一、前言
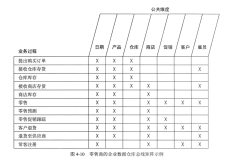
Many of you are already familiar with the data warehouse bus architecture and matrix given their central role in building architected data marts. The corresponding bus matrix identifies the key business processes of an organization, along with their associated dimensions. Business processes (typically corresponding to major source systems) are listed as matrix rows, while dimensions appear as matrix columns. The cells of the matrix are then marked to indicate which dimensions apply to which processes.
In a single document, the data warehouse team has a tool for planning the overall data warehouse, identifying the shared dimensions across the enterprise, coordinating the efforts of separate implementation teams, and communicating the importance of shared dimensions throughout the organization. We firmly believe drafting a bus matrix is one of the key initial tasks to be completed by every data warehouse team after soliciting the business’ requirements.
二、面临问题
While the matrix provides a high-level overview of the data warehouse presentation layer “puzzle pieces” and their ultimate linkages, it is often helpful to provide more detail as each matrix row is implemented. Multiple fact tables often result from a single business process. Perhaps there’s a need to view business results in a combination of transaction, periodic snapshot or accumulating snapshot perspectives. Alternatively, multiple fact tables are often required to represent atomic versus more summarized information or to support richer analysis in a heterogeneous product environment.
三、解决方案
We can alter the matrix’s “grain” or level of detail so that each row represents a single fact table (or cube) related to a business process. Once we’ve specified the individual fact table, we can supplement the matrix with columns to indicate the fact table’s granularity and corresponding facts (actual, calculated or implied). Rather than merely marking the dimensions that apply to each fact table, we can indicate the dimensions’ level of detail (such as brand or category, as appropriate, within the product dimension column).
四、总结
The resulting embellished matrix provides a roadmap to the families of fact tables in your data warehouse. While many of us are naturally predisposed to dense details, we suggest you begin with the more simplistic, high-level matrix and then drill-down into the details as each business process is implemented. Finally, for those of you with an existing data warehouse, the detailed matrix is often a useful tool to document the “as is” status of a more mature warehouse environment.