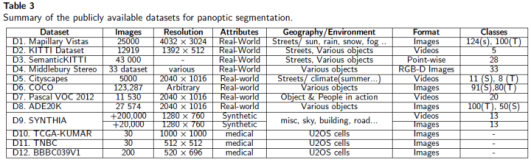
常见图像和视频分割方法概述
图像与视频分割是指按照一定的原则将图像或视频序列分为若干个特定的、具有独特性质的部分或子集,并提取出感兴趣的目标,便于更高层次的分析和理解,因此图像与视频分割是目标特征提取、识别与跟踪的基础。
1)、基于边缘的分割方法
2)、基于阈值的分割方法
3)、基于区域的分割方法
4)、基于形态学分水岭的分割方法
5)、基于聚类的分割方法
6)、基于图论的分割方法
7)、基于偏微分的分割方法
8)、基于融合的分割方法
视频分割方法主要包括:
9)、基于时域的视频对象分割方法
10)、基于运动的视频对象分割方法
11)、交互式视频对象分割方法
接下来,分别对上面提及的图像与视频分割方法做简单概述。
一、基于边缘的分割方法
理论基础:图像的边缘是图像的最基本特征,是图像局部特性不连续(突变)的结果,是不同区域的分界处,因此它是图像分割所依赖的重要特征。
基本思想:通过搜索不同区域之间的边界,来完成图像的分割。
具体做法:首先利用合适的边缘检测算子(通常用求导数方法来检测,一般采用一阶导数和二阶导数检测边缘)提取出待分割场景不同区域的边界,然后对边界内的像素进行连通和标注,从而构成分割区域。
常见的边缘检测算子有一阶微分算子和二阶微分算子。Prewitt、Roberts、Sobel是基于一阶导数的边缘检测算子,Laplacian和LOG是基于二阶导数的边缘检测算子,检测方法是采用小区域模板与图像做卷积运算求导数,然后选取合适的阈值提取边缘,这些边缘检测算子的区别主要在于所采用的模板和元素系数的不同。目前最常用的边缘检测算子是Kirsch算子、LOG(Laplacian-Gauss)算子和Canny算子。
基于边缘的分割方法的关键在于边缘检测算子的选取。
二、基于阈值的分割方法
理论基础:目标或背景内部的相邻像素间灰度值是相似的,但是不同目标或背景上像素灰度差异较大,反映在直方图上就是不同目标或背景对应不同的峰,分割时,选取的阈值应位于直方图两个不同峰之间的谷上,以便将各个峰分开。
基本思想:通过阈值来定义图像中不同目标的区域归属。
具体做法:首先在图像的灰度取值范围内选择一灰度阈值,然后将图像中的各个像素的灰度值与这个阈值相比较,并根据比较的结果将图像中的像素划分到两类中,若图像中有多个灰度值不同的区域,那么可以选择一系列的阈值以便将每一个像素分到合适的类别中去。
目前有多种阈值选择方法,依照阈值的应用范围可将阈值分割方法分为全局阈值法、局部阈值法和动态阈值法三大类。
基于阈值的分割方法的关键在于灰度图阈值大小的选取。
三、基于区域的分割方法
理论基础:与“基于阈值的分割方法”的理论基础基本一致,都是利用同一物体区域内像素灰度的相似性。
基本思想:将灰度相似的区域合并,把不相似的区域分开,最终形成不同的分割区域。
具体做法:利用同一物体区域内像素灰度的相似性,将灰度相似的区域合并,把不相似的区域分开,最终形成不同的分割区域。
常见的区域分割方法有区域生长法、分裂合并法等。
种子区域生长法是从一组代表不同生长区域的种子像素开始,接下来将种子像素邻域里符合条件的像素合并到种子像素所代表的生长区域中,并将新添加的像素作为新的种子像素继续合并过程,直到找不到符合条件的新像素为止。该方法的关键是选择合适的初始种子像素以及合理的生长准则。
区域分裂合并法(Gonzalez,2002)的基本思想是首先将图像任意分成若干互不相交的区域,然后再按照相关准则对这些区域进行分裂或者合并从而完成分割任务,该方法既适用于灰度图像分割也适用于纹理图像分割。
四、基于形态学分水岭的分割方法
理论基础:分水岭分割(Watershed)法(Meyer,1990)是一种基于拓扑理论的数学形态学的分割方法。
基本思想:把图像看作是测地学上的拓扑地貌,图像中每一点像素的灰度值表示该点的海拔高度,每一个局部极小值及其影响区域称为集水盆,而集水盆的边界则形成分水岭。
具体做法:该算法的实现可以模拟成洪水淹没的过程,图像的最低点首先被淹没,然后水逐渐淹没整个山谷。当水位到达一定高度的时候将会溢出,这时在水溢出的地方修建堤坝,重复这个过程直到整个图像上的点全部被淹没,这时所建立的一系列堤坝就成为分开各个盆地的分水岭。
分水岭算法对微弱的边缘有着良好的响应,但图像中的噪声会使分水岭算法产生过分割的现象。
五、基于聚类的分割方法
理论基础:图像分割就是图像中的像素进行分类。
基本思想:图像分割就是将图像的像素进行分类,于是,很自然的将聚类应用于图像分割问题中。
具体做法:给出一个目标函数,使得聚类过程中,目标函数达到最小为止。
目前常见的基于聚类的分割方法主要有:C-均值聚类分割算法(HCM)、模糊C-均值聚类分割算法(FCM)。FCM聚类是HCM的改进,其区别主要在于:HCM算法对于对象的划分是硬性的,而FCM则是一种柔性的模糊划分;FCM模糊聚类算法的向量可以同时属于多个聚类,用0~1间的隶属度来确定每个对象属于各个类的程度,而HCM聚类算法中,一个给定的对象只能属于一个类。
六、基于图论的分割方法
理论基础:图论中无向图的最优化问题。
基本思想:将图像映射为带权无向图,将像素点当作图的节点,利用最小剪切准则得到图像的最佳分割,即:把图像分割问题转化为一个无向图G=(V,E)的最优化问题。
具体做法:无向图中的节点表示图像中的像素,节点与节点之间的边表示像素之间的关系,根据一定的规则为每条边赋予一个权值,利用一定的最优化准则使分割结果中区域内的边有较低的权值,区域间的边有较高的权值,即区域之间的代价函数最小的划分便是该图最优的分割。
基于图论分割的基本原则是使划分成的两个区域(A,B)的内部相似度最大,区域(A,B)之间的相似度最小,同时应使得划分的区域尽量避免出现歪斜分割。为了能够得到精确的分割结果,设计割集准则至关重要,常见的割集准则有Minimum Cut、Average Cut、Normalize Cut、Min-max Cut、Ratio Cut等。
七、基于偏微分的分割方法
理论基础:偏微分方程在图像分割领域的应用。
基本思想:该类方法主要指的是活动轮廓模型(active contour model)以及在其基础上发展出来的算法,其基本思想是使用连续曲线来表达目标边缘,并定义一个能量泛函使得其自变量包括边缘曲线,因此分割过程就转变为求解能量泛函的最小值的过程,一般可通过求解函数对应的欧拉(Euler.Lagrange)方程来实现,能量达到最小时的曲线位置就是目标的轮廓所在。
具体做法:该模型是一种基于能量的图像分割方法,其能量函数为基于曲线的内部能量和基于图像数据外部能量的加权和,通过极小化该能量泛函使得待分割目标周围的一条初始曲线在固有内力和图像外力的共同作用下不断演化,最终收敛到目标的边界轮廓。
按照模型中曲线表达形式的不同,活动轮廓模型可以分为两大类:参数活动轮廓模型(parametric active contour model)和几何活动轮廓模型(geometric active contour model)。
注:活动轮廓模型又称为Snakes分割方法。
参数活动轮廓模型是基于Lagrange框架,直接以曲线的参数化形式来表达曲线,最具代表性的是由Kasseta1(1987)所提出的Snake模型。该类模型在早期的生物图像分割领域得到了成功的应用,但其存在着分割结果受初始轮廓的设置影响较大以及难以处理曲线拓扑结构变化等缺点,此外其能量泛函只依赖于曲线参数的选择,与物体的几何形状无关,这也限制了其进一步的应用。
几何活动轮廓模型的曲线运动过程是基于曲线的几何度量参数而非曲线的表达参数,因此可以较好地处理拓扑结构的变化,并可以解决参数活动轮廓模型难以解决的问题。而水平集(Level Set)方法(Osher,1988)的引入,则极大地推动了几何活动轮廓模型的发展,因此几何活动轮廓模型一般也可被称为水平集方法。
八、基于融合的分割方法
理论基础:多特征更能精确地描述一个物体的特征。
基本思想:采用纹理和灰度两种特征对图像进行描述,并通过动态融合的策略生成一张综合特征图,使之更能准确的反映图像信息,有利于进行后续的图像分割过程。
具体做法:第一阶段为特征提取部分,用纹理和灰度来描述一副输入图像;第二阶段为综合特征图像融合,将不同特征的特征图融合成一张综合的特征图;第三阶段为图像分割过程,根据综合特征图进行图像分割。
多特征动态融合的图像分割主要是针对目标的纹理比背景复杂,目标的亮度比背景高这种类型的灰度图像,采用纹理和灰度两种特征对图像进行描述,并通过动态融合的策略生成一张综合特征图,使之更能准确的反映图像信息,有利于进行后续的图像分割过程。
九、基于时域的视频对象分割方法
理论基础:同一物体的各部分往往具有一致的时间属性。
基本思想:时域分割主要是利用视频图像相邻之间的连续性和相关性进行分割。
具体做法:一种是通过当前帧和背景帧相减来获得差分图像,另外一种是利用两帧之间或者多帧之间的差来获得差分图像。
基于时域的视频对象分割方法主要包括:背景差分法、帧间差分法。
十、基于运动的视频对象分割方法
理论基础:光流场与参数估计方面的理论知识。
基本思想:主要是基于光流场等方法进行运动参数估计,求出符合运动模型的像素区域,进而合并区域构成运动对象进行视频分割。
具体做法:首先求出光流场并进行参数估计,接着求出符合运动模型的像素区域,最后合并区域构成运动对象进行视频分割。
基于运动的视频对象分割方法主要包括:光流法、参数化方法。
【补充小知识】:当人的眼睛与被观察的物体发生相对运动时,物体的影像在视网膜平面上形成一系列连续变化的图像,这一系列的图像信息不断“流过”视网膜,好像是一种光的“流”,所以被称为“光流”。光流是基于像素定义的,所有的光流的集合称为光流场。
十一、交互式视频对象分割方法
理论基础:人工监督与用户交互。
基本思想:交互式分割中,用户通过图形用户界面对视频图像进行初始分割,然后对后继帧利用基于运动和空间的信息进行分割。
具体做法:第一步是用户通过鼠标描绘出视频分割的大致轮廓,第二步再利用视频分割算法进行视频分割。
基于交互式视频对象分割方法主要包括:按被分割对象的性质进行跟踪;基于变化检测的方法;基于形态学算法的交互式视频分割方法等。在不要求实时性但是对视频边界分割精度要求较高的场合,交互式分割法的效果比较好。这种方法主要用于节目制作等应用,对于实时应用场合如视频会议则无能为力。