Tutorials on training the Skip-thoughts vectors for features extraction of sentence.
1. Send emails and download the training dataset.
the dataset used in skip_thoughts vectors is from [BookCorpus]: http://yknzhu.wixsite.com/mbweb
first, you should send a email to the auther of this paper and ask for the link of this dataset. Then you will download the following files:

unzip these files in the current folders.
2. Open and download the tensorflow version code.
Do as the following links: https://github.com/tensorflow/models/tree/master/skip_thoughts
Then, you will see the processing as follows:

[Attention] when you install the bazel, you need to install this software, but do not update it. Or, it may shown you some errors in the following operations.
3. Encoding Sentences :
(1). First, open a terminal and input "ipython" :
(2). input the following code to the terminal:
ipython # Launch iPython.
In [0]:
# Imports.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
import os.path
import scipy.spatial.distance as sd
from skip_thoughts import configuration
from skip_thoughts import encoder_manager
In [1]:
# Set paths to the model.
VOCAB_FILE = "/path/to/vocab.txt"
EMBEDDING_MATRIX_FILE = "/path/to/embeddings.npy"
CHECKPOINT_PATH = "/path/to/model.ckpt-9999"
# The following directory should contain files rt-polarity.neg and
# rt-polarity.pos.
For this moment, you already defined the environment, then, you need also do the followings:
In [2]:
# Set up the encoder. Here we are using a single unidirectional model.
# To use a bidirectional model as well, call load_model() again with
# configuration.model_config(bidirectional_encoder=True) and paths to the
# bidirectional model's files. The encoder will use the concatenation of
# all loaded models.
encoder = encoder_manager.EncoderManager()
encoder.load_model(configuration.model_config(),
vocabulary_file=VOCAB_FILE,
embedding_matrix_file=EMBEDDING_MATRIX_FILE,
checkpoint_path=CHECKPOINT_PATH)
In [3]:
# Load the movie review dataset.
data = [' This is my first attempt to the tensorflow version skip_thought_vectors ... ']
The, it's time to get the 2400# features now.
In [4]:
# Generate Skip-Thought Vectors for each sentence in the dataset.
encodings = encoder.encode(data)
print(encodings)
print(encodings[0])
You can see the results of the algorithm as followings:
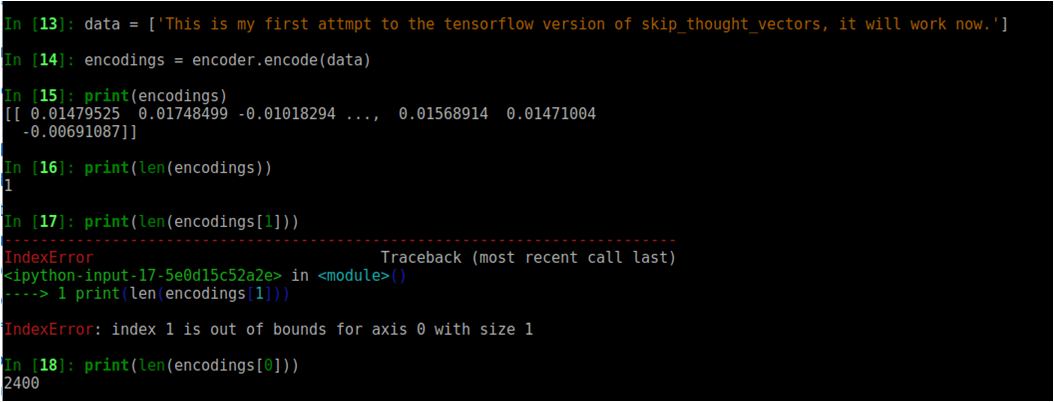
Now that, you have obtain the features of the input sentence. you can now load your texts to obtain the results. Come on ...

![[GloVe]论文实现:GloVe: Global Vectors for Word Representation*](https://ucc.alicdn.com/pic/developer-ecology/w2a72w4omzoyy_c4f51f904bca49c386ed332289102e05.jpg?x-oss-process=image/resize,h_160,m_lfit)