Collaborative Deep Reinforcement Learning for Joint Object Search
CVPR 2017
Motivation:
传统的 bottom-up object region proposals 的方法,由于提取了较多的 proposal,导致后续计算必须依赖于抢的计算能力,如 GPU 等。那么,在计算机不足的情况下,则会导致应用范围受限。而 Active search method (就是 RL 的方法) 则提供了不错的方法,可以很大程度上降低需要评估的 proposal 数量。

我们检查了在交互过程中,多个物体之间的 Joint Active Search 的问题。
On the one hand, it is interesting to consider such a collabrative detection "game" played by multiple agents under an RL setting;
On the other hand, it seems especially beneficial in the context of visual object localization where different objects often appear with certain correlation patterns, 如:行人骑自行车,座子上的杯子,等等。
这些物体在交互的情况下,可以提供更多的 contextual cues 。这些线索有很好的潜力来促进更加有效的搜索策略。
本文提出一种协助的多智能体 deep RL algorithm 来学习进行联合物体定位的最优策略。我们的 proposal 服从现有的 RL 框架,但是允许多个智能体之间进行协作。在这个领域当中,有两个开放的问题:
1. how to make communications effective in between different agents ;
2. how to jointly learn good policies for all agents.
本文提出通过 gated cross connections between the Q-networks 来学习 inter-agent communication。
所提出的创新点:
1. 是物体检测领域的第一个做 collaborative deep RL algorithm ;
2. propose a novel multi-agent Q-learning solution that facilitates learnable inter-agent communication with gated cross connections between the Q-networks;
3. 本文方法有效的探索了 相关物体之间有用的 contextual information,并且进一步的提升了检测的效果。
3. Collaborative RL for Joint Object Search
3.1. Single Agent RL Object Localization
作者这里首先回顾了常见的单智能体进行物体检测的大致思路,此处不再赘述。
3.2. Collaborative RL for Joint Object Localization
本文将 single agent 的方法推广到 multi-agent,关键的概念有:
--- gated cross connections between different Q-networks;
--- joint exploitation sampling for generating corresponding training data,
--- a vitrual agent implementation that facilitates easy adaptation to existing deep Q-learning algorithm.
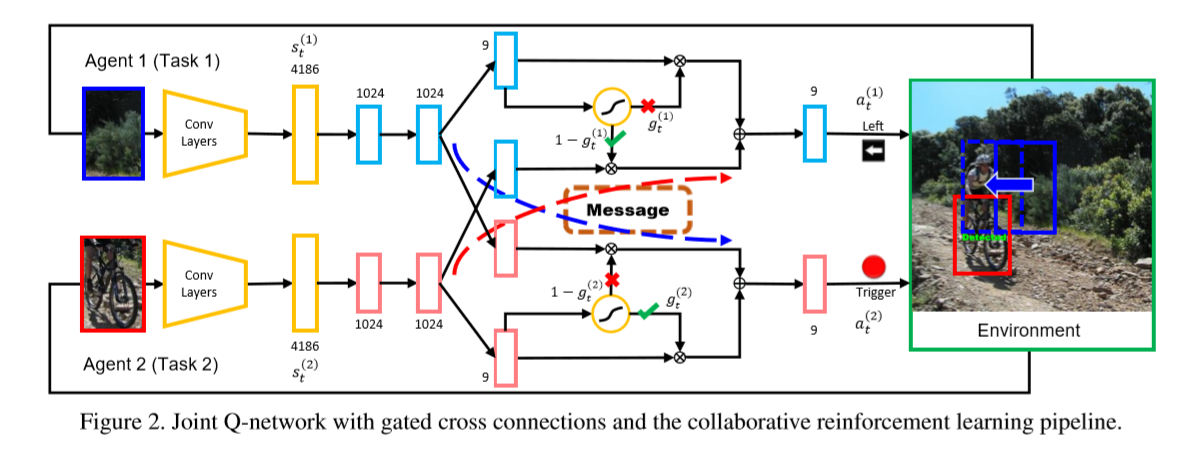
3.2.1 Q-Networks with Gates Cross Connections
本文是基于 Q-function 进行拓展的,常规的 Q-function 可以看做是:$Q(s, a; \theta)$,而 Deep Q-network 就是用 NN 来估计 Q 函数。假设对于每一个 agent i 我们有一个 Q-networks $Q^{(i)}(a^{(i), s^{(i)}; \theta^{(i)}})$,那么,在 multi-agent RL 设定下,很自然的就可以设计出一个促进 inter-agent communication 的 Q 函数出来,如: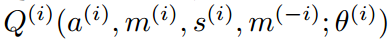
其中,m(i) 代表了从 agent i 发送出来的信息;M(-i) 代表了从其他 agent 得到的信息。
m 是
3.2.2 Joint Exploitation Sampling


——内核对象(Kernel object)机制](https://ucc.alicdn.com/pic/developer-ecology/je52eorcpmkr4_ee8fab9f99404b5ebbb79ed16da5ef11.png?x-oss-process=image/resize,h_160,m_lfit)