本文转自:http://www.cosmosshadow.com/ml/%E5%BA%94%E7%94%A8/2015/12/07/%E7%89%A9%E4%BD%93%E6%A3%80%E6%B5%8B.html
Index
RCNN
Rich feature hierarchies for accurate object detection and semantic segmentation
早期,使用窗口扫描进行物体识别,计算量大。
RCNN去掉窗口扫描,用聚类方式,对图像进行分割分组,得到多个侯选框的层次组。
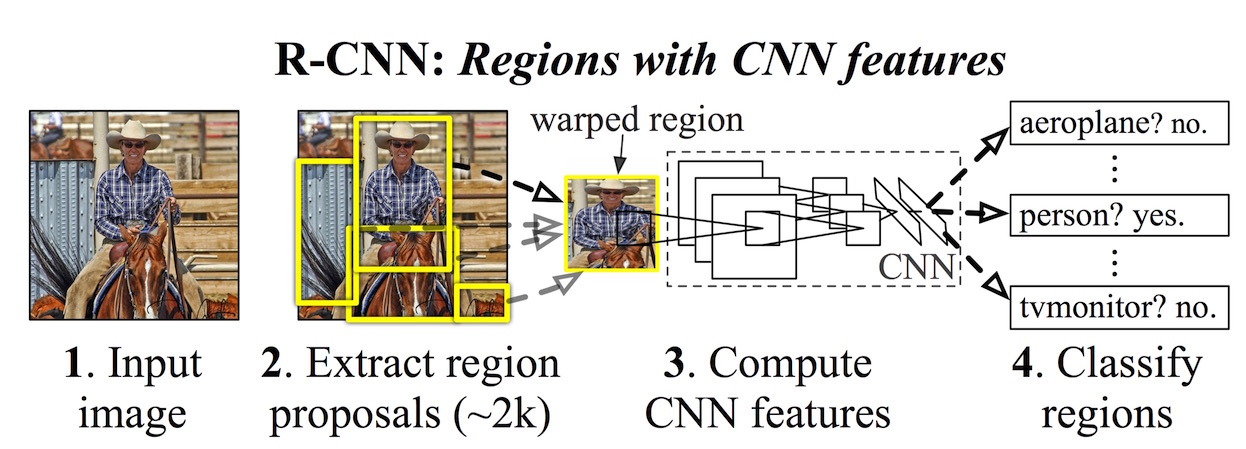
- 原始图片通过Selective Search提取候选框,约有2k个
- 侯选框缩放成固定大小
- 经过CNN
- 经两个全连接后,分类
Fast RCNN
Fast R-CNN
RCNN中有CNN重复计算,Fast RCNN则去掉重复计算,并微调选框位置。
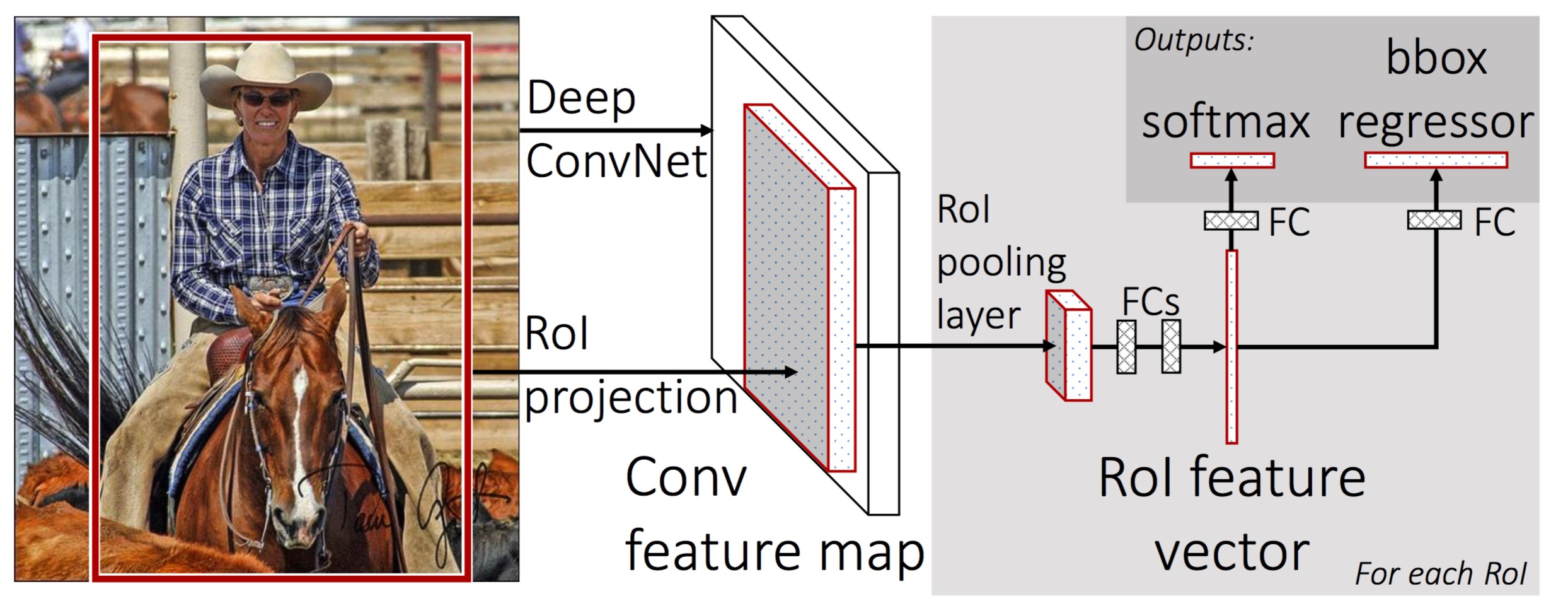
- 整图经过CNN,得到特征图
- 提取域候选框
- 把候选框投影到特征图上,Pooling采样成固定大小
- 经两个全连接后,分类与微调选框位置
Faster RCNN
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
提取候选框运行在CPU上,耗时2s,效率低下。
Faster RCNN使用CNN来预测候选框。
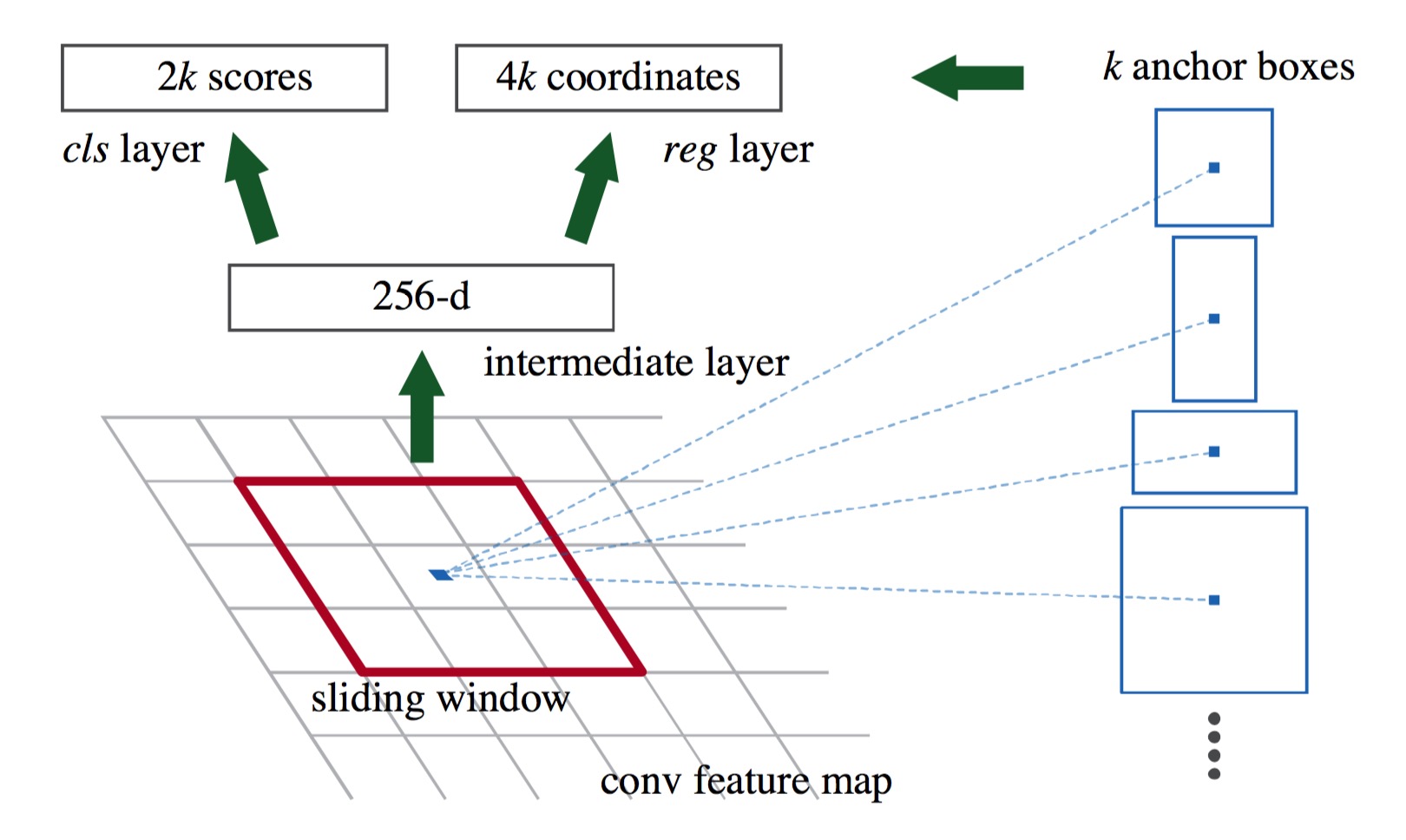
- 整图经过CNN,得到特征图
- 经过核为 3×3×2563×3×256 的卷积,每个点上预测k个anchor box是否是物体,并微调anchor box的位置
- 提取出物体框后,采用Fast RCNN同样的方式,进行分类
- 选框与分类共用一个CNN网络
anchor box的设置应比较好的覆盖到不同大小区域,如下图:

一张1000×6001000×600的图片,大概可以得到20k个anchor box(60×40×960×40×9)。
R-FCN
R-FCN: Object Detection via Region-based Fully Convolutional Networks
RCNN系列(RCNN、Fast RCNN、Faster RCNN)中,网络由两个子CNN构成。在图片分类中,只需一个CNN,效率非常高。所以物体检测是不是也可以只用一个CNN?
图片分类需要兼容形变,而物体检测需要利用形变,如何平衡?
R-FCN利用在CNN的最后进行位置相关的特征pooling来解决以上两个问题。
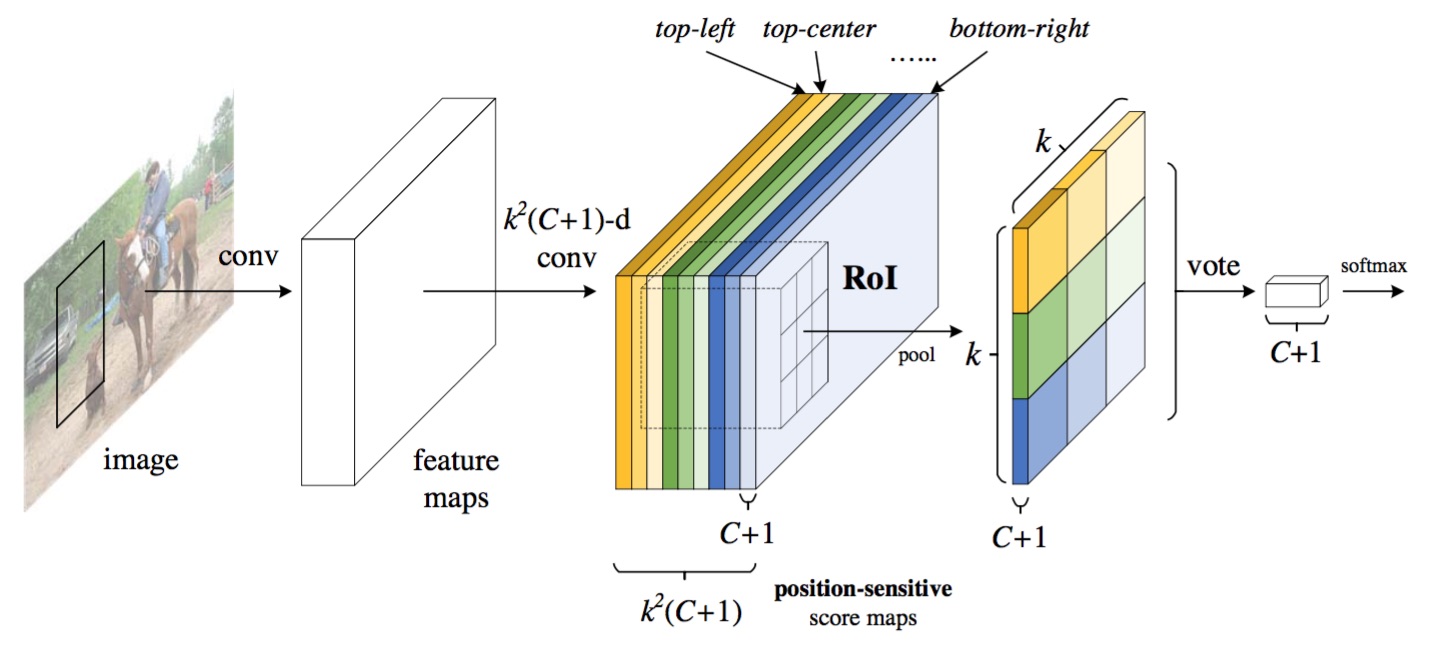
经普通CNN后,做有 k2(C+1)k2(C+1) 个 channel 的卷积,生成位置相关的特征(position-sensitive score maps)。
CC 表示分类数,加 11 表示背景,kk 表示后续要pooling 的大小,所以生成 k2k2 倍的channel,以应对后面的空间pooling。
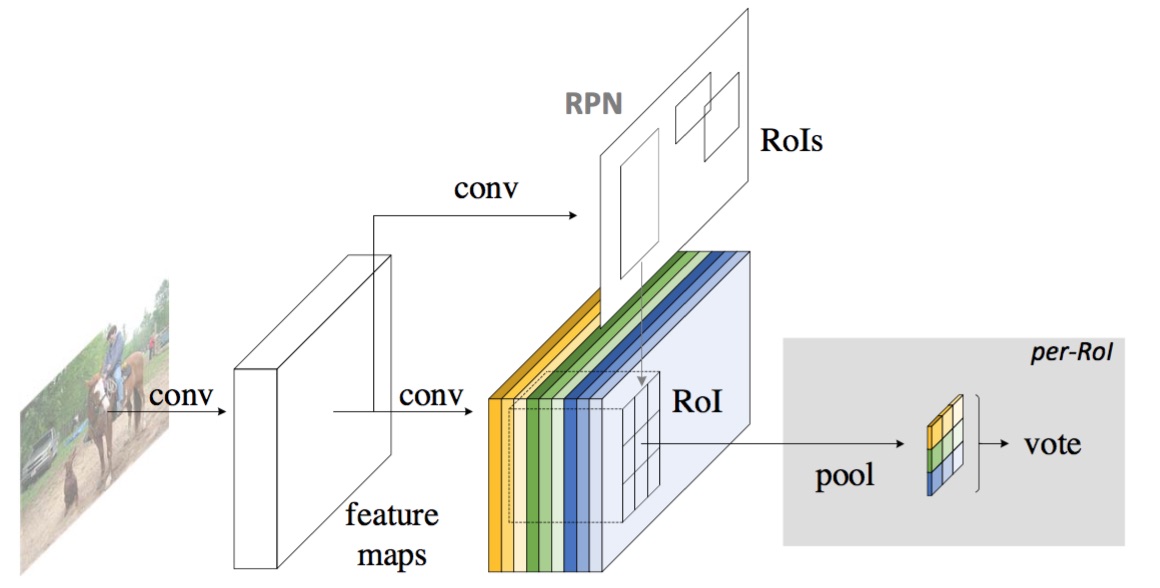
普通CNN后,还有一个RPN(Region Proposal Network),生成候选框。
假设一个候选框大小为 w×hw×h,将它投影在位置相关的特征上,并采用average-pooling的方式生成一个 k×k×k2(C+1)k×k×k2(C+1) 的块(与Fast RCNN一样),再采用空间相关的pooling(k×kk×k平面上每一个点取channel上对应的部分数据),生成 k×k×(C+1)k×k×(C+1)的块,最后再做average-pooling生成 C+1C+1 的块,最后做softmax生成分类概率。
类似的,RPN也可以采用空间pooling的结构,生成一个channel为 4k24k2的特征层。
空间pooling的具体操作可以参考下面。
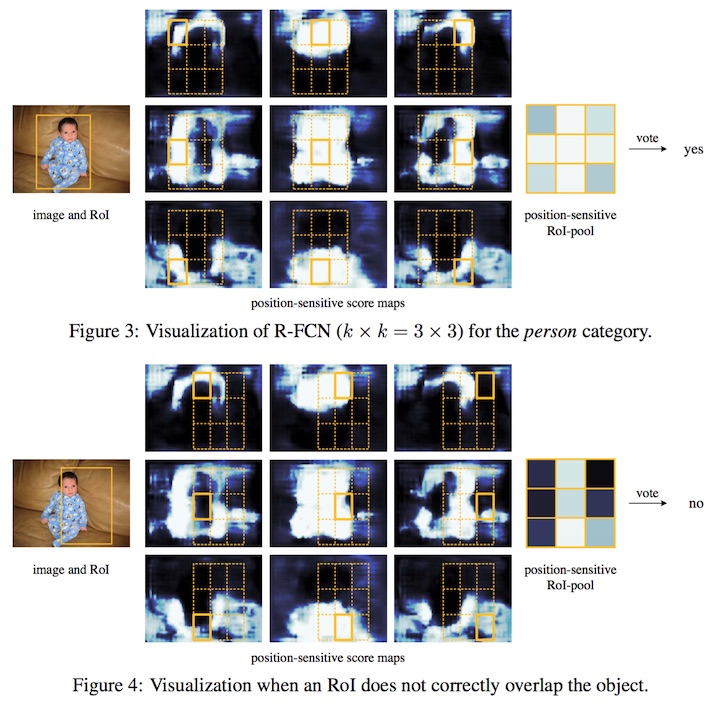
训练与SSD相似,正负点取一个常数,如128。除去正点,剩下的所有使用概率最高的负点。
YOLO
You Only Look Once: Unified, Real-Time Object Detection
Faster RCNN需要对20k个anchor box进行判断是否是物体,然后再进行物体识别,分成了两步。
YOLO则把物体框的选择与识别进行了结合,一步输出,即变成”You Only Look Once”。
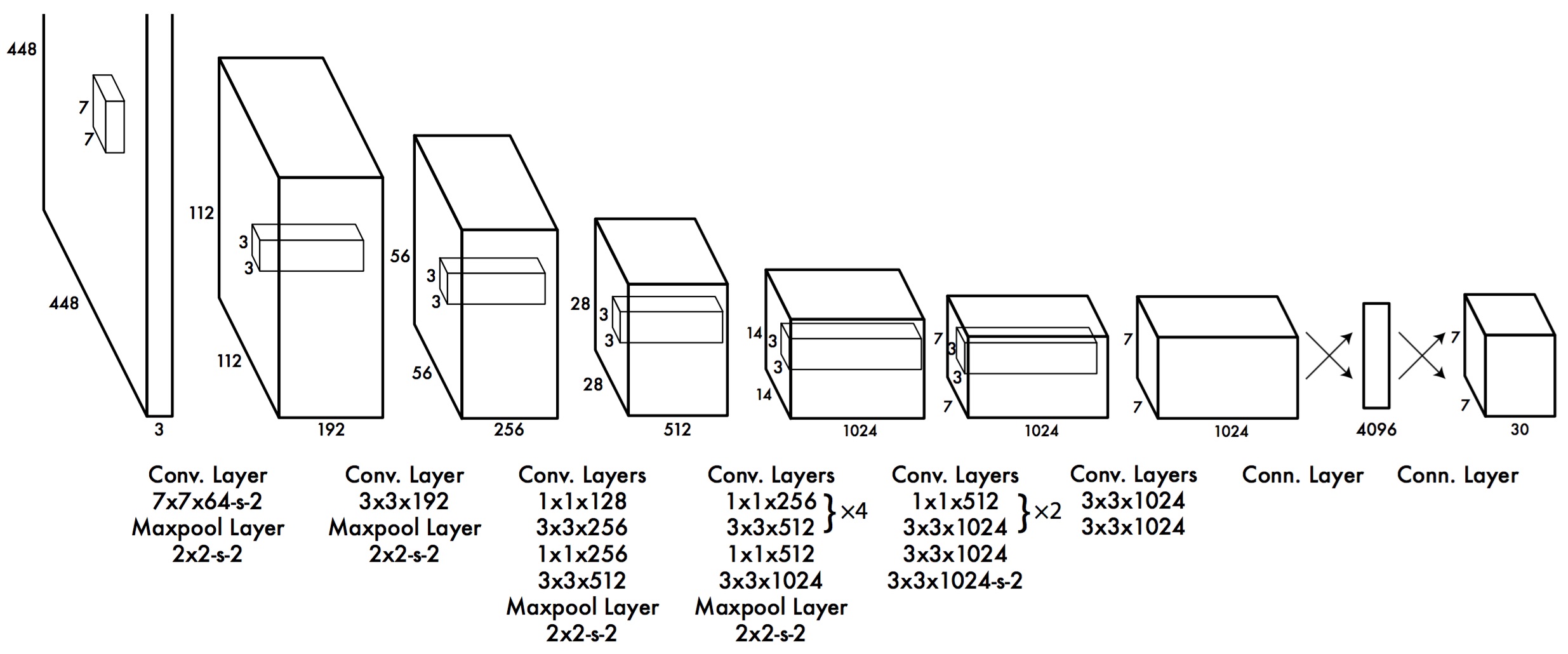
- 把原始图片缩放成448×448448×448大小
- 运行单个CNN
- 计算物体中心是否落入单元格、物体的位置、物体的类别
模型如下:
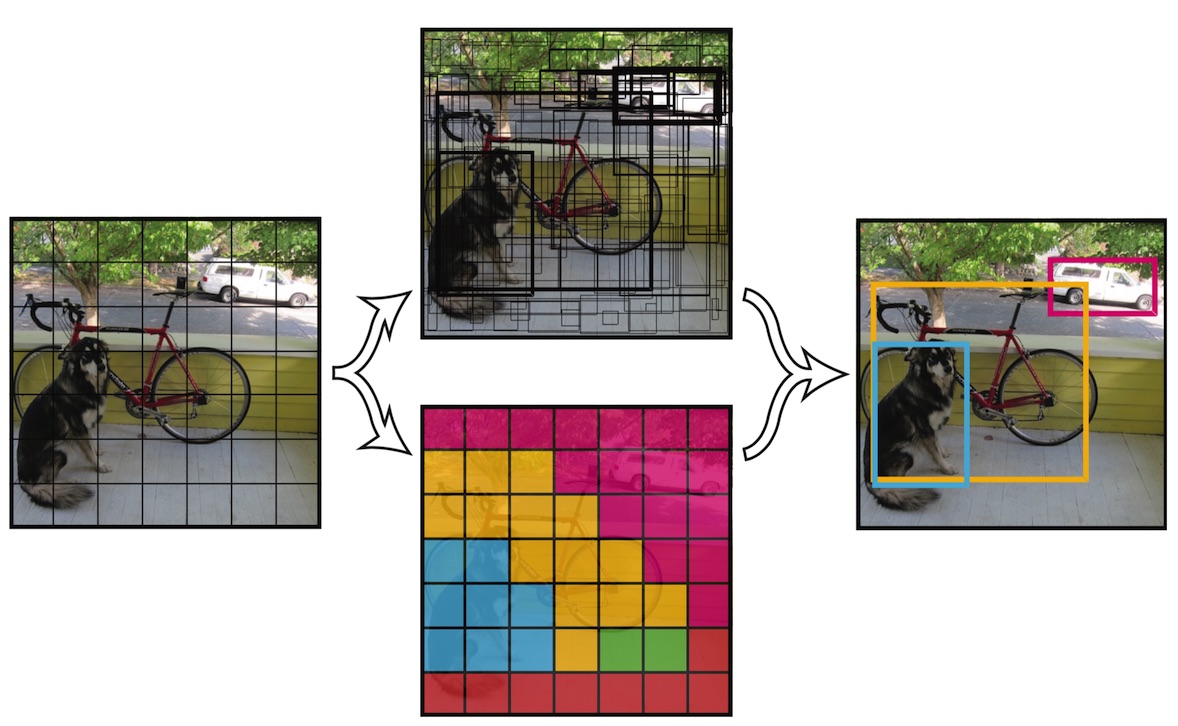
- 把缩放成统一大小的图片分割成S×SS×S的单元格
- 每个单元格输出B个矩形框(冗余设计),包含框的位置信息(x, y, w, h)与物体概率P(Object)P(Object)
- 每个单元格再输出C个类别的条件概率P(Class∣Object)P(Class∣Object)
- 最终输出层应有S×S×(B∗5+C)S×S×(B∗5+C)个单元
- x, y 是每个单元格的相对位置
- w, h 是整图的相对大小
分类的概率
在原论文中,S = 7,B = 2,C = 20,所以输出的单元数为7×7×307×7×30。
代价函数: