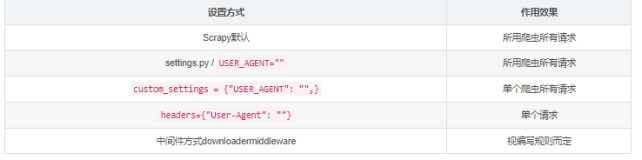
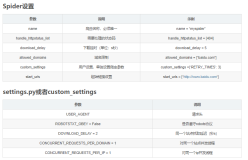
说明:
本文参照了官网文档,以及stackoverflow的几个问题
概要:
在scrapy中使用代理,有两种使用方式
- 使用中间件
- 直接设置Request类的meta参数
方式一:使用中间件
要进行下面两步操作
- 在文件 settings.py 中激活代理中间件
ProxyMiddleware - 在文件 middlewares.py 中实现类
ProxyMiddleware
1.文件 settings.py 中:
# settings.py
DOWNLOADER_MIDDLEWARES = {
'project_name.middlewares.ProxyMiddleware': 100, # 注意修改 project_name
'scrapy.downloadermiddleware.httpproxy.HttpProxyMiddleware': 110,
}说明:
数字100, 110表示中间件先被调用的次序。数字越小,越先被调用。
官网文档:
The integer values you assign to classes in this setting determine the order in which they run: items go through from lower valued to higher valued classes. It’s customary to define these numbers in the 0-1000 range.
2.文件 middlewares.py 看起来像这样:
代理不断变换
- 这里利用网上API 直接get过来。(需要一个APIKEY,免费注册一个账号就有了。这个APIKEY是我自己的,不保证一直有效!)
- 也可以从网上现抓。
- 还可以从本地文件读取
# middlewares.py
import requests
class ProxyMiddleware(object):
def process_request(self, request, spider):
APIKEY = 'f95f08afc952c034cc2ff9c5548d51be'
url = 'https://www.proxicity.io/api/v1/{}/proxy'.format(APIKEY) # 在线API接口
r = requests.get(url)
request.meta['proxy'] = r.json()['curl'] # 协议://IP地址:端口(如 http://5.39.85.100:30059)
return request方式二:直接设置Request类的meta参数
import random
# 事先准备的代理池
proxy_pool = ['http://proxy_ip1:port', 'http://proxy_ip2:port', ..., 'http://proxy_ipn:port']
class MySpider(BaseSpider):
name = "my_spider"
allowed_domains = ["example.com"]
start_urls = [
'http://www.example.com/articals/',
]
def start_requests(self):
for url in self.start_urls:
proxy_addr = random.choice(proxy_pool) # 随机选一个
yield scrapy.Request(url, callback=self.parse, meta={'proxy': proxy_addr}) # 通过meta参数添加代理
def parse(self, response):
# doing parse延伸阅读
1.阅读官网文档对Request类的描述,我们可以发现除了设置proxy,还可以设置method, headers, cookies, encoding等等:
class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback])
2.官网文档对Request.meta参数可以设置的详细列表:
- dont_redirect
- dont_retry
- handle_httpstatus_list
- handle_httpstatus_all
- dont_merge_cookies (see cookies parameter of Request constructor)
- cookiejar
- dont_cache
- redirect_urls
- bindaddress
- dont_obey_robotstxt
- download_timeout
- download_maxsize
- proxy
如随机设置请求头和代理:
# my_spider.py
import random
# 事先收集准备的代理池
proxy_pool = [
'http://proxy_ip1:port',
'http://proxy_ip2:port',
...,
'http://proxy_ipn:port'
]
# 事先收集准备的 headers
headers_pool = [
{'User-Agent': 'Mozzila 1.0'},
{'User-Agent': 'Mozzila 2.0'},
{'User-Agent': 'Mozzila 3.0'},
{'User-Agent': 'Mozzila 4.0'},
{'User-Agent': 'Chrome 1.0'},
{'User-Agent': 'Chrome 2.0'},
{'User-Agent': 'Chrome 3.0'},
{'User-Agent': 'Chrome 4.0'},
{'User-Agent': 'IE 1.0'},
{'User-Agent': 'IE 2.0'},
{'User-Agent': 'IE 3.0'},
{'User-Agent': 'IE 4.0'},
]
class MySpider(BaseSpider):
name = "my_spider"
allowed_domains = ["example.com"]
start_urls = [
'http://www.example.com/articals/',
]
def start_requests(self):
for url in self.start_urls:
headers = random.choice(headers_pool) # 随机选一个headers
proxy_addr = random.choice(proxy_pool) # 随机选一个代理
yield scrapy.Request(url, callback=self.parse, headers=headers, meta={'proxy': proxy_addr})
def parse(self, response):
# doing parse