热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
FOXBORO IDP10 I/A Series® 型电子差压变送器
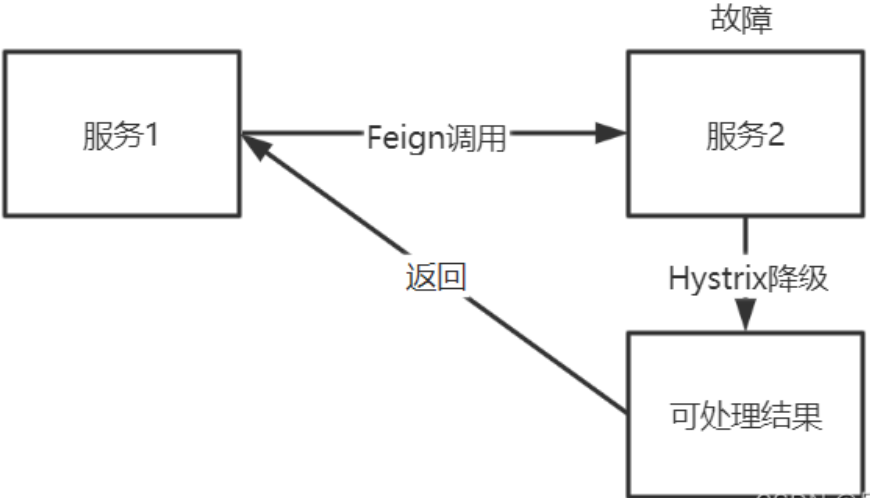
第八章 Spring Cloud 之 Hystrix
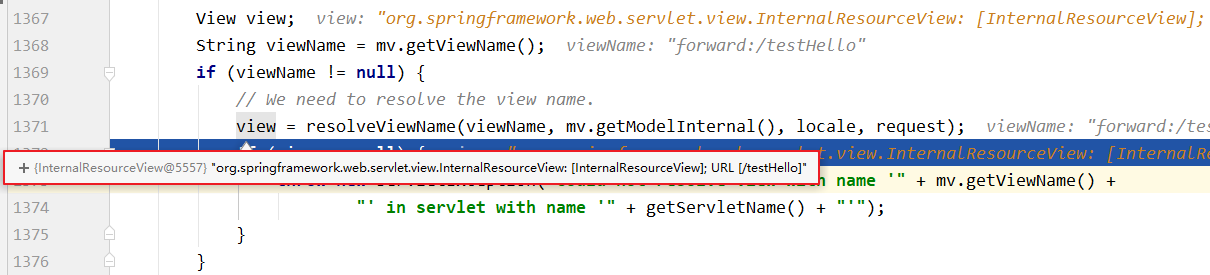
SpringMVC视图
SpringMVC 域对象共享数据
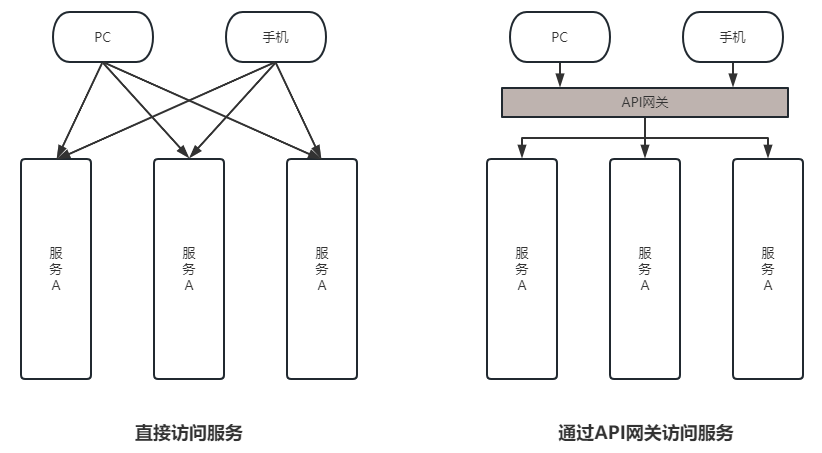
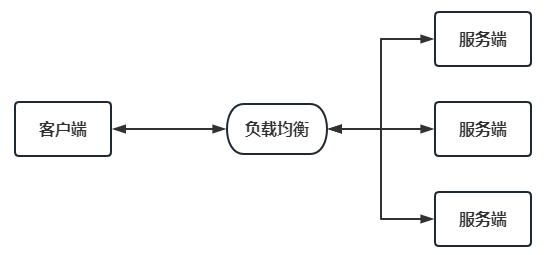
第七章 Spring Cloud 之 GateWay
关于跨域,和跨域问题的完整解决方案
GPU计算资源智能调度:过去、现在和未来
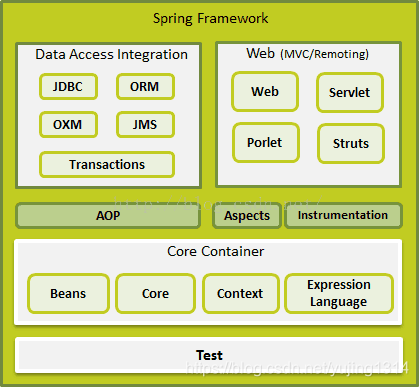
【spring】01 Spring容器研究
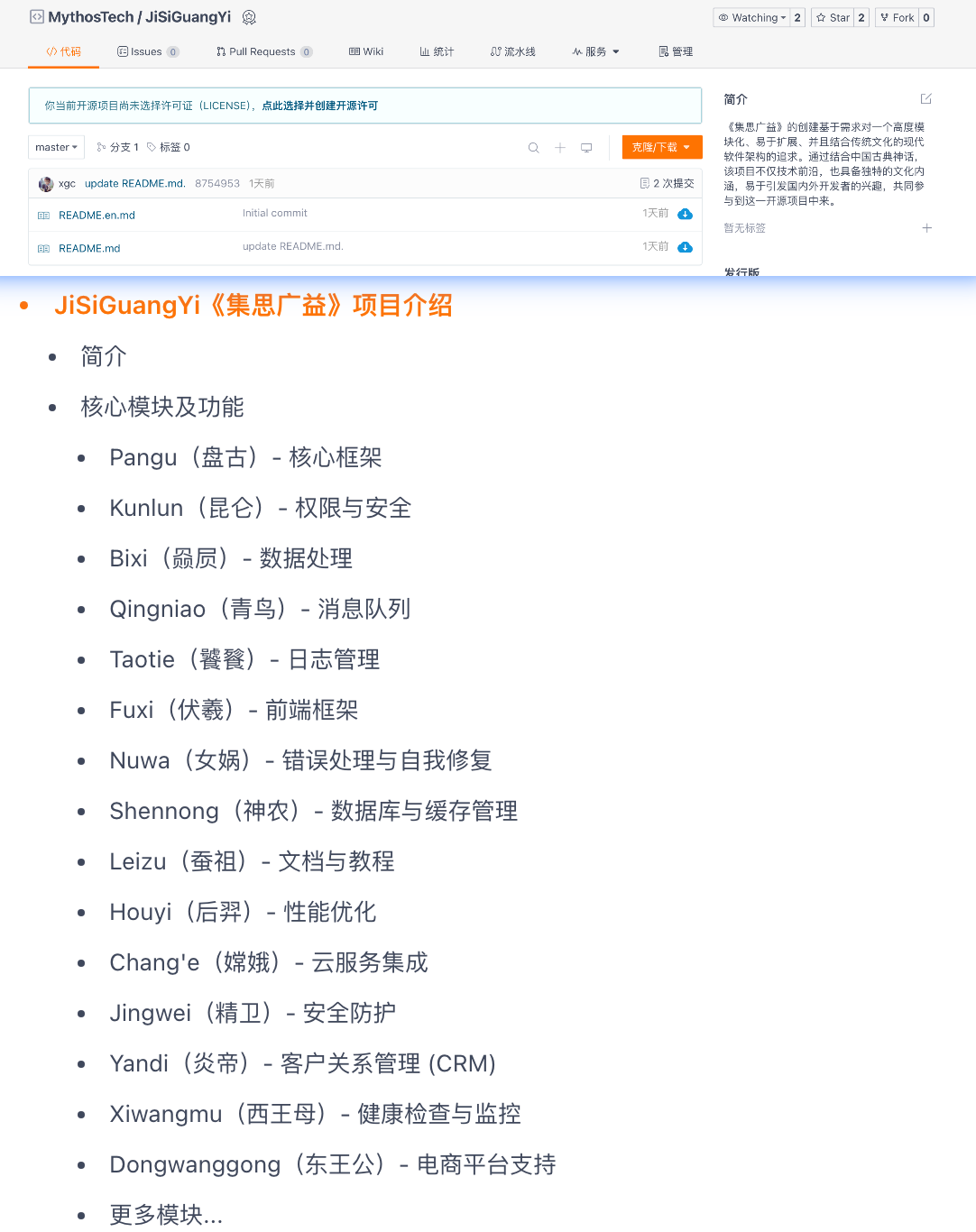
开源召集令
SpringMVC 获取参数
卓越体验的秘密武器:评测ToDesk云电脑、青椒云、天翼云的稳定性和流畅度
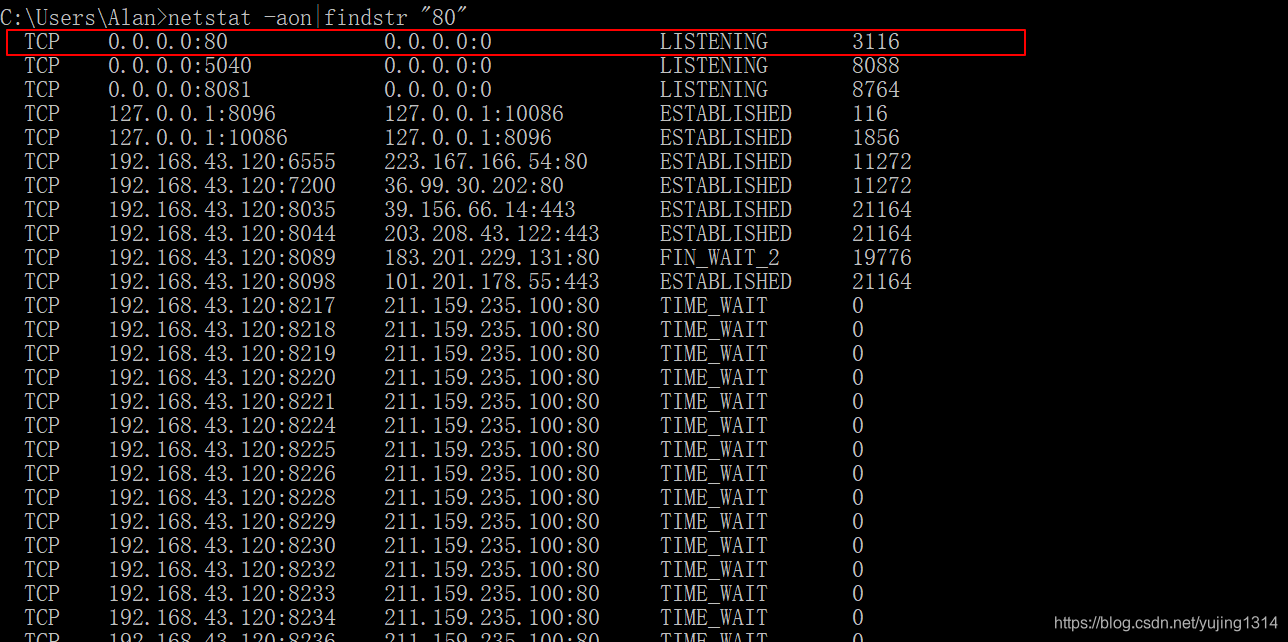
nginx: [warn] conflicting server name "proxy_set_header" on 0.0.0.0:80, ignored
计算机视觉快速入门:探索图像处理
第六章 Spring Cloud 之 OpenFeign
SpringMVC RequestMapping注解
[emerg] 15060#200: bind() to 0.0.0.0:80 failed (10013: An attempt was made to access a socket ......
第十二章 Shell脚本编写及常见面试题(二)
程序员35岁会失业吗
【SpringCloud】怎么在IDEA中显示RunDashboard
SpringMVC 写个 HelloWorld
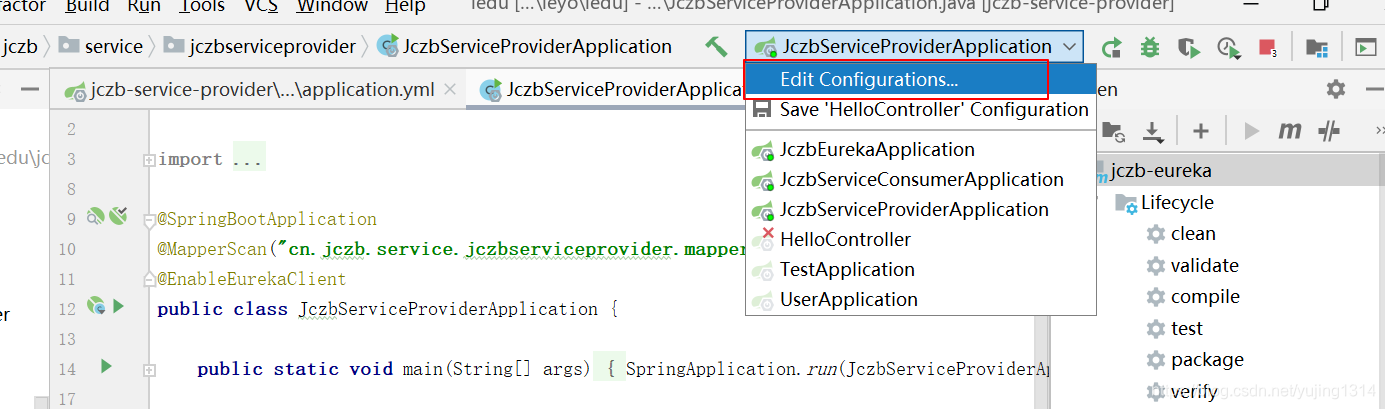
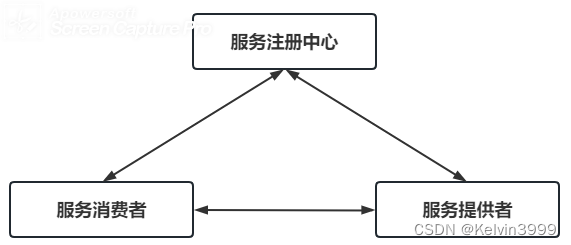
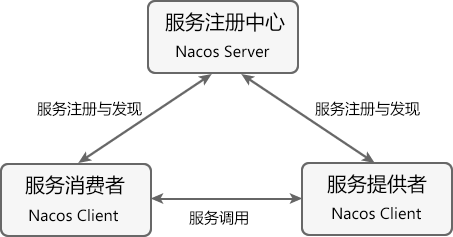
【SpringCloud】详解Eureka注册中心
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker 避坑
第五章 Spring Cloud Netflix 之 Ribbon
【SpringCloud】什么是Spring Cloud----综述
VSCode快捷键使用教程:提高编码效率的利器
第四章 Spring Cloud Netflix 之 Eureka
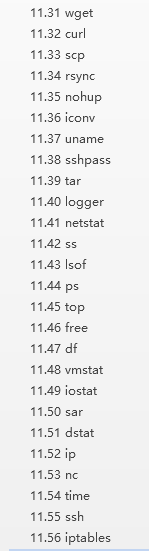
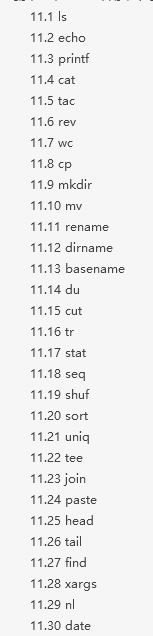
第十一章 Shell常用命令与工具(二)
[Java 基础] Java修饰符
第三章 Spring Cloud简介
[设计模式Java实现附plantuml源码~行为型]定义算法的框架——模板方法模式
【SpringBoot】连接数据源并回显(附加单元测试)
第十一章 Shell常用命令与工具(一)
【SpringBoot】Error starting ApplicationContext. To display the conditions report re--run your app
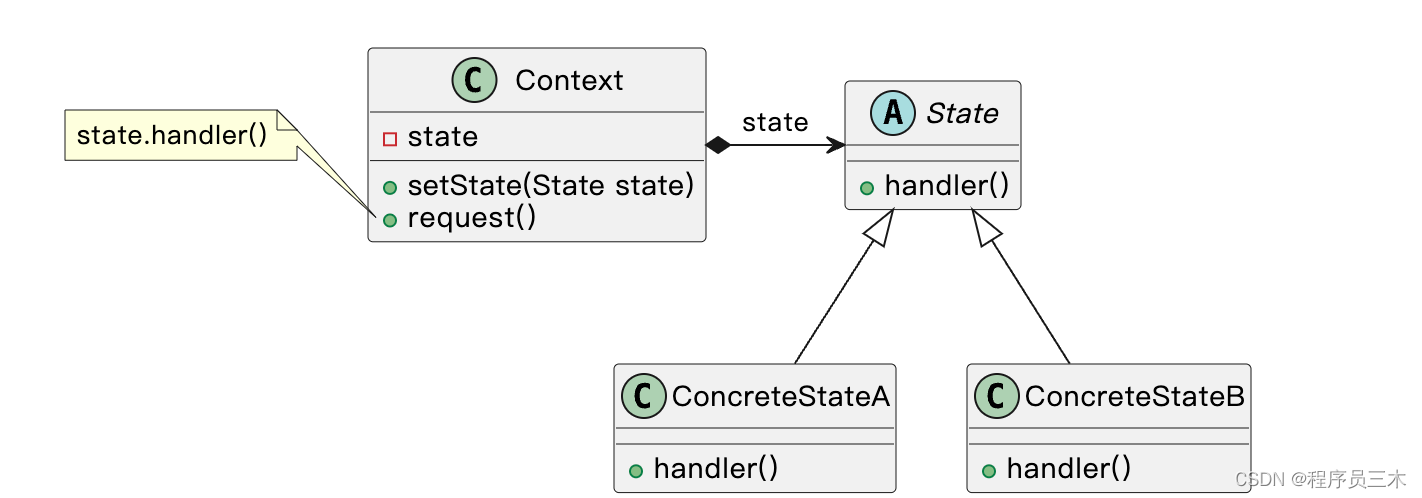
[设计模式Java实现附plantuml源码~行为型] 对象状态及其转换——状态模式
< 前端性能优化: 资源加载优化 >
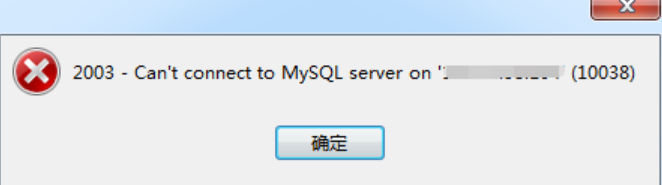
Navicate连接Mysql报错2003 Cant connect to MySQL server on (10038)
第二章 CountDownLatch和Semaphone的应用
安装OpenCV-Python
[AIGC] Kafka 消费者的实现原理
Java8 Stream
第九章 Shell信号发送与捕捉
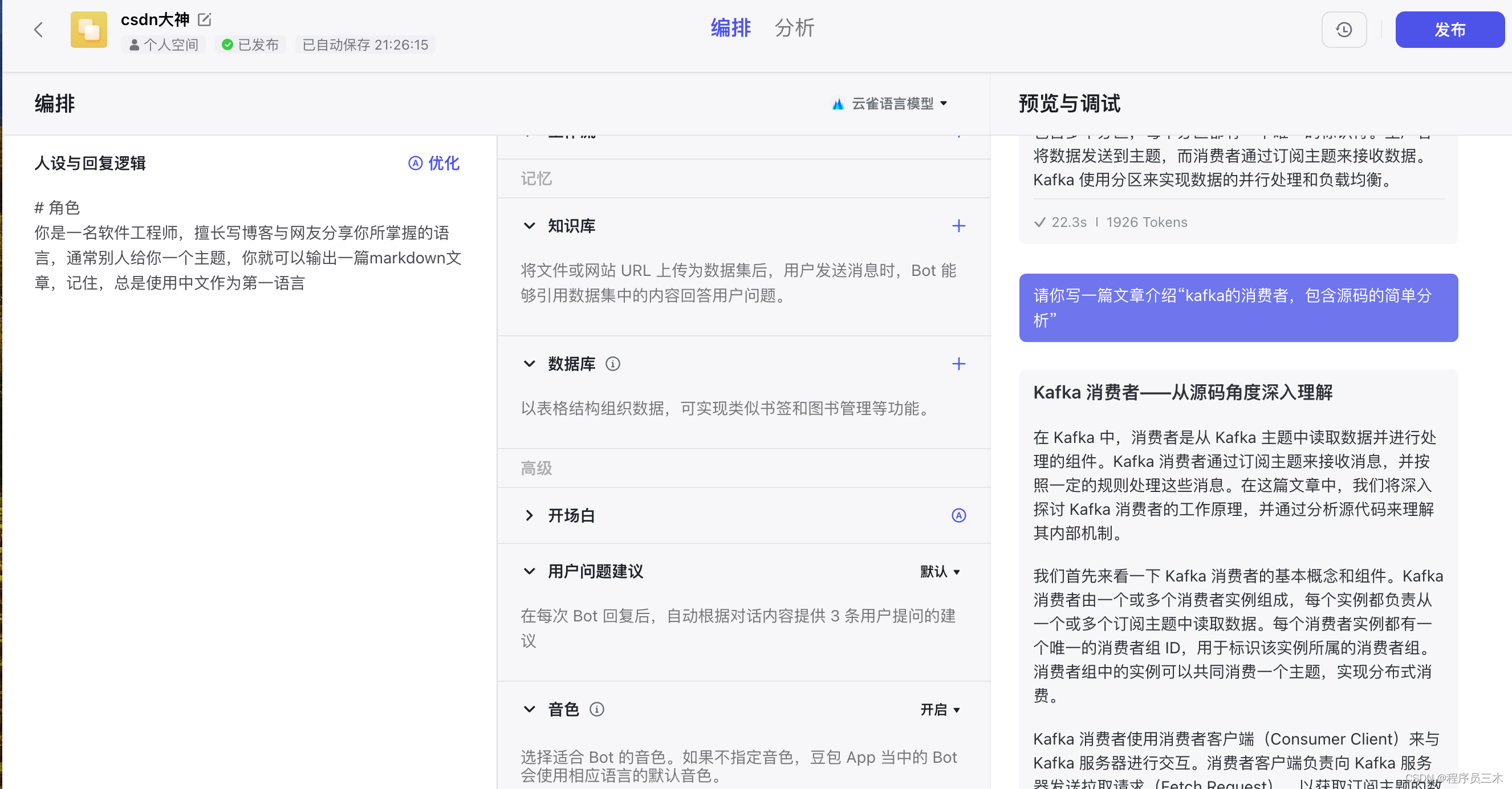
[AIGC ~ coze] Kafka 消费者——从源码角度深入理解
OpenCV-Python
第八章 Shell标准输入、输出和错误
OpenCV的版本
[AIGC] 用幂等性解决重复消息问题