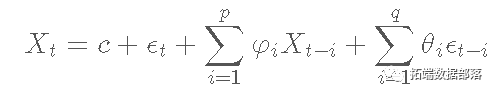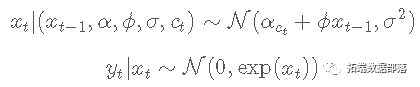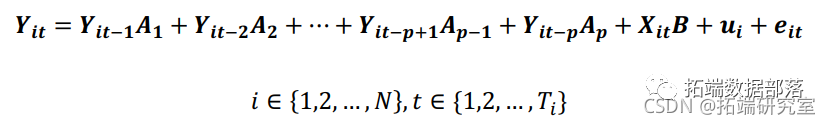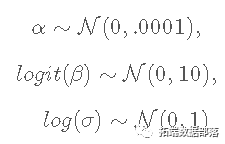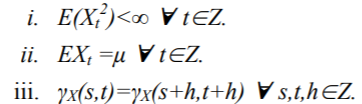热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
项目管理-需求管理
软件项目管理应从源头开始
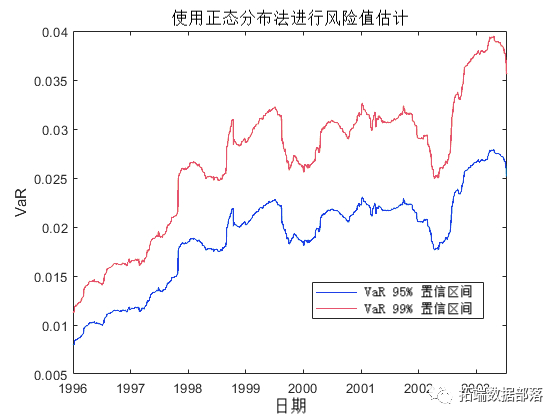
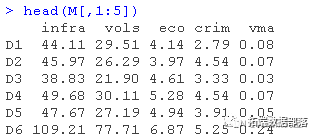
Matlab正态分布、历史模拟法、加权移动平均线 EWMA估计风险价值VaR和回测标准普尔指数 S&P500时间序列
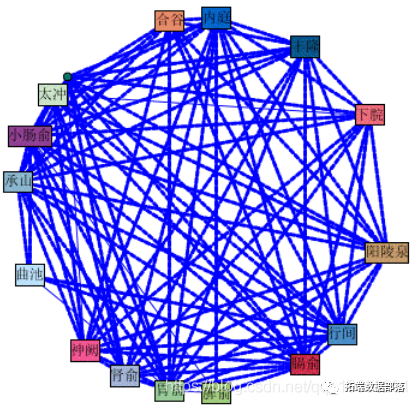
用SPSS Modeler的Web复杂网络对所有腧穴进行关联规则分析
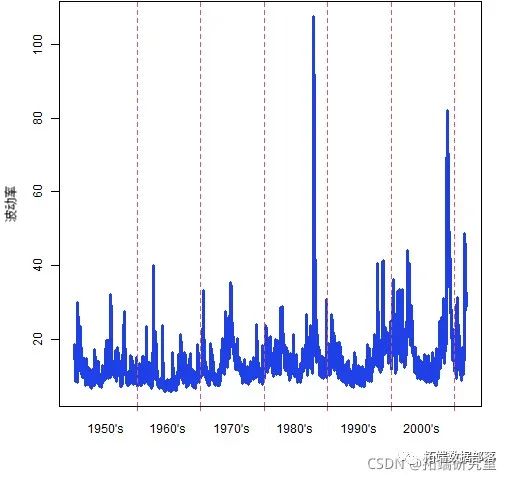
R语言GARCH建模常用软件包比较、拟合标准普尔SP 500指数波动率时间序列和预测可视化
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python金融时间序列模型ARIMA 和GARCH 在股票市场预测应用
R语言梯度提升机 GBM、支持向量机SVM、正则判别分析RDA模型训练、参数调优化和性能比较可视化分析声纳数据
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
【Hive】Hive的两张表关联,使用MapReduce怎么实现?
R语言STAN贝叶斯线性回归模型分析气候变化影响北半球海冰范围和可视化检查模型收敛性
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
【Hive】Hive优化有哪些?
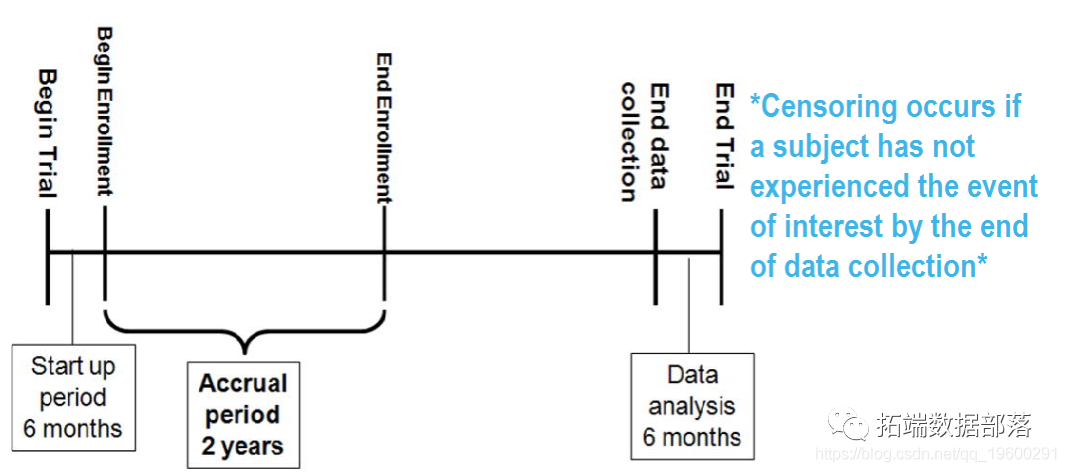
R语言中的生存分析Survival analysis晚期肺癌患者4例
R语言贝叶斯广义线性混合(多层次/水平/嵌套)模型GLMM、逻辑回归分析教育留级影响因素数据
软件体系结构 - 信息系统
R语言KMEANS均值聚类和层次聚类:亚洲国家地区生活幸福质量异同可视化分析和选择最佳聚类数
【Hive】Hive 小文件过多怎么解决?
R语言极值理论 EVT、POT超阈值、GARCH 模型分析股票指数VaR、条件CVaR:多元化投资组合预测风险测度分析
【Hive】数据倾斜怎么解决?
R语言BUGS序列蒙特卡罗SMC、马尔可夫转换随机波动率SV模型、粒子滤波、Metropolis Hasting采样时间序列分析
R语言主成分回归(PCR)、 多元线性回归特征降维分析光谱数据和汽车油耗、性能数据
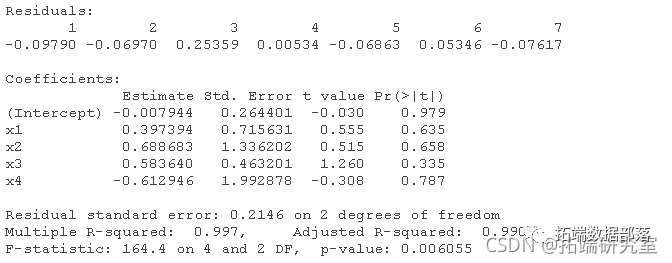
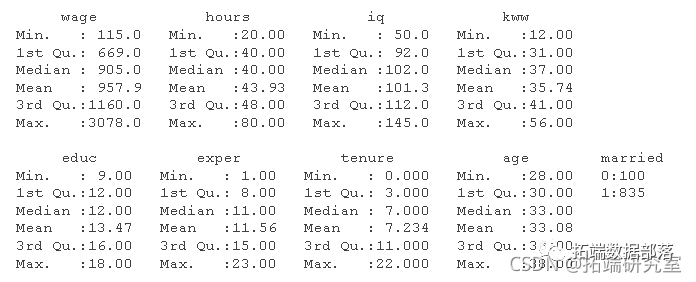
R语言用贝叶斯线性回归、贝叶斯模型平均 (BMA)来预测工人工资
R语言用加性多元线性回归、随机森林、弹性网络模型预测鲍鱼年龄和可视化
matlab数据可视化交通流量分析天气条件、共享单车时间序列数据
PYTHON贝叶斯推断计算:用BETA先验分布推断概率和可视化案例
matlab用马尔可夫链蒙特卡罗 (MCMC) 的Logistic逻辑回归模型分析汽车实验数据
R语言非线性混合效应 NLME模型(固定效应&随机效应)对抗哮喘药物茶碱动力学研究
Stata广义矩量法GMM面板向量自回归 VAR模型选择、估计、Granger因果检验分析投资、收入和消费数据
R语言结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
R语言随机波动率(SV)模型、MCMC的Metropolis-Hastings算法金融应用:预测标准普尔SP500指数
PYTHON在线零售数据关联规则挖掘APRIORI算法数据可视化
开发语言漫谈-rust
R语言矩阵特征值分解(谱分解)和奇异值分解(SVD)特征向量分析有价证券数据
开发语言漫谈-go
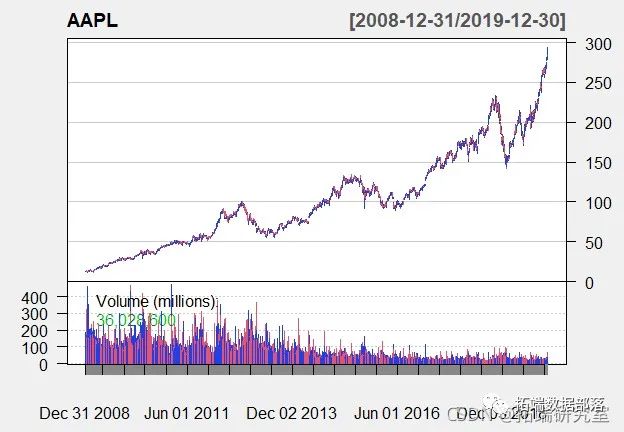
R语言ARIMA-GARCH波动率模型预测股票市场苹果公司日收益率时间序列
Python面板时间序列数据预测:格兰杰因果关系检验Granger causality test药品销售实例与可视化
R语言分布滞后线性和非线性模型(DLNM)分析空气污染(臭氧)、温度对死亡率时间序列数据的影响
开发语言漫谈-python
Zookeeper到底是什么,一篇文章彻底讲清楚
R语言中的时间序列分析模型:ARIMA-ARCH / GARCH模型分析股票价格
python用支持向量机回归(SVR)模型分析用电量预测电力消费
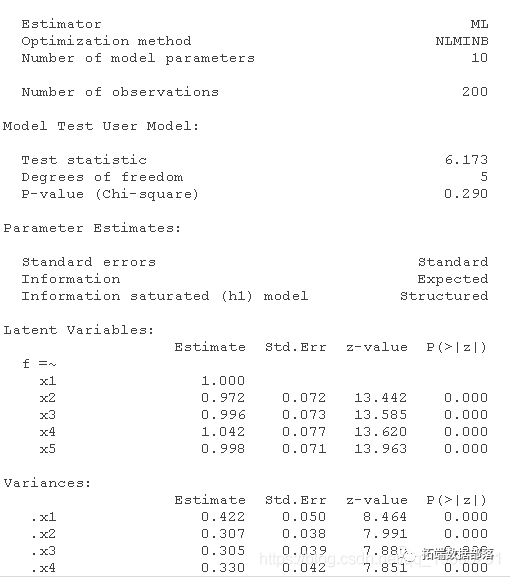
在R语言中实现sem进行结构方程建模和路径图可视化2
在R语言中实现sem进行结构方程建模和路径图可视化1
R语言深度学习KERAS循环神经网络(RNN)模型预测多输出变量时间序列
R语言绘制圈图、环形热图可视化基因组实战:展示基因数据比较
PID算法原理分析及优化