网页结构:
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a>
</div>
</body>
</html>连接:
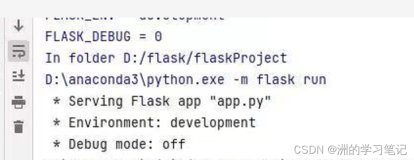
scrapy shell http://doc.scrapy.org/en/latest/_static/selectors-sample1.htmlPlay:
注意xapth与css两种方式的区别与联系
# selector
response.selector.xpath('//title/text()').extract()
response.selector.css('title::text').extract()
# response的selector的xpath与css太常用了,所以提供了简捷写法:
# 文本一
response.xpath('//title/text()').extract()
response.css('title::text').extract()
# 文本 包括子节点
sel.xpath("//a[1]//text()").extract()
# 文本 包括子节点
sel.xpath("string(//a[1])").extract()
# 属性
response.xpath('//img/@src').extract()
response.css('img::attr(src)').extract()
# 混合
response.css('img').xpath('@src').extract()
response.xpath('//img').css('::attr(src)').extract()
# 精确
response.xpath('//div[@id="images"]/a/text()').extract()
response.css('div[id=images] a::text').extract()
# 模糊
response.xpath('//div[contains(@id, "image")]/a/text()').extract()
response.css('div[id*=image] a::text').extract()
# 正则
response.xpath('//a[contains(@href, "image")]/text()').re(r'Name:\s*(.*)')