之所以想写这篇文章,是我许久以来一直想把Modeler和SPSS应用在目前的玩家数据分析和购买充值分析方面,游戏数据分析针对的群体其实和电信,互联网,电子商务很像,属于虚拟经济的分支,并且要通过数据化的手段,结合企业自身的BI建设及企业数据分析人员的研究解决一些棘手的问题。KNN作为一种分类算法的应用领域很宽,很广,尽管没有归纳树,后向传播等那么得心应手,不过还是要学习的和使用的。
KNN可以应用在对新方案的评估和预测方面,当然要结合已有的样本(训练数据)进行对测试数据的分类和预测,这样就能够完成诸如电信新增套餐的制定,FPS同系列武器的更新把握和销售预计等等。
KNN(k-Nearest Neighbor algorithm )分类算法是最简单的机器学习算法之一,采用向量空间模型来分类,概念为相同类别的案例,彼此的相似度高,而可以借由计算与已知类别案例之相似度,来评估未知类别案例可能的分类。
KNN根据某些样本实例与其他实例之间的相似性进行分类。特征相似的实例互相靠近,特征不相似的实例互相远离。因而,可以将两个实例间的距离作为他们的“不相似度”的一种度量标准。KNN模型可以支持两种方法计算实例间距离,他们分别是:Euclidean Distance( 欧氏距离法 ) 和 City-block Distance(城区距离法)。
百度百科:
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比。
维基百科:
方法
- 目标:分类未知类别案例。
- 输入:待分类未知类别案例项目。已知类别案例集合D ,其中包含 j个已知类别的案例。
- 输出:项目可能的类别。
步骤
- 依公式计算 Item 与 D1、D2 … …、Dj 之相似度。得到Sim(Item, D1)、Sim(Item, D2)… …、Sim(Item, Dj)。
- 将Sim(Item, D1)、Sim(Item, D2)… …、Sim(Item, Dj)排序,若是超过相似度门槛t则放入邻居案例集合NN。
- 自邻居案例集合NN中取出前k名,依多数决,得到Item可能类别。
然而k最近邻居法因为计算量相当的大,所以相当的耗时,Ko与Seo提出一算法TCFP(text categorization using feature projection),尝试利用特征投影法(en:feature projection)来降低与分类无关的特征对于系统的影响,并借此提升系统效能,其实实验结果显示其分类效果与k最近邻居法相近,但其运算所需时间仅需k最近邻居法运算时间的五十分之一。
除了针对文件分类的效率,尚有研究针对如何促进k最近邻居法在文件分类方面的效果,如Han等人于2002年尝试利用贪心法,针对文件分类实做可调整权重的k最近邻居法WAkNN (weighted adjusted k nearest neighbor),以促进分类效果;而Li等人于2004年提出由于不同分类的文件本身有数量上有差异,因此也应该依照训练集合中各种分类的文件数量,选取不同数目的最近邻居,来参与分类。
案例演示:
某汽车制造厂商的研发部门制定出两款新预研车型的技术设计指标。厂商的决策机构希望将其和已经投放到市场上的已有车型的相关数据进行比较,从而分析新车型的技术指标是否符合预期,并预测新车型投放到市场之后,预期的销售额是多少。(来自IBM DeveloperWorks)
值得指出的是KNN算法在IBM SPSS Statistics和Modeler中均有应用,今天将使用IBM SPSS Modeler进行演示KNN算法应用。
KNN是根据观测值与其他观测值的类似程度分类观测值的方法。在机器学习中,将其开发为识别数据模式的一种方法,而不需要与任何存储模式或观测值完全匹配。相似个案相互邻近,非相似个案则相互远离。因此,两个观测值之间的距离是其不相似性的测量。
将靠近彼此的个案视为“相邻元素。”当提出新的观测值(保留观测值)时,计算其到模型中每个观测值的距离。计算最相似观测值–最近相邻元素–的分类并将新观测值放在包含最多最近相邻元素的类别中。
我们可以规定需要检验的最近相邻元素(最近邻居)的数量;此值叫做k。图片显示如何使用两个不同的k值分类新观测值。当k=5时,新观测值将被置于类别1中,因为大多数最近相邻元素属于类别 1。但当 k = 9 时,新观测值将被置于类别 0 中,因为大多数最近相邻元素属于类别 0。
“最近邻居数量 K 在最近邻元素分析模块建模中起到了很大的作用。K 的取值不同,将会导致对新实例分类结果的不同。如图 1所示,每个实例根据其目标变量取值(0 和 1)的不同,被分入两个类别集合。当 K=5 时,与新实例连接的旧实例(邻居)当中,目标变量取值为 1 的实例数更多,所以新实例被分到类别 1 当中。然而,当 K=9 时,目标变量取值为 0 的邻居更多,因此新实例被分到类别 0 当中。Statistics 的最近邻元素分析模型既允许用户指定固定的 K 值,也支持根据具体数据自动为用户选择 K 值。
KNN模型支持 feature selection(预测变量选择)的功能,允许在用户输入的众多的预测变量当中,只选择一部分预测变量用作建模,使得建立的模型效果更好。
KNN模型允许建立目标变量是连续型变量的模型,在这种情况下,目标变量的平均值或者中位数值将作为新的实例目标的预测值。
如下图为更改 k 对分类的影响
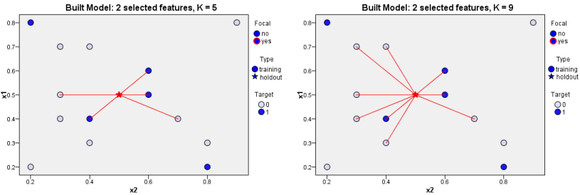
相互临近的实例被称之为“Neighbors(邻居)”。当我们向模型中引入一条新的实例,它和模型当中已经存在的每一个实例之间的距离将会被计算出来。这样,与这条新实例最相近的邻居就被区分出来了。图中描述了一个目标变量是离散型变量的最近邻模型, 红色五角星是新实例,白色和蓝色的点是模型当中已有实例。与他最近的邻居们都被用红线连接了起来。
数据处理方式
参考IBM DeveloperWorks的 SPSS Statistics办法
新增数据的技术指标(变量信息)
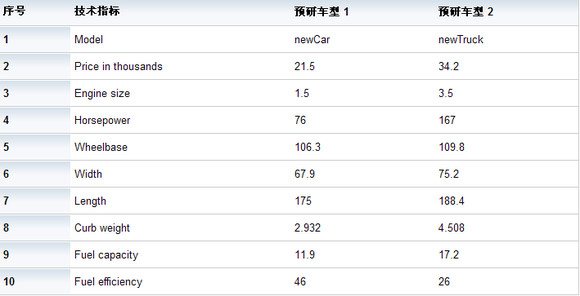
制造商收集了有关现有车型的不同类别的数据,并添加了其原型产品的详细信息。需要在不同车型间进行比较的类别包括以千为单位的价格 (price)、发动机尺寸(engine_s)、马力 (horsepow)、轴距(wheelbas)、车宽 (width)、车长 (length)、整车重量 (curb_wgt)、油箱容量(fuel_cap) 和燃油效率 (mpg)。
在原数据文件当中增加两条新的记录:
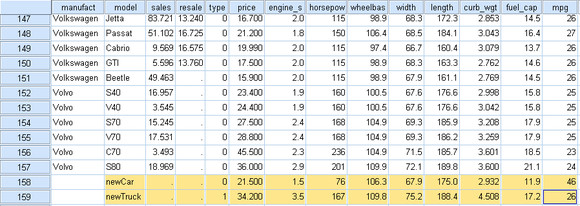
增加焦点变量
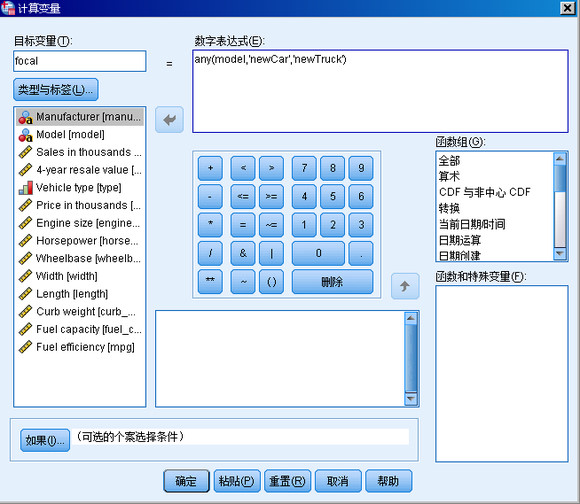
然后,我们要为这两条新记录加上特别关注的标记,这需要为所有记录增加新的变量。通过菜单 Transform->Compute Variable(转换 -> 计算变量),打开计算变量对话框,如图所示。
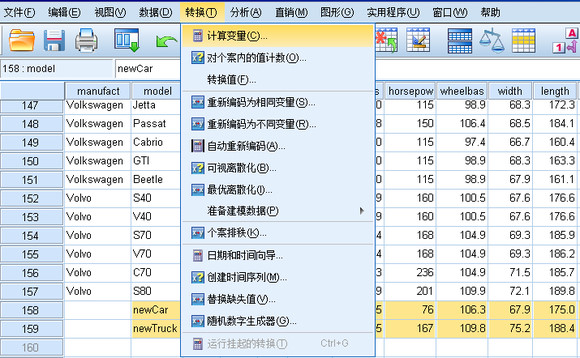
键入 focal 作为 Target variable(目标变量),在 Numeric Expression(数字表达式)文本框当中键入表达式:
any(model, 'newCar ','newTruck')。根据这个表达式,对于任意一条记录,其 model 变量的取值如果是 newCar 或 newTruck,则它的 focal 变量的取值被设置为 1,否则被设置为 0。
增加分区变量
再增加一个新变量 partition,以区分 Training( 训练数据子集 ) 和 Holdout( 测试 ) 子集,我们将已有车型视为训练数据子集,而新车型为测试子集。如图所示。
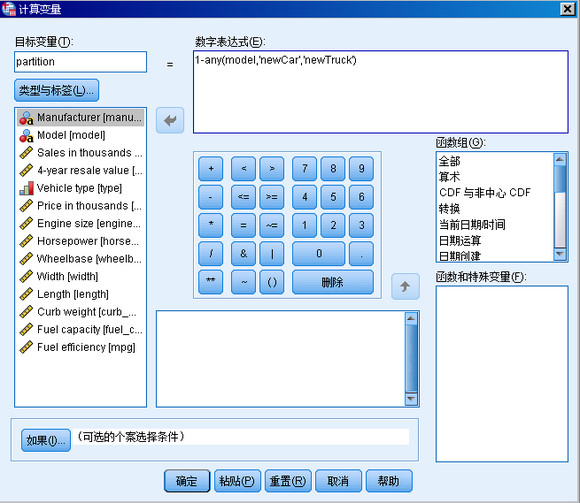
注意在数字表达式文本框中填写 1-any(model, 'newCar','newTruck'),使得变量 partition 的取值与变量 focal 正好相反。之所以这样做是由于算法中规定:partition > 0 表示为训练数据,这两个新车型作为测试数据,将其 partition 设为 0;而 focal = 1 为重点关注对象。
使用Modeler14进行模型分析
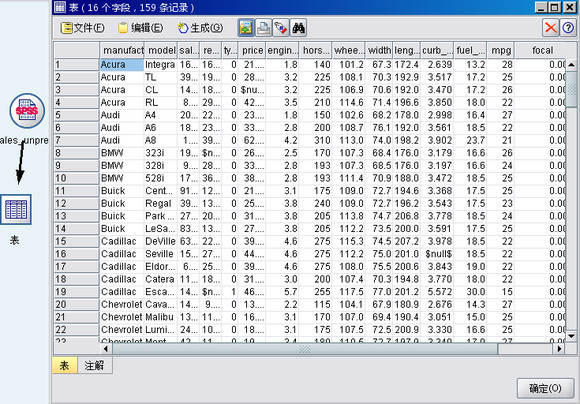
首先在Modeler14中导入SPSS文件,执行打开连接,数据形式如下:
类型节点设置
将“类型”节点连接到原数据节点上,右键编辑,打开窗口如下:
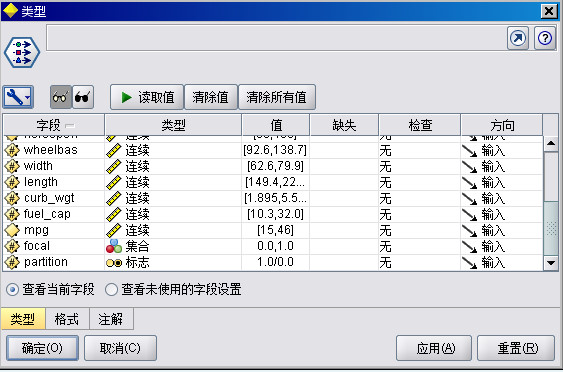
参数设置
只在字段 price 至 mpg 上进行比较,因此保持所有这些字段的角色设置为输入。将所有其他字段 (manufact 至 type) 的角色设置为无。将最后一个字段分区的测量级别设置为标志。确保将其角色设置为输入。单击读取值以读取数据值到流中,单击确定。
以上为KNN模型数据分析的数据准备阶段,此后就是具体的模型数据处理和分析阶段,时间和篇幅所限该阶段将在以后继续完成。
参考:
[1]IBM DeveloperWorks(http://www.ibm.com/developerworks/cn/data/library/techarticle/dm-1201gex/)
[2]IBM SPSS Modeler14.0手册
[3]百度百科:KNN
[4]维基百科:KNN




