虑到动态状态和物体的轨迹,这些在实际跟踪过程中缓解模糊情况,都是非常重要的。
与此对应的是,online learning 是在跟踪的过程中进行学习。一种常见的策略是将跟踪地结果分为 positive and negative samples,然后根据这些样本进行相似性函数的计算(similarity function)。
online-learning的方法可以充分的结合 dynamic status 和 the history of the target。但是悲剧的是,并没有 gt 可以参考进行有监督的学习。所以,就容易导致当跟踪地结果出现误差时,错误的分类,最终导致模型的 drift。
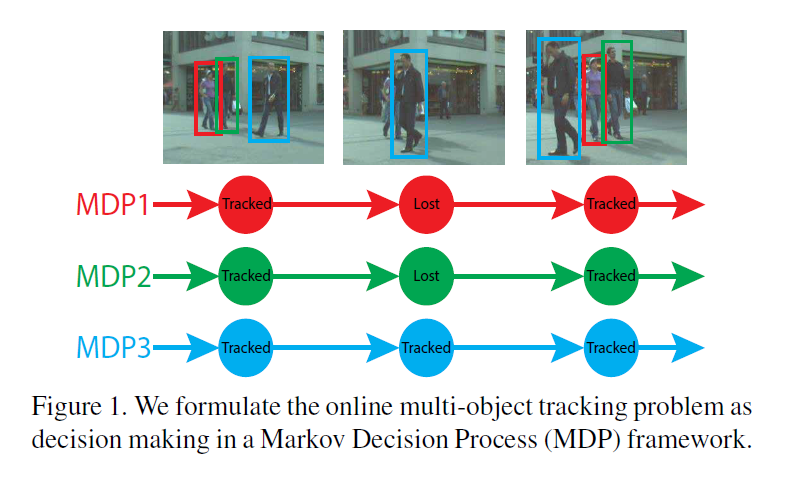
如上图所示,本文将单个目标的跟踪问题看做是 MDP 过程中的策略决定问题,从而,多目标跟踪就变成了多个 MDP 的问题。本文将数据联系的相似性函数的学习看作是学习MDP的一个策略。策略的学习通过 RL 的方式,可以兼顾 offline learning 和 online learning 的优势。
首先,学习以offline的方式进行,所以可以利用 gt 轨迹进行协助的有监督方式进行;
其次,当跟踪目标出现在训练序列中才进行学习,所以 MDP 可以根据当前的状态和轨迹的历史进行综合的做出决定。
特别地,给定物体的 gt 轨迹 和一个初始的相似性函数,MDP 可以试着去跟踪物体然后从gt中收集反馈信息。根据反馈信息,MDP 更新相似性函数来改善跟踪性能。只有当 MDP 做出了错误的决定时,才进行相似性函数的更新,这样就可以确保我们收集hard training samples 来学习相似性函数。
最后,MDP 可以成功的跟踪上物体的时候,就停止学习过程。
除了我们学习策略的优势之外,还可以自然的处理物体的消失和产生,即:将其看做是MDP 的状态转移问题。我们的方法也从 online 的单目标跟踪方法上受益,我们学习和更新一个 appearance model 来处理物体检测失败的情况。
2. 相关工作(略)
3. Online Multi-Object Tracking Framework
3.1 Markov Decision Process
本文的框架中,用MDP 来建模一个物体的 lifetime,主要包括四个成分:状态,动作,状态转移矩阵,实值奖励函数。
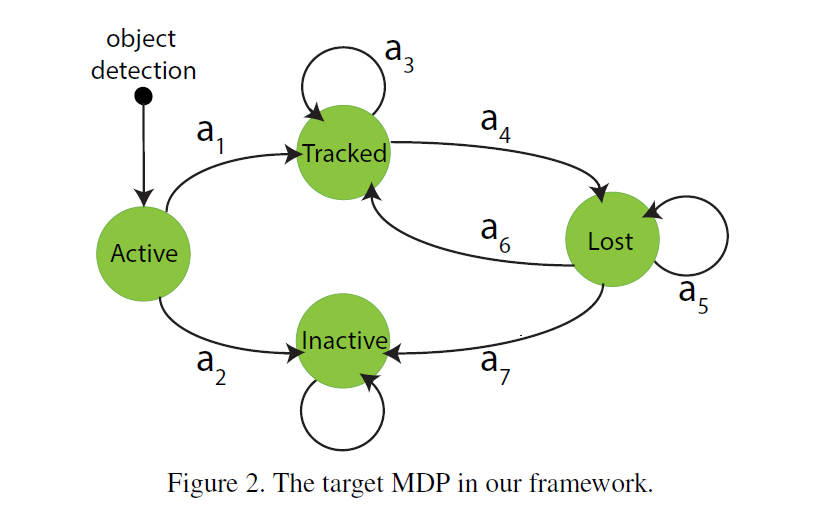
States. 作者将目标 MDP 的状态空间分为 4个子空间,即:$\mathcal{S} = \mathcal{S}_{Active} U \mathcal{S}_{Tracked} U \mathcal{S}_{Lost} U \mathcal{S}_{Inactive}$,每一个子空间包括有限的状态个数,编码依赖于特征表示的目标信息。
各个状态之间的转换也是很有意思的,有点像操作系统中进程的几个状态之间的转换。任何物体的初始状态都是 “Active”,然后该物体可能被跟踪到,即转到“Tracked”,或者没有被激活,就是“Inactive”。被跟踪的物体有可能被跟踪丢失,即:由“Tracked”转到“Lost”。丢失的物体可能重新被发现,即转回到 “Tracked” 状态,或者就此丢失了,或者转为“Inactive”状态。此处需要注意的是:“Inactive” 永远无法被重新跟踪了,即是一种死锁状态。
Actions and Transition Function. 联系各个状态之间的转换,利用的就是 状态转移函数。例如,在跟踪的物体上,执行动作 a4 就会导致状态转向 Lost state, 即:$T(s_{Tracked}, a_4) = s_{Lost}$。
Reward Function.
3.2. Policy:
在MDP当中,一个策略 $\pi$ 是从状态空间 S 到动作空间 A 的一个映射。给定目标的当前状态,该策略可以决定才去哪一个动作。同样的,MDP 当中的策略决定也是按照一定的策略进行的。策略学习的目标就是可以学到一个策略使得最终的总的奖励最大。本节首先讲讲在 Active subspace and the Tracked subspace 的策略设计,然后才是在 Lost subspace 中数据联系的策略。
3.2.1 Policy in an Active State
在一个 Active state s,MDP 决定了关于转移一个物体检测到被跟踪或者 inactive target 来处理噪声检测。策略决定可以看做是tracking 的预处理。像 NMS 或者 阈值化检测得分的策略经常被使用。
3.2.2 Policy in a Tracked State
在一个Tracked state,MDP 需要决定是否要继续跟踪该物体或者将其转换为 lost state。只要该物体没有被遮挡或者说一直在视野当中,那么就要一直保持 tracked state。否则,就要将其标记为:lost。本文采用了单目标跟踪经常使用的 appearance model 来对物体进行跟踪,并且采用了 TLD tracker 来跟踪物体。
Template Representation:
物体的外观可以简单地看做是视频帧上的图像patch,不管何时一个物体检测转化为跟踪目标,我们都用检测的 bounding box 来初始化目标模板。下图给出了一组行人的模板。当物体被跟踪时,MDP 在跟踪地视频帧上收集其模板来表示目标的历史,这个会在 lost state 做决策的时候用到。

Template Tracking.
Template Updating.
3.2.3 Policy in a Lost State.
Data Association.




——内核对象(Kernel object)机制](https://ucc.alicdn.com/pic/developer-ecology/je52eorcpmkr4_ee8fab9f99404b5ebbb79ed16da5ef11.png?x-oss-process=image/resize,h_160,m_lfit)