Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
2016.10.23
摘要:本文针对传统超分辨方法中存在的结果过于平滑的问题,提出了结合最新的对抗网络的方法,得到了不错的效果。并且针对此网络结构,构建了自己的感知损失函数。先上一张图,展示下强大的结果:

Contributions:
GANs 提供了强大的框架来产生高质量的 plausible-looking natural images。本文提供了一个 very deep ResNet architure,利用 GANs 的概念,来形成一个 perceptual loss function 来靠近 human perception 来做 photo-realistic SISR。
主要贡献在于:
1. 对于 image SR 来说,我们取得了新的顶尖效果,降低 4倍的分辨率,衡量标准为:PSNR 和 structure similarity (SSIM)。具体的来说,我们首先采用 fast feature learning in LR space and batch-normalization 来进行训练残差网络。
2. 提出了结合 content loss 和 adversarial loss 作为我们的 perceptual loss。
Method:
首先是几个概念:
super solved image $I_{SR}$: W * H * C ; low-resolution input image $I_{LR}$: rW * rH * C ; high-resolution image $I_{HR}$ : rW * rH * C.
我们的终极目标是:训练一个产生式函数 G 能够预测给定的输入图像 LR input image 的 HR 部分。我们达到这个目的,我们训练一个 generator network 作为一个 feed-forward CNN $G_{\theta_{G}}$ 参数为 $\theta_{G}$ , 此处的 $\theta_{G} = {W_{1:L} ; b_{1:L}}$ 表示一个 L 层 deep network 的 weights 和 biases,并且是通过优化一个 SR-specific loss function $l^{SR}$ 得到的。对于一个给定的 训练图像 $I^{HR_{n}}$ ,n = 1,...,N 对应的低分辨率图像为:$I^{LR}_n$ ,我们优化下面这个问题:
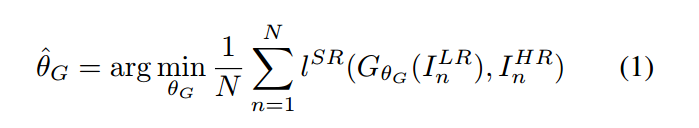
1. Adversarial Network Architecture
产生式对抗网络的训练学习目标是一个 minmax problem :
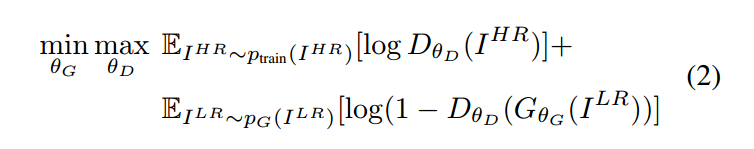
作者也将图像超分辨看作是这么一个过程。通过 generator 产生一张超分辨图像,使得 discriminator 难以区分。
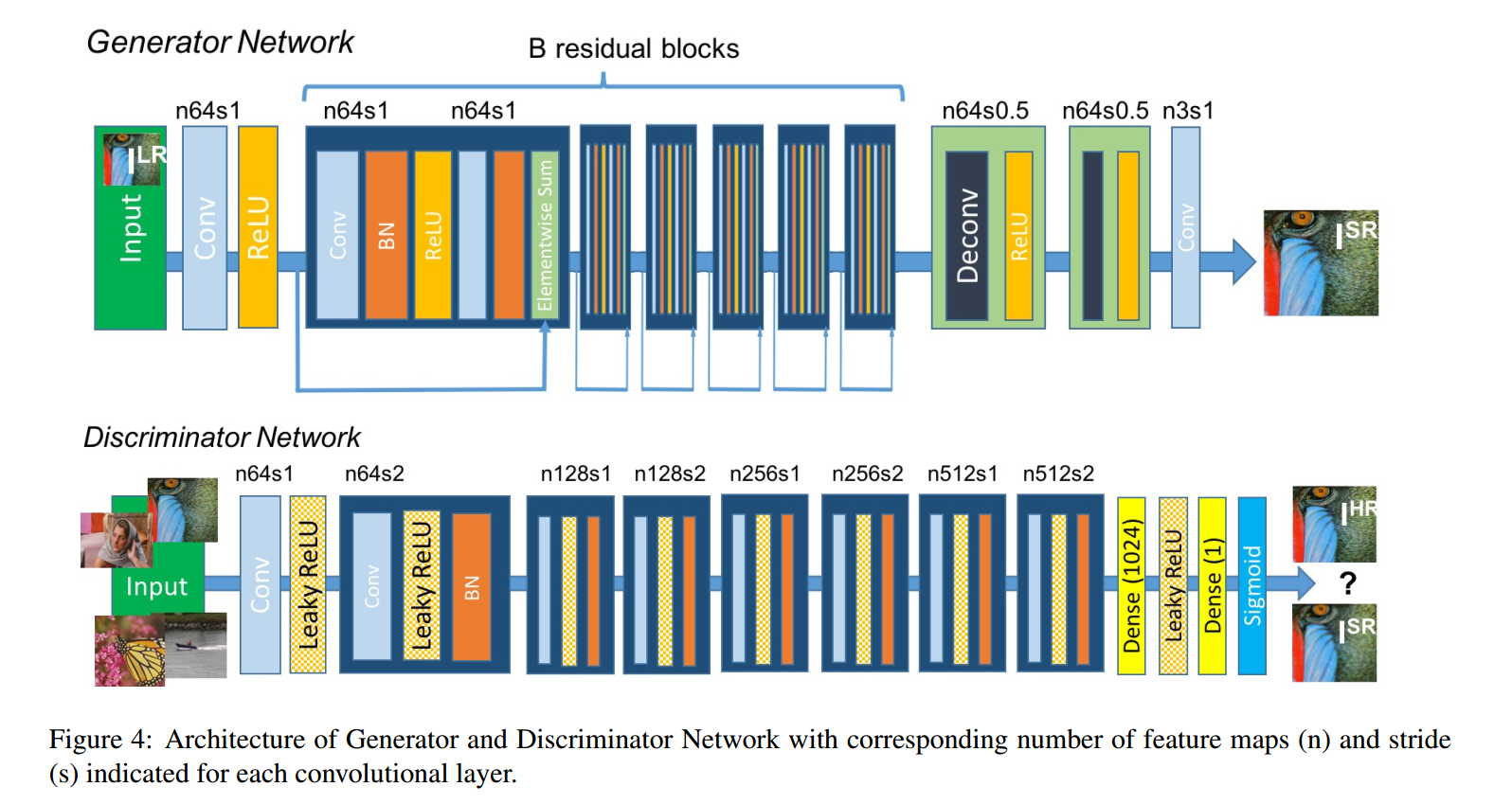
上图就是本文所涉及的大致流程。
2. Perceptual Loss Function
本文所设计的感知损失函数 是本文算法性能的保证。
2.1. Content Loss
像素级 MSE Loss 的计算为:
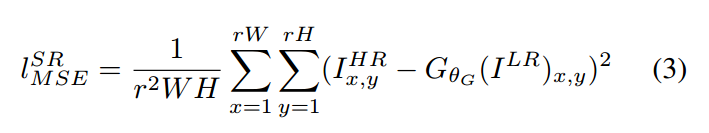
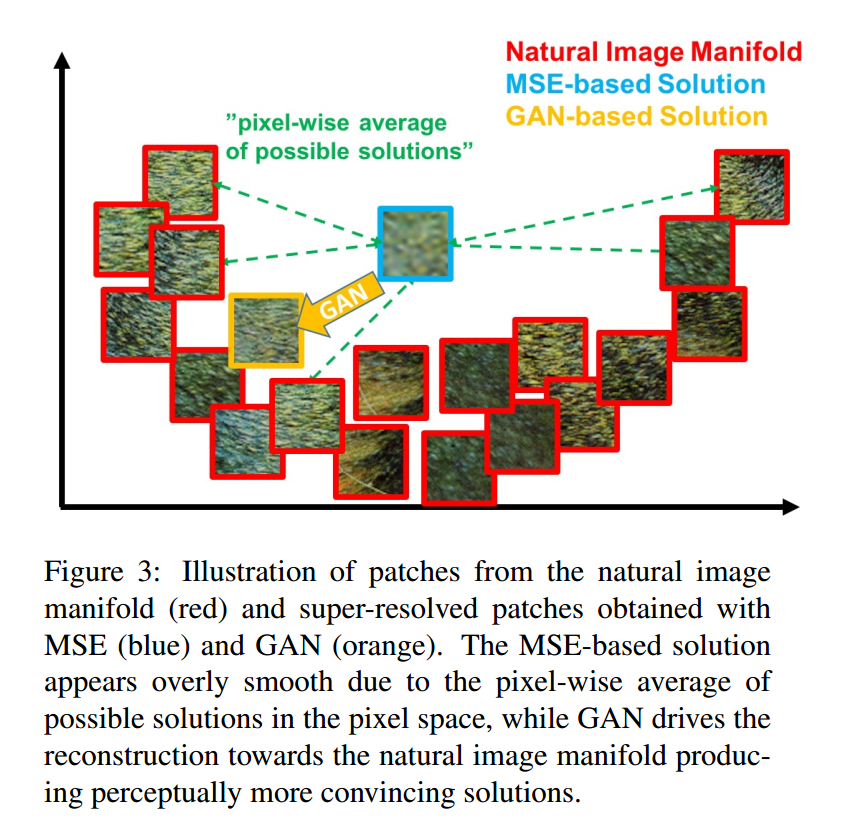
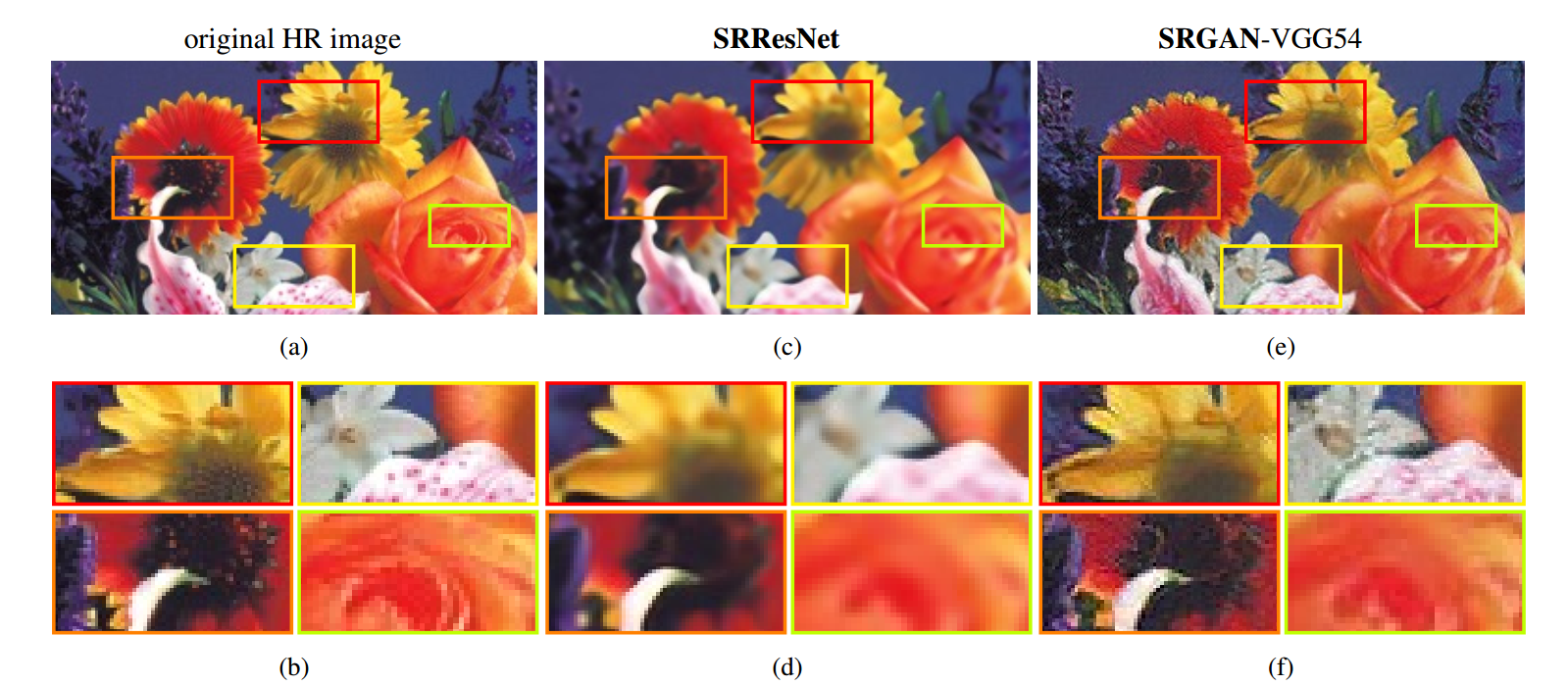
这个是最经常使用的优化目标。但是,这种方式当取得较高的 PSNR的同时,MSE 优化问题导致缺乏 high-frequency content,这就会使得结果太过于平滑(overly smooth solutions)。如图2 所示:

我们对此做了改进,在 pre-trained 19-layer VGG network 的 ReLU activation layers 的基础上,定义了 VGG loss 。
我们用 $\phi_{i,j}$ 表示 VGG19 network 当中,第 i-th max pooling layer 后的 第 j-th 卷积得到的 feature map。然后定义 the VGG loss 作为重构图像 和 参考图像之间的欧氏距离 :
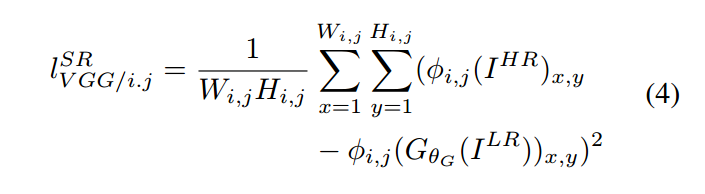
其中,$W_{i, j}$ and $H_{i, j}$ 表示了 VGG network 当中相应的 feature maps 的维度。
2.2. Adversarial Loss
在所有训练样本上,基于判别器的概率定义 generative loss :
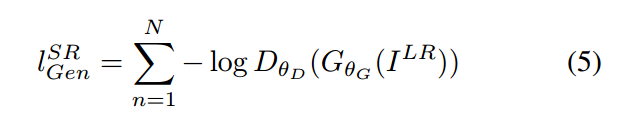
此处,D 是重构图像是 natural HR image 的概率。
2.3. Regulatization Loss
我们进一步的采用 基于 total variation 的正则化项 来鼓励 spatially coherent solutions。正则化损失的定义为:
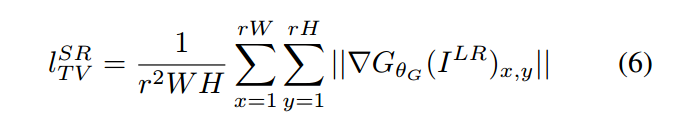
3. Experiments


总结 : 本文给出了一种比较直观的利用 产生式对抗网络的方法,结合 GANs 的比较好的应用到 Super-Resolution 上。
主要是利用了 GANs 可以创造新的图像的能力。