Person Re-Identification by Multi-Channel Parts-Based CNN with Improved Triplet Loss Function
CVPR 2016
摘要:跨摄像机的行人再识别仍然是一个具有挑战的问题,特别是摄像机之间没有重叠的观测区域。本文中我们提出一种 多通道 基于part 的卷积神经网络模型,并且结合 改善的三元组损失函数 来进行最终的行人再识别。具体来说,所提出的 CNN 是由多个channel构成的,可以联合的学习 global full-body 和 local body-parts feature of the input persons.
引言:行人在识别依然存在的挑战:
1. 不同摄像机下,剧烈的形变 和 混杂的环境 ;
2. 随着时空变化导致的 行人姿态的剧烈变化 ;
3. 背景的复杂 和 遮挡 ;
4. 不同的个体之间可能共享相似(想死)的外观 ;
此外,脸部的遮挡或者不可见,使得许多生物学的方法并不适应。下图展示了相关的数据集:

给定一张所要找寻的行人图像,在一系列候选中,去寻找,需要解决两个问题:
1. 好的图像特征 来表示 target images 和 candidate images ;
2. 合适的距离度量 不可避免的来确定候选中是否存在 target image 。
现有的方法大部分都集中精力于 第一种思路。当双方的特征都提取完毕后,就开始选择标准的距离度量来决定 image pairs 的相似度。
而本文就着眼于 将这两个独立的阶段,联合的进行处理,即:Joint feature extraction and distance metric learning.
为了更好的学习特征,我们提出一种新的,多通道的 CNN 模型,可以学习到 行人全身 和 部分的特征。然后将这两个特征 concatenate 在一起,输入给网络的 fc 层,最终进行预测。
此外,借助于 三元组损失函数的思想,本文做了稍微的改动,即:
原本的三元组要求:only require the intra-class feature distances to be less than the inter-class ones ;
而改善后损失函数进一步的要求: the intra-class feature distances to be less than a predefined margin.
实验结果表明这个小的改动可以提升将近 4个点 !
本文的所提出的 CNN model 和 改进的三元组损失函数 可以认为是学习一个映射函数,使得能够将原始 raw image 映射成 一个特征空间,该特征空间使得同一个人的图像距离 小于 不同行人的图像距离。所以,所提出的框架,可以学习到最优的特征和距离度量,从而更好的进行行人的在识别任务。
接下来 废话少来,我们先看大致流程框架:
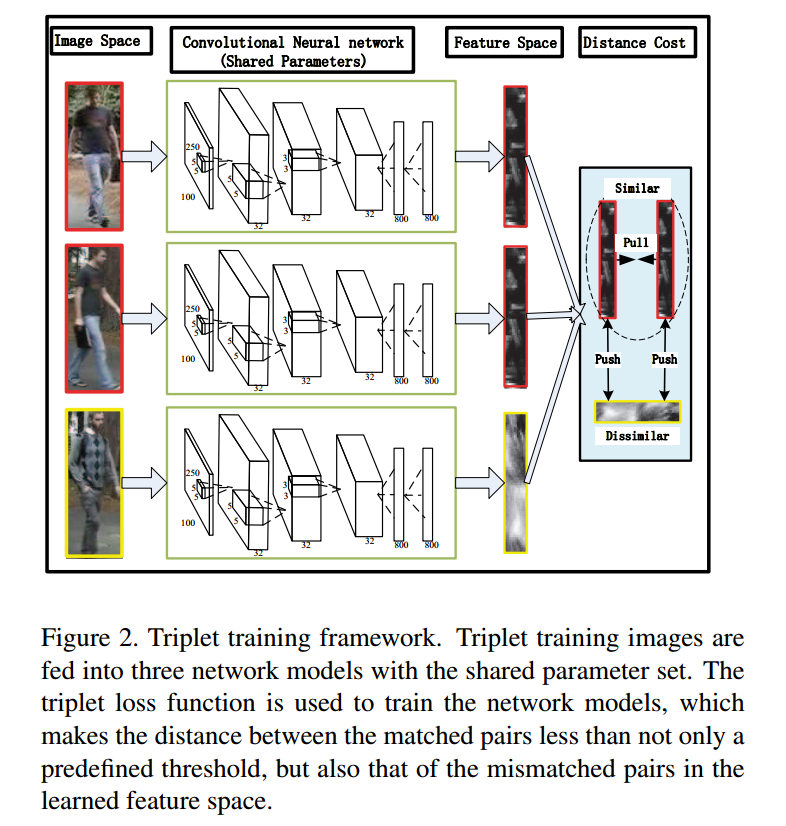
像上图所展示的那样:
本文是用三个网络结构来学习三个图像,这其中有两个相同身份的 human,另一个是 negative images。目标就是使得其中相同的行人之间的距离 小于 不同身份的图像距离。
具体来讲,关于 multi-channel parts-based CNN model 主要体现在以下几点:
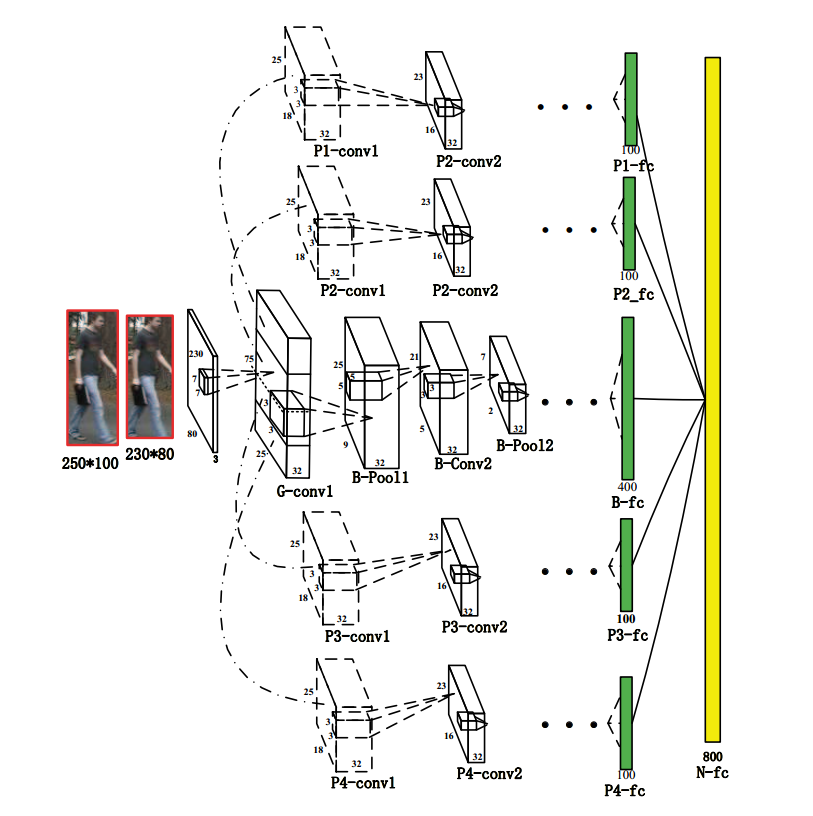
主要是由以下几个 layer 构成的:
1. one global convolutional layer ;
2. one full-body convolution layer ;
3. four body-part convolutional layers ;
4. five channel-wise full connection layers ;
5. one network-wise full connection layer.
看起来很复杂的一个网络结构,被细分为这几个分支之后,就显得不那么复杂了,但是却取得了不错的效果。因为这种网络结构很暴力啊,感觉,这种细分到 part 的网络结构,如果不是自动定位的 part,那么就会显得非常的不智能。
然后,就是改善的三元组损失函数了。
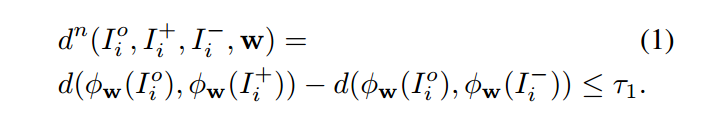
但是,这个损失函数并没有显示的表示:target image 和 positive image 之间的距离应该有多近。所造成的一个结果,就可能是:属于同一个行人的 instance 可能构成一个大的 cluster,并且有一个较大的 intra-class distance in the learned feature space. 明显的是,并没有一个需要的输出,这不可避免的会损害再识别的性能。
基于以上观察,我们做了相应的改进。我们添加了相应的新的损失函数来增强约束。target image 和 positive image 之间的距离应该小于一个阈值 $\tau_2$, 并且这个阈值应该小于 $\tau_1$。
这个改进的损失函数进一步的拉近了同一个human之间的距离,并且拉远了 不同行人之间的距离。
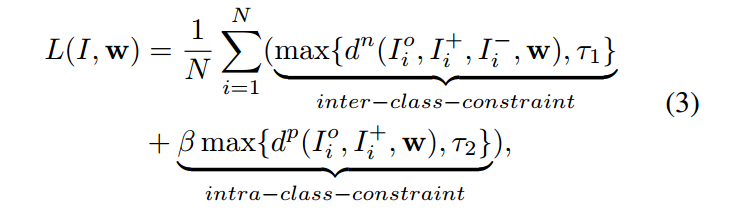
其中,N 是triplet训练样本的个数,$\beta$ 平衡了类别内部 和 类别之间 的约束。距离函数 d(. , .) 是 L2-norm distance.
训练算法:

总结:
总体来说,感觉还是比较暴力的解决方案。一方面来说,文章提出了一种利用 human part 和 global body 进行精细化识别的框架来提供更加有效的 feature。另一方面,改善了三元组损失函数,使得最终的训练更加有效。 这是本文中,两个最重要的创新点。
但是,对于行人 part 的定位文章并未做详细描述,估计是靠手工标注来完成的。那么,这个就有点 low 了。。。