Deep Recurrent Q-Learning for Partially Observable MDPs
摘要:DQN 的两个缺陷,分别是:limited memory 和 rely on being able to perceive the complete game screen at each decision point.
为了解决这两个问题,本文尝试用 LSTM 单元 替换到后面的 fc layer,这样就产生了 Deep Recurrent Q-Network (DRQN),虽然每一个时间步骤仅仅能看到一张图像,仍然成功的结合了相关信息,在Atari games 和 partically observed equivalents feature flikering game screens,得到了 DQN 相当的效果。另外,当用部分观测进行训练,并且用逐渐增加的完整的观测时,DRQN 的性能和观测成一定的函数关系。相反的,当用全屏进行训练的时候,用部分观测进行评估,但是DRQN 的性能却比 DQN 的效果要差。所以,给定同样长度的历史,recurrency 是一种实际可行的方法来存储 DQN 的输入层的历史。
引言:开头讲了 DQN 取得的成功,后面开始说他的两个弱点,使得 MDP问题逐渐变成了 部分观测的马尔科夫决策过程(partically-observable markov decision process)。
像下图所展示的那样,仅仅给定一帧图像,许多游戏就变成了 POMDPs。一个例子就是,我们只能知道这个球的位置,但是无法得知其速度。但是知道球的运动方向是非常重要的,因为这将会决定最优的踏板的位置。

我们观测到 DQN 的性能在给定不完全的状态观测时,性能就会下降。我们假设 DQN 可以被改善的能够处理 POMDPs,通过引入 RNN 的 advances 。 所以,我们引入了 Deep Recurrent Q-Network (DRQN),组合了 LSTM 和 Deep Q-network。关键的是,我们表明 DRQN 能够处理部分观测的情况,and that recurrency confers benefits when the quality of observations change during evaluation time .
Deep Q-learning 的简介(略)
Partical Observability :
在真实世界的环境中,很少有 full state of the system 可以提供给 agent 。换句话说,马尔科夫属性在这样的环境中,几乎不成立 。部分观测的 MDPs 可以更好的抓住环境的动态,通过显示的认识到:agent 接受到的感知都是潜在系统状态的部分glimpse (only partical glimpses of the underlying system state)。形式上来说,POMDP 可以表达为 6个变量:
(S, A, P, R, X, O). 假设这几个变量分别为:状态,动作,转移函数,奖励,X 表示真实的环境,但是agent 只能感知其部分信息 o 。
在一般情况下,预测一个 Q-value 可能是不准确的,是因为: $Q(o, a|\theta) != Q(s, a|\theta)$ 。
我们的实验表明,添加了 recurrency 到 DQN 当中,允许 Q-network 能够更好的预测潜在的系统状态,缩小上述不等式两者之间的差距。从而更加准确的预测 Q values ,进一步的提升学习到的策略。
DRQN Architecture:
像图 2 所示的那样,DRQN 的结构是将 DQN 上的 第一个 fc layer 替换成了 LSTM 单元。
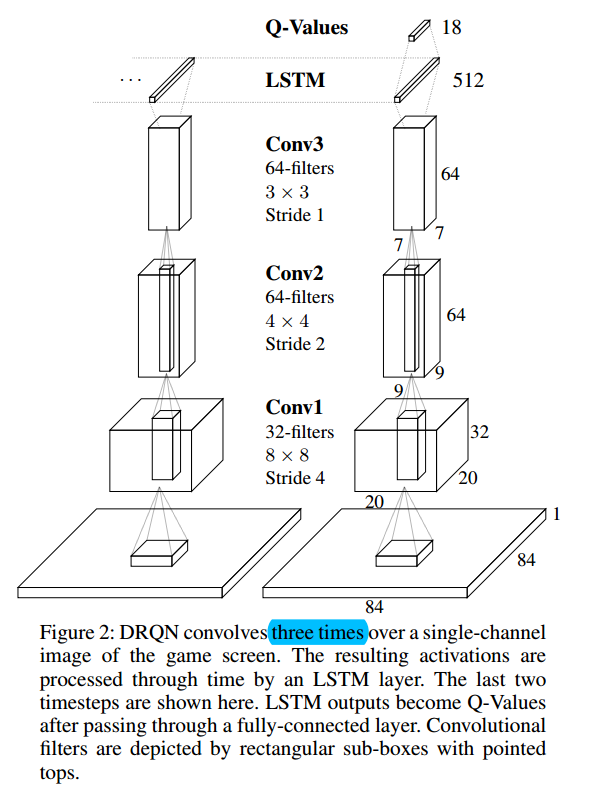
对于输入来说,Recurrent network 输入一张 84*84 的图像。