昨天分享了以前学习的聚类分析算法K-Means的部分知识,其实这个主要是了解一下这个算法的原理和适用条件就行了,作为应用而不是作为深入研究,能够很好的将业务和算法模型紧密结合的又有几人呢?所以一些基本知识还是很必要的,这里就是简单把看过的一些知识点列举一下,梳理一下,快速了解和使用。
今天把TwoSteps的知识也梳理一下,顺便做个小的演示,使用SPSS 19,后续在使用SPSS Modeler或者叫做Clementine再演示一次使用方法。首先上图。
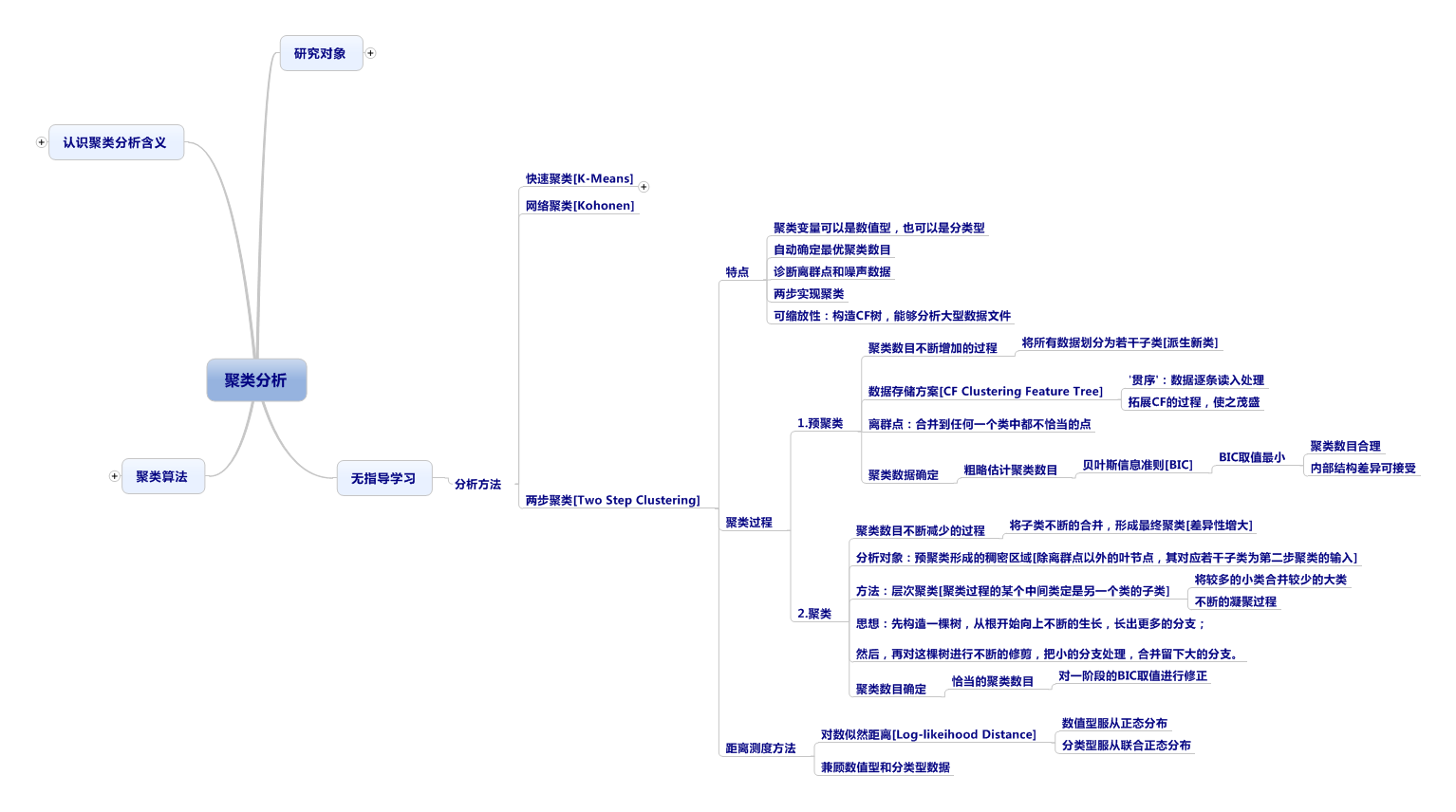
TwoSteps支持数值型和分类型数据,这对于我们而言在使用时就方便很多,此外游戏数据一般来说都很大,TwoStep在这方面来说还是很具有优势的,数据迭代过程中的内存消耗和聚类数目确定,TwoStep表现的都很好,两步聚类避免了距离矩阵过大,导致算法执行效率下降,而这也是优势所在。好了以上的信息看多也没什么意义,还是看看怎么实践吧。
最近换了工作,开始做手机网游的数据分析,也是想尝试一下,面临一个问题就是游戏的留存比较差劲,想来想去就拿这个做一个聚类分析的例子吧。
首先,这里选取的是次日留存用户数据进行分析,之所以选择次日,是由游戏的特点决定的,再者手机游戏的周期相对短一些,所以如果考虑周,双周就不是很好了(当然也不是绝对的),其实3日留存也可以选择,只是需要了解你自己的游戏具体情况再做判断。
其次,选择什么时间的次日留存数据分析呢?这个问题困扰了我很长时间,因为本身分析新登玩家次日登陆的那部分群体的特征(其实这样分类的方式已经有些破坏了聚类分析的本质和诉求),我选取的时间是周五(为什么是周五,这里不说了,大家自己想),且从时间上,全部渠道(手机游戏渠道很多)均以开放,且离最近的开放的渠道有一段周期(数据平稳后)。同时游戏没有重大的更新,BUG,调整时期。
第三,既然要做聚类分析,那我们选什么数据作分析,提取特征呢?我们要做的是提取次日留存用户的特征,因此,根据需要我们提取了一些用户的数据点,如下图所示:
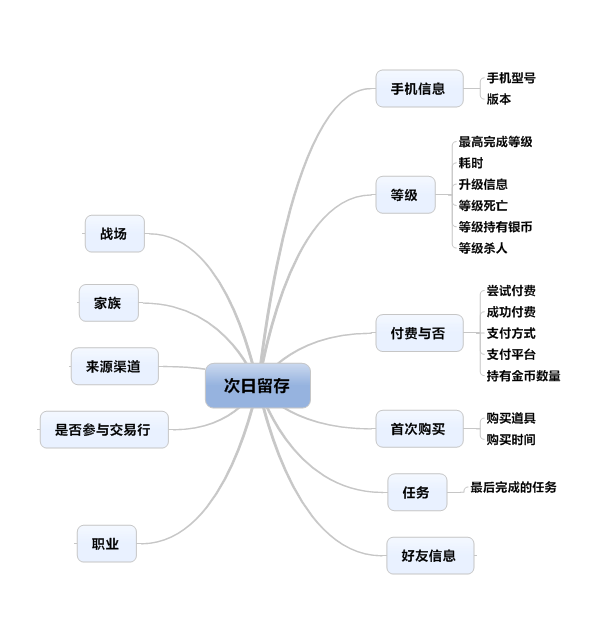
其实,还有很多的数据,然而这里很多都是取不出来的(2进制,你懂得),由于分析的是次日留存,因此用户的游戏进程大多数不会很长,这里也只会取一些和新登用户关联比较大的,比如来源,职业,好友,是否付费,等级(最高和最低等级)。其实按照我们分析的围堵不同还可以取其他的数据,这里就是一个演示,请见谅。下面就用SPSS 19演示一下怎么进行该计算过程。
打开“菜单|分类|两步聚类”,如下图所示:

弹出的菜单如下:
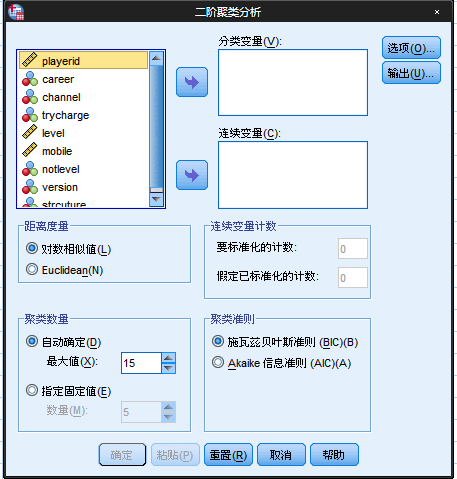
此时,要进行变量选择,如果是分类变量,就选择进入分类变量,如果是连续变量,就选择进入连续变量,选择如下:
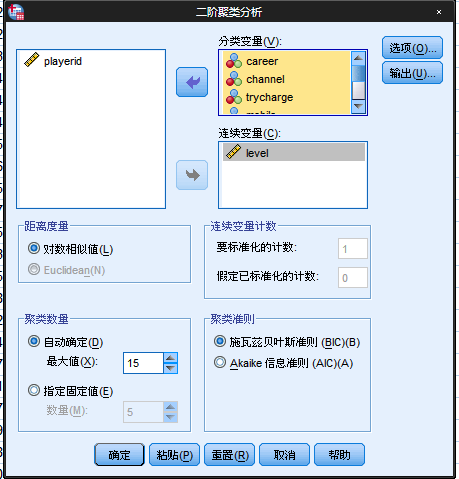
距离变量:确定计算两个变量之间的相似性,对数相似值系统使用对数似然距离计算,而欧式距离是以全体变量为连续性变量为前提的,由于我们的数据中存在分类型变量,因此这里选择对数相似值。
聚类数量:允许指定如何确定聚类数。如果自动确定将会使用聚类准则中指定的准则[BIC 或者 AIC],自动确定最佳的聚类数,或者设置最大值。也可以指定一个固定值,不过一般来说就自动确定OK了。
连续变量计数:对一个变量是否进行标准化的设置。
点击选项,弹出如下的面板
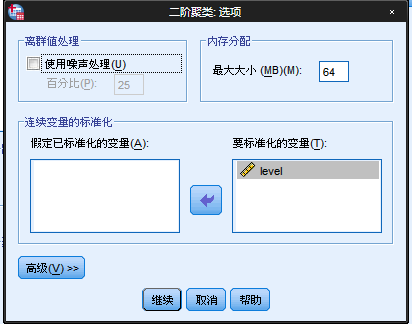
离群值处理:这里主要是针对CF填满后,如何对离群值的处理。IBM SPSS手册如下所诉:
“如果选择噪声处理且 CF 树填满,则在将稀疏叶子中的个案放到“噪声”叶子中后,树将重新生长。如果某个叶子包含的个案数占最大叶大小的百分比小于指定的百分比,则将该叶子视为稀疏的。树重新生长之后,如有可能,离群值将放置在 CF 树中。否则,将放弃离群值。
如果不选择噪声处理且 CF 树填满,则它将使用较大的距离更改阈值来重新生长。最终聚类之后,不能分配到聚类的变量标记为离群值。离群值聚类被赋予标识号–1,并且不包含在聚类数的计数中。”
关于噪声处理,此处默认即可。
内存分配:指定聚类算法应使用的最大的内存量。如果该过程超过了此最大值,则将使用磁盘存储内存中放不下的信息。此项默认就行了。
连续变量的标准化:聚类算法处理标准化连续变量。
点击输出:弹出界面如下

图和表:
“显示模型相关的输出,包括表和图表。模型视图中的表包括模型摘要和聚类-特征网格。模型视图中的图形输出包括聚类质量图表、聚类大小、变量重要性、聚类比较网格和单元格信息。”有点用。
评估字段:“这可为未在聚类创建中使用的变量计算聚类数据。通过在“显示”子对话框中选择评估字段,可以在模型查看器中将其与输入特征一起显示。带有缺失值的字段将被忽略”可以不用理。
OK,此时,点击继续,然后确定,等待计算结果出来,这时首先弹出的是查看器:
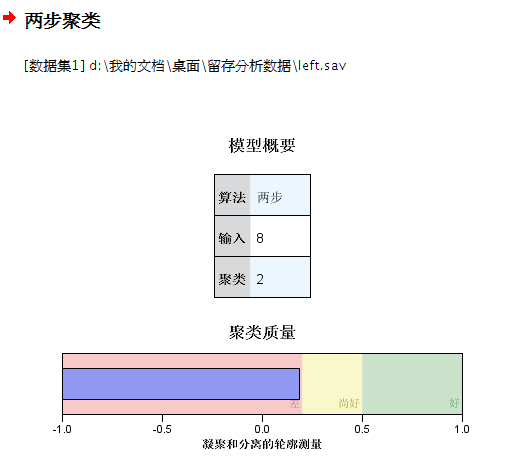
之后双击这个模型,就会弹出来聚类浏览器:
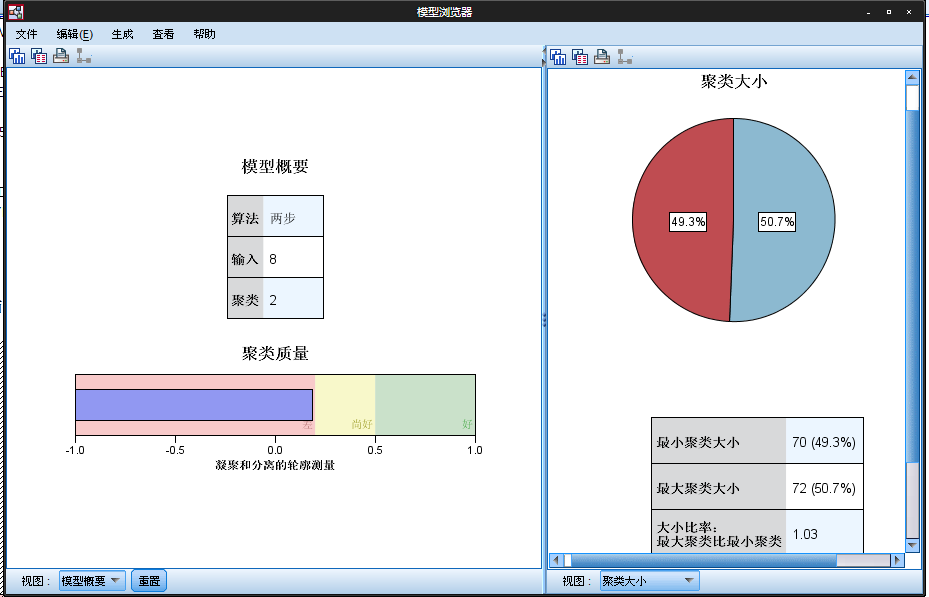
以下介绍该浏览器的信息来自于IBM SPSS的官方手册,详见:http://www.dmacn.com/viewthread.php?tid=78&extra=page%3D1
“聚类浏览器”包含两个面板,主视图位于左侧,链接或辅助视图位于右侧。有两个主视图:
模型摘要(默认视图)
分群。
有四个链接/辅助视图:
预测变量的重要性.
聚类大小(默认视图)
单元格分布。
聚类比较。
“模型摘要”视图显示聚类模型的快照或摘要,包括加阴影以表示结果较差、尚可或良好的聚类结合和分离的 Silhouette 测量。该快照可让您快速检查质量是否较差,如果较差,可返回建模节点修改聚类模型设置以生成较好的结果。
结果较差、尚可和良好是基于 Kaufman 和 Rousseeuw (1990) 关于聚类结构解释的研究成果来判定的。在“模型摘要”视图中,良好的结果表示数据将 Kaufman 和 Rousseeuw 的评级反映为聚类结构的合理迹象或强迹象,尚可的结果将其评级反映为弱迹象,而较差的结果将其评级反映为无明显迹象。Silhouette 测量所有记录的平均值,(B A) / max(A,B),其中 A 是记录与其聚类中心的距离,B 是记录与其非所属最近聚类中心的距离。Silhouette 系数为 1 表示所有个案直接位于其聚类中心上。 值为 1 表示所有个案位于某些其他聚类的聚类中心上。值为 0
表示在正常情况下个案到其自身聚类中心与到最近其他聚类中心是等距的。
摘要所包含的表格具有以下信息:
算法。所使用的聚类算法,例如“二阶”。
输入功能。字段数量,也称为输入或预测变量。
分群。解中聚类的数量。
关于模型的使用的详细信息这里不再累述,请参考 官方手册 IBM SPSS Statistic 19 Base.pdf [152-159]
