转载请标明出处:http://blog.csdn.net/zhaoyanjun6/article/details/70313790
本文出自【赵彦军的博客】
概念
Groovy是一种动态语言,它和Java类似(算是Java的升级版,但是又具备脚本语言的特点),都在Java虚拟机中运行。当运行Groovy脚本时它会先被编译成Java类字节码,然后通过JVM虚拟机执行这个Java字节码类。
Groovy 配置环境变量
在 Groovy 官网下载压缩包 http://www.groovy-lang.org/download.html
然后解压到本地,如图所示:

- 在
Path环境变量中添加 Groovy 的bin 目录路径,比如:
D:\soft\apache-groovy-sdk-2.4.10\groovy-2.4.10\bin
如图所示:

- 用 CMD 打开命令行,执行:
groovy -version, 如果看到如下提示,就代表配置成功了。
Groovy Version: 2.4.10 JVM: 1.8.0_112 Vendor: Oracle Corporation OS: Windows 10
如图所示:

开发工具 IntelliJ IDEA
groovy 的开发工具是 IntelliJ IDEA
下载地址: https://www.jetbrains.com/idea/
安装完成后,新建项目 ,项目类型选择 Groovy ,然后填写 JDK 、Groovy 的安装目录

新建的项目 Groovy 如下图所示:

在 src 目录下,新建包名 groovy , 并且创建 groovy 源文件 Test.groovy,如下图所示:

现在我们在 Test.groovy 中输出一句 helloword ,代码如下:
package groovy
println( "hello world")运行 Test.groovy 文件 ,如下图所示:

Groovy 语法
基本语法
1、Groovy注释标记和Java一样,支持 //或者/**/
2、Groovy语句可以不用分号结尾。Groovy为了尽量减少代码的输入,确实煞费苦心
3、单引号
单引号” 中的内容严格对应Java中的String,不对 $ 符号进行转义
def s1 = 'i am 100 $ dolloar'
println( s1 )运行结果:
i am 100 $ dolloar4、双引号
双引号”“的内容则和脚本语言的处理有点像,如果字符中有号的话,则它会表达式先求值。
def x = 100
def s1 = "i am $x dolloar"
println( s1 )运行结果:
i am 100 dolloar5、三引号
三个引号”’xxx”’中的字符串支持随意换行 比如
def s1 = ''' x
y
z
f
'''
println(s1)运行结果:
x
y
z
f定义变量
Groovy中支持动态类型,即定义变量的时候可以不指定其类型。Groovy中,变量定义可以使用关键字def。注意,虽然def不是必须的,但是为了代码清晰,建议还是使用def关键字
- 定义一个变量
def a = 1 //定义一个整形
def b = "字符串" //定义一个字符串
def double c = 1.0 //定义一个 double 类型,也可以指定变量类型
定义函数
无返回类型的函数定义,必须使用def关键字 ,最后一行代码的执行结果就是本函数的返回值
//无参函数
def fun1(){
}
//有参函数 , 无需指定参数类型
def fun2( def1 , def2 ){
}如果指定了函数返回类型,则可不必加def关键字来定义函数
String fun3(){
return "返回值"
}
其实,所谓的无返回类型的函数,我估计内部都是按返回Object类型来处理的。毕竟,Groovy 是基于Java 的,而且最终会转成 Java Code 运行在 JVM 上 .
Groovy的函数里,可以不使用return xxx 来设置 xxx 为函数返回值。如果不使用 return 语句的话,则函数里最后一句代码的执行结果被设置成返回值。
def getSomething(){
"getSomething return value" //如果这是最后一行代码,则返回类型为String
1000 //如果这是最后一行代码,则返回类型为Integer
} 除了每行代码不用加分号外,Groovy中函数调用的时候还可以不加括号
例子1:
def s1 = "123"
println(s1)
//或者
println s1 例子2:
println(fun1())
println fun1()
def fun1(){
"你好"
}效果:
你好
你好断言 assert
- 断言变量为空
def s1 = null
assert s1效果如下:

- 断言变量的长度
def s2 = "abc"
assert s2.size()>3效果如下:

如果断言发生,断言后面的代码无法执行
循环 for
- 方式一
for (i = 0; i < 5 ; i++) {
println("测试")
}1、运行结果: 输出5个测试
2、groovy 语法中,注意 i 前面不用指定 int 类型。
- 方式二
for (i in 0..5){
println("hello world")
}这种方式也是一种循环,只不过他输出的是 6 个 hello world , 如果想要输出5个,有3中方式。
第一种方法
for (i in 0..<5){
println("hello world")
}第二种方法
for (i in 0..4){
println("hello world")
}第三种方法
for (i in 1..5){
println("hello world")
}循环 time
times表示从0开始循环到4结束
4.times {
println it
}结果:
0
1
2
3三目运算符
Java 语法
def name
def result = name != null ? name : "abc"
println(result)groovy 语法
def name = 'd'
def result = name?: "abc"捕获异常
捕获所有的 Exception ,有两种写法
//第一种写法,Java 写法
try {
println 5 / 0
} catch (Exception e) {
}
//第二种写法,Groovy 写法
try {
println 5 / 0
} catch (anything) {
}这里的any并不包括Throwable,如果你真想捕获everything,你必须明确的标明你想捕获Throwable
switch
age = 36
def rate
switch (age) {
case 10..26:
rate = 0.05
break
case 27..36:
rate = 0.06
break
case 37..46:
rate = 0.07
break
default:
throw new IllegalArgumentException()
}
println( rate)判断是否为真
Person person
//Java 写法
if (person!= null){
if (person.Data!=null){
println person.Data.name
}
}
//Groovy
println person?.Data?.nameasType
asType 就是数据类型转换
//String 转成 int
def s2 = s1 as int
//String 转成 int
def s3 = s1.asType(Integer)Groovy 数据类型
Groovy中的数据类型主要分2种
一个是Java中的基本数据类型。
另外一个是Groovy中的容器类。
最后一个非常重要的是闭包。
Java 基本类型
def boolean s1 = true
def int s2 = 100
def String s3 = "hello world"
if (s1) {
println("hello world")
}Groovy 容器
List:链表,其底层对应Java中的List接口,一般用ArrayList作为真正的实现类。
Map:键-值表,其底层对应Java中的LinkedHashMap。
Range:范围,它其实是List的一种拓展。
- List
//变量定义:List变量由[]定义,其元素可以是任何对象
def aList = [5,'string',false]
println(aList)
println aList[0] //获取第1个数据
println aList[1] //获取第2个数据
println aList[2] //获取第3个数据
println aList[3] //获取第4个数据
println( "集合长度:" + aList.size())
//赋值
aList[10] = 100 //给第10个值赋值
aList<<10 //在 aList 里面添加数据
println aList
println "集合长度:" + aList.size()效果如下:
[5, string, false]
5
string
false
null
集合长度:3
[5, string, false, null, null, null, null, null, null, null, 100]
集合长度:11- map
def map = [key1: "value1", key2: "value2", key3: "value3"]
println map
//[key1:value1, key2:value2, key3:value3]
println("数据长度:" + map.size())
//数据长度:3
println(map.keySet())
//[key1, key2, key3]
println(map.values())
//[value1, value2, value3]
println("key1的值:" + map.key1)
//key1的值:value1
println("key1的值:" + map.get("key1"))
//key1的值:value1
//赋值
map.put("key4", "value4")
Iterator it = map.iterator()
while (it.hasNext()) {
println "遍历map: " + it.next()
}
//遍历map: key1=value1
//遍历map: key2=value2
//遍历map: key3=value3
//遍历map: key4=value4
map.containsKey("key1") //判断map是否包含某个key
map.containsValue("values1") //判断map是否包含某个values
map.clear() //清除map里面的内容
Set set = map.keySet(); //把 map 的key值转换为 set- range
Range 是 Groovy 对 List 的一种拓展
def range = 1..5
println(range)
//[1, 2, 3, 4, 5]
range.size() //长度
range.iterator() //迭代器
def s1 = range.get(1) //获取标号为1的元素
range.contains( 5) //是否包含元素5
range.last() //最后一个元素
range.remove(1) //移除标号为1的元素
range.clear() //清空列表例子2:
def range = 1..5
println(range)
//[1, 2, 3, 4, 5]
println("第一个数据: "+range.from) //第一个数据
//第一个数据: 1
println("最后一个数据: "+range.to) //最后一个数据
//最后一个数据: 5闭包
闭包,英文叫Closure,是Groovy中非常重要的一个数据类型或者说一种概念了。闭包,是一种数据类型,它代表了一段可执行的代码。
def aClosure = {//闭包是一段代码,所以需要用花括号括起来..
String param1, int param2 -> //这个箭头很关键。箭头前面是参数定义,箭头后面是代码
println"this is code" //这是代码,最后一句是返回值,
//也可以使用return,和Groovy中普通函数一样
} 简而言之,Closure的定义格式是:
def xxx = {paramters -> code}
//或者
def xxx = {无参数,纯code}说实话,从C/C++语言的角度看,闭包和函数指针很像。闭包定义好后,要调用它的方法就是:
闭包对象.call(参数)
或者更像函数指针调用的方法:
闭包对象(参数)
比如:
aClosure.call("this is string",100)
//或者
aClosure("this is string", 100)实例演练,源码如下
def fun1 = {
p1 ->
def s = "我是一个闭包," + p1
}
println(fun1.call()) //闭包 调用方式1
println(fun1.call("我是一个参数")) //闭包 调用方式2
println(fun1("我是一个参数2"))运行结果如下:
我是一个闭包,null
我是一个闭包,我是一个参数
我是一个闭包,我是一个参数2闭包没定义参数的话,则隐含有一个参数,这个参数名字叫it,和this的作用类似。it代表闭包的参数。
def fun2 = {
it-> "dsdsd"
}
println( fun2.call())如果在闭包定义时,采用下面这种写法,则表示闭包没有参数!
def fun3 = {
-> "dsdsd"
}
println( fun3.call())如果调用 fun3 的时候传递参数就会报错,比如
fun3.call("d") //执行这个方法的时候就会报错省略圆括号
def list = [1,2,3] //定义一个List
//调用它的each,这段代码的格式看不懂了吧?each是个函数,圆括号去哪了?
list.each {
println(it)
}
//结果
/**
* 1
* 2
* 3
*/each函数调用的圆括号不见了!原来,Groovy中,当函数的最后一个参数是闭包的话,可以省略圆括号。比如
def fun(int a1,String b1, Closure closure){
//dosomething
closure() //调用闭包
}
那么调用的时候,就可以免括号!
fun (4, "test", {
println"i am in closure"
})
注意,这个特点非常关键,因为以后在Gradle中经常会出现这样的代码:
task hello{
doLast{
println("hello world")
}
}省略圆括号虽然使得代码简洁,看起来更像脚本语言
Java 属性
Groovy中可以像Java那样写package,然后写类。比如我们在 Person.groovy 文件中编写Java 代码,如下所示:

然后我们新建 Test.groovy 类,写测试工程,如下所:

运行结果如下所示:
Person{name='zhaoyanjun', age=20}当然,如果不声明public/private等访问权限的话,Groovy中类及其变量默认都是public的.
再识 Groovy
Java中,我们最熟悉的是类。但是我们在Java的一个源码文件中,不能不写class(interface或者其他….),而Groovy可以像写脚本一样,把要做的事情都写在xxx.groovy中,而且可以通过groovy xxx.groovy直接执行这个脚本。这到底是怎么搞的?
既然是基于Java的,Groovy会先把xxx.groovy中的内容转换成一个Java类。
在运行完 Test.groovy 后,发现会产生一个 out 目录,在这个目录里面可以看到 Person.groovy 、Test.groovy 被转换成了 .class 文件,如下图所示:

编译完成后,.groovy 文件都被转换成了 .class 文件,每个 .class 文件都默认有静态 main 方法。每一个脚本都会生成一个static main函数。这样,当我们groovytest.groovy的时候,其实就是用java去执行这个main 函数。
脚本中的所有代码都会放到run函数中。比如,println ‘Groovy world’,这句代码实际上是包含在run函数里的。
Test 继承 Script 类。
Script 类
在 groovy 的库文件中,可以看到 Script 类是一个抽象类,继承 GroovyObjectSupport 类,如下所示

脚本变量的作用域
在 Test.groovy 里面定义变量 s1 , 方法 fun1 , 同时在 fun1 方法中输出 s1 , 代码如下:

一运行就报错,错误如下

通过 out 目录,查看 Test.class 类如下:

可以看到在 s1 变量定义在 run 方法中,相当于局部变量,fun1 方法自然无法访问 s1 .
解决方法也很简单 ,就是把 s1 的 def 去掉,代码如下:

通过 out 目录,查看 Test.class 类如下:

上图中 s1 也没有被定义成 Test 的成员函数,而是在 run 的执行过程中,将 s1 作为一个属性添加到 Test 实例对象中了。然后在print s1 中,先获取这个属性。但是从反编译的实际上看,s1 并没有成为 Test.class 的成员变量,其他脚本却无法访问 s1 变量 。
怎样使 s1 彻彻底底变成 Test 的成员变量?
答案也很简单在 s1 前面加上 @Field 字段
@Field s1 = "123" //s1 彻彻底底变成 Test 的成员变量反编译效果如下:

JSON 操作
JsonOutput 类把对象转换成 json字符串。
JsonSlurper 类把 json 字符串转换成对象
定义 Person 实体类
public class Person {
String name;
int age;
}
对象转json 、 json 转对象
Person person = new Person();
person.name = "zhaoyanjun"
person.age = 27
//把对象转换为 json 字符串
def json =JsonOutput.toJson(person)
println(json)
JsonSlurper jsonSlurper = new JsonSlurper()
//把字符串转换为对象
Person person1 = jsonSlurper.parseText(json)
println( person1.name )运行效果如下图:
{"age":27,"name":"zhaoyanjun"}
zhaoyanjun集合对象转json 、json 转集合对象
Person person = new Person();
person.name = "zhaoyanjun"
person.age = 27
Person person1 = new Person();
person1.name = "zhaoyanjun2"
person1.age = 28
def list = [person,person1]
//把集合对象转换为 json 字符串
def jsonArray =JsonOutput.toJson(list)
println(jsonArray)
JsonSlurper jsonSlurper = new JsonSlurper()
//把字符串转换为集合对象
List<Person> list2 = jsonSlurper.parseText(jsonArray)
println( list2.get(1).name )运行结果为:
[{"age":27,"name":"zhaoyanjun"},{"age":28,"name":"zhaoyanjun2"}]
zhaoyanjun2I/O 操作
Groovy的 I/O 操作是在原有Java I/O操作上进行了更为简单方便的封装,并且使用Closure来简化代码编写。虽然比Java看起来简单,但要理解起来其实比较难。
文本文件读
在电脑上新建一个文本文件 test.txt , 内容如下:
今天是星期五
天气很好
明天就要放假了
下面用 groovy 读取里面的文本
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath) ;
file.eachLine {
println it
}你没有看错,就是这么简单,groovy 的文件读取操作简单到令人发指。但是这不够,还有跟令人发指的操作,比如:
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath) ;
println file.text //输出文本看到这里,发现 Groovy 操作文件比 Java 简单了 100 倍,苍天啊!
更多用法
- 指定编码格式
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath);
//指定编码格式为 utf-8
file.eachLine("utf-8") {
println it //读取文本
}- 把小写转成大写
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath);
file.eachLine {
println( it.toUpperCase() )
}
文本文件写
- 方式1
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath);
file.withPrintWriter {
it.println("测试")
it.println("hello world")
}- 方式2
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath);
def out = file.newPrintWriter();
out.println("测试")
out.println("hello world")
out.flush()
out.close()效果如下:

文件夹操作
- 遍历文件夹中的文件、文件
def filePath = "C:/Users/T/Desktop/123"
def file = new File(filePath);
//遍历 123 文件夹中文件夹
file.eachDir {
println "文件夹:"+it.name
}
//遍历 123 文件夹中的文件
file.eachFile {
println "文件:"+ it.name
}
效果如下:
文件夹:1
文件夹:2
文件夹:3
文件:1
文件:2
文件:3
文件:4.txt深度遍历文件
def filePath = "e:/"
def file = new File(filePath);
//深度遍历目录,也就是遍历目录中的目录
file.eachDirRecurse {
println it.name
}
//深度遍历文件,包括目录和文件
file.eachFileRecurse {
println it.path
}
InputStream
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath) ;
def ism = file.newInputStream()
//操作ism,最后记得关掉
ism.close
使用闭包操作 inputStream,以后在Gradle里会常看到这种搞法
def filePath = "C:/Users/T/Desktop/test.txt"
def file = new File(filePath) ;
file.withInputStream {ism->
// 操作ism. 不用close。Groovy会自动替你close
ism.eachLine {
println it //读取文本
}
}确实够简单,令人发指。我当年死活也没找到withInputStream是个啥意思。所以,请各位开发者牢记Groovy I/O操作相关类的SDK地址:
- java.io.File: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/File.html
- java.io.InputStream: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/InputStream.html
- java.io.OutputStream: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/OutputStream.html
- java.io.Reader: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/Reader.html
- java.io.Writer: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/Writer.html
- java.nio.file.Path: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/nio/file/Path.html
xml 解析
在java中解析xml是非常繁琐的,通常需要用10行代码去解析5行的xml文件,非常不经济。在groovy 中解析xml 就很方便了。
实例1 解析简单xml
比如下面一段xml
<?xml version="1.0"?>
<langs type="current">
<language>Java</language>
<language>Groovy</language>
<language>JavaScript</language>
</langs>
groovy 解析如下:
//获取 xml 文件的 langs 节点
def langs = new XmlParser().parse("C:/Users/T/Desktop/test.xml")
//获取type 字段的值
def type = langs.attribute("type")
println type
langs.language.each{
println it.text()
}结果如下:
current
Java
Groovy
JavaScript实例2 解析复杂 xml
xml 如下图所示:
<?xml version="1.0" encoding="UTF-8"?>
<metadata>
<groupId>com.yiba.sdk</groupId>
<artifactId>weshareWiFiSDk</artifactId>
<version>2.3.3</version>
<versioning>
<latest>2.3.3</latest>
<versions>
<version>2.2.7</version>
<version>2.3.0</version>
<version>2.3.1</version>
<version>2.3.2</version>
<version>2.3.3</version>
</versions>
</versioning>
</metadata>解析代码如下:
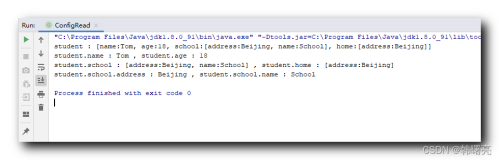
//获取metadata节点
def metadata = new XmlParser().parse("C:/Users/T/Desktop/test1.xml")
//获取metadata下面的 groupId 属性值
def groupId = metadata.groupId.text()
//获取metadata下面的 artifactId 属性值
def artifactId = metadata.artifactId.text()
//获取metadata下面的 version 属性值
def version = metadata.version.text()
println groupId + " " + artifactId + " " + version
//获取metadata下面的 versioning 节点
def versioning = metadata.versioning
//获取versioning 下面的 latest 属性值
println versioning.latest.text()
//获取versioning 下面的 versions 节点
def versions = versioning.versions
versions.version.each{
//遍历 versions 下面的version 值
println "version" + it.text()
}结果如下:
com.yiba.sdk weshareWiFiSDk 2.3.3
2.3.3
version2.2.7
version2.3.0
version2.3.1
version2.3.2
version2.3.3
个人微信号:zhaoyanjun125 , 欢迎关注