关联分析的学习
在说关联分析之前,先说说自己这段时间的一些感受吧,这段时间相对轻松一些,有一些时间自己自己来学习一些新东西和知识,然而却发现捧着一本数据挖掘理论的书籍在一点一点的研读实在是很漫长,而且看过了没有什么感觉。数据这一行理论很多,算法很多,模型很多,自己现在一直是结合业务来做的数据分析与挖掘,相比电商而言,游戏业做的数据大多很糙,但是仅仅结合业务和运营,更加注重我们客户的质量和维护,当然这不是说电商没做,实际上电商一直在做,然而最近一次经历发现,我们过多的时候去讨论了算法,模型,新理论,新算法研究,比如爬虫,JS,写个脚本测试一下,验证一下,可我一直在考虑,为什么我们要这么做?意义究竟是什么?你费了九牛二虎之力做好的研究,能够以后一直使用,形成规范吗?或者一直是想到一个就研究一下,用毕,放下了,再有新的在研究。
以前看了苏杰的产品经理那本书,其中有一个例子很好,为什么停车位游戏里面就只有四个停车位,而不是八个?回答这个问题,我觉得你即使数据理论、算法在NB你也很难搞得明白,你还是要仅仅结合业务搞明白内在的一些疑问,你才能防守研究。技术流派的数据分析必须要,但是完全的主导,缺少了人性和上层的构建,厉害的技术,NB的算法也无济于事。
然而理论,算法,模型我们还要学习,核心在于我们如何理解和使用,这些东西都是经历了实践的检验,所以才有存在和学习的意义。但请不要为技术论,过度理性的思维往往就走到死胡同,我们也需要乔爷一般的嗅觉和敏感。
废话太多,开始吧。
关联分析是啥?
关联分析是数据挖掘中很重要的一类技术,其实就是挖掘事物之间的联系。
关联分析都研究什么关系?
关联分析研究的关系有两种:简单关联关系和序列关联关系。
简单关联关系
比如在FPS游戏中,购买M4A1的玩家中80%会购买MP5冲锋枪,这就是一种简单的关联关系,经典的购物篮分析中有个例子说,购买面包的顾客中80%会购买牛奶。面包和牛奶作为一种早餐的搭配是大家所接受的,二者没有共同属性,但是二者搭配后就是一顿美味早餐。商场购买时,如果你把这两样摆在一起时,就会刺激顾客的潜意识(这是定位理论的内容,以后再说,文章题目‘从定位理论来看关联购买应用实施’),联系了二者的关系,并刺激购买。这是一种简单的关联关系。
序列关联关系
在FPS中,购买雷包的玩家中80%会购买闪光雷和高爆雷,这属于序列关系,也就是说具有先后顺序。再比如买了iphone手机的顾客中80%会选择购买iphone手机保护壳,这就是序列关联关系,一般没人先去买个保护壳再去买手机。这是存在先后的时间上的顺序的。这里就再说一个例子,比如装备强化系统,我们可以衡量一下得到宝石然后去打孔镶嵌宝石的关系或者先去打孔后去直接购买宝石的关系分析,一般游戏为了刺激玩家在强化方面的消费能力,会选择赠送部分宝石,引导玩家强化,那么我们是否可以做一个分析?
怎么定量的分析这种关联关系?
说到定量分析这种关系,分析就得有个算法或者公式,这就是我们约定一个规则,我们要按照规则来做分析,学名叫做关联规则。早期是在研究超市顾客购买商品的规律方面得到广泛应用,也就是购物篮分析。
游戏的数据分析需要做不?
关联分析在电商、零售、保险等诸多领域广泛应用。对于游戏数据分析来说,关联分析的确是我们要非常重视的一块,尤其是道具收费模式占据主导的网游市场,当然时间收费游戏也需要这样来做,我们的运营活动效果评估,玩家的充值购买习惯,游戏行为跟踪,精准推送都是和关联分析有很大的关系。其实游戏中道具的消费除了玩家自身与系统的高度融合和自主消费以外,其实还有一部分隐形的消费,或者说是延伸消费,打个比方,比如我们去一个超市目标很明确就是要去买一瓶可乐,然而往往我们结账时手里不是单纯就有一罐可乐,可能还有口香糖,可能还有其他的商品,为什么?人是视觉动物,纯粹理性消费存在,但是受到外界刺激和影响,往往刺激再生消费,也就是很多的冲动型消费,而在游戏中来看,就是打开这些消费,关联分析就是寻找这些刺激因素,进而延伸玩家的消费。
关联规则是什么?
规则这里就是一种衡量事物的标准,再说白了就是一个算法。关联规则主要有两种。今天就先说说简单规则的理论部分。
简单关联规则
简单关联规则属于无指导的学习方法,着重探索内部结构。简单关联规则也是我们使用最多的一类技术。算法有Apriori、GRI、Carma,其中Apriori和Carma主要是如何提高关联规则的分析效率,而GRI注重如何将单一概念层次的关联推广到更多概念层次的关联,进而揭示事物内在结构。
在网游方面的应用目前我想到了几个:
1、 基于玩家的购买行为进行玩家区分;
2、 付费用户流失分析,比如是否是因为某些道具的下架导致玩家付费流失;
3、 道具商城道具的位置摆放,玩家购买后的推荐购买,交叉销售。
简单关联规则的数据存储形式
数据存储形式主要有两种,一种是交易数据格式,另一种是表格数据格式,详见早期一篇文章所述内容。
判断标准
说到判断标准,其实就是对于简单关联规则有效性实用性的检验,因为不是所有关联规则都有效,某些规则适用范围有限,进而这些规则不具有有效性,所以我们要有一些判断的标准。
规则支持度(Support)
支持度,就是支持某一事件发生的概率,可以这么理解,所谓规则支持度就是表示商品A和商品B同时出现的概率(A和B同时出现这一事件的概率),即S A->B=N(A&B)/N ,N代表总的个数,N(A&B)代表同时出现A和B的次数,如果S值很低,那么规则普遍性一般,应用层次太低。
规则置信度(confidence)
置信度,就是特定个体对待特定命题真实性相信的程度,也就是令人信服的水平,具体来说比如在商品A购买的顾客中,购买商品B的概率,或者说购买水平。这其实是一个条件概率的问题,即在A出现情况下B出现的可能性,即C A->B=N(A&B)/N(A),如果置信水平高,那么这种特定条件出现可能性就很高。
前项支持度 S A = N(A)/N
后项支持度 S B=N(B)/N
由此这里我们可以推断出 C和S是存在关系的,即:
C A->B = S A->B/ S A
在关联分析,我们希望得到的规则是具有很高的C和S的。可是如果S高,但是C低,那么整个的这个规则令人信服的程度就会下降,如果反过来,那么意味着这个规则产生的普遍性不高,就是应用层有问题,但是置信水平还可以。
所以说我们虽然可以通过简单关联规则分析生成很多的关联规则,然而我们必须得有一个临界值(阈值),来控制C和S的水平,因为我们能生成很多的规则,通过阈值控制扫除一些我们不需要的或者无用的规则。
当然了,通过我们设定的阈值的置信度和支持度就是一条有效的规则,但有效就一定意味着可以使用吗?事实上,还不行,因为有效的规则下不一定有实际的指导意义。因为揭示出的关系有可能只是一种随机关联的关系。说白了就是巧合。举一个例子,通过关联规则我们发现购买道具A的玩家40%为男性角色,S=40%,C=40%。此时阈值为20%,看来符合以上我们所说的情况,但是我们经过分析发现玩家中那行角色比例也是40%,而这就是一种随机关联,不具备实用性。
因此我们需要一些指标来辅助监测规则实用性。
规则提升度(lift)
L A->B=C A->B/ S B
实际就是置信度与后项的比值。提升度反映了商品A出现对于商品B的影响程度。大于1才有意义,也就是A对于B的促进作用,越大越好。
置信差(Confidence Difference)
置信度与后项支持度的绝对值差。
CD=|C A->B-S B|
置信差进一步提高关联规则结果的可用性,其差代表了获得关联规则所提供信息的多少。
置信率(Confidence Ratio)
CR=1-|min(lift,1/lift)|
置信率当然也是越高越好,有的时候我们置信差很低,那么也可以参考CR值,与刚才提到的lift相似,lift越大越好,进而这里来看,lift越大,那么CR也就越大。
当然了衡量的标准还有正态卡方、信息差,这里不再讲述,感兴趣自己可以看看。
下面我们说说序列关联规则
序列关联规则
核心在于怎么找到事物发展的前后关联性,比如用户访问web站点,具体的页面点击习惯,购买商品过程关联性,较为著名的比如超市商品货架的布局。研究序列关联性可以帮助我们推断后续发生的可能性,并调整好顺序,扩大份额。这在游戏中的道具推送,玩家与系统的交互,任务接取,道具购买有直接的关系。
如下图所示,为玩家的购买道具时序数据,每一行为一个事务序列数,代表一个玩家。
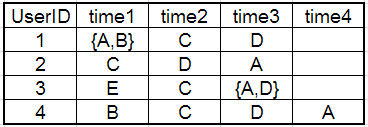
比如1号玩家首先购买A和B,之后购买C,再次购买D,这就是一个购买序列,而这个序列对于我们分析购买流失,具有很大的意义。1号顾客的购买序列可以表示出来,此外,购买序列还可以进行分解,分列出子序列。如下图。
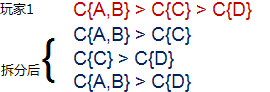
定量分析序列指标
序列长度
表示序列拆分出来的子序列,以玩家1为例有3个子序列,因此序列长度为3。
序列大小
表示序列中拥有的项目数量,玩家1有四个项目,A、B、C、D。
序列支持度
序列普遍性的衡量标准,包含某个序列的序列的事事务序列数占总事务序列数的比例。比如C{D}>C{A}的支持度为2/4=0.5。
序列规则支持度
包含某序列的规则的事务占总事务的比例。
序列规则置信度
同时包含前项和后项事务数与仅包含前项事务数的比值,即支持度与前项支持度的比值。
好了,理论第一部分就到这里,以后说说两类关联分析的算法 Apriori、GRI、Carma、Sequence。
参考:
Clementine 数据挖掘方法及应用 薛薇著
Jiawei Han,Micheline Kamber.Data Mining:Concept and Techniques,Morgan Kaufmann Publishers,Inc.2001

