0. 大背景
全球No.1搜索引擎公司谷歌(Google)面临每天海量搜索引擎数据的问题,经过长时间的实践积累,
谷歌形成了自己的大数据框架,但是并没有开源,而是发表了一篇论文,阐述了自己的思想,在论文中
提到了MapReduce的方法。这篇论文,被Doug Cutting也就是后来的Hadoop之父所关注,引起了他极大的兴趣。
因为,这个时候,他正在致力于一个项目,该项目需要多任务并行处理大量的数据,他和伙伴努力了多次,结果都不理想。
于是,Doug和他的团队决定基于Google的MapReduce的思想重新开发一个框架。
经过一段时间的努力,于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入Hadoop项目作为Apache基金会的项目。
Hadoop这个名字不是一个缩写,而是一个虚构的名字。该项目的创建者,Doug Cutting解释Hadoop的得名 :“这个名字是我孩子给一个棕黄色的大象玩具命名的。
学习Hadoop建议的参考书:Hadoop权威指南,目前中文版到第3版,英文版已经到Edition 4, 该书的作者Tom White是Hadoop创始团队的核心成员,是Hadoop委员会的成员。
大牛级的人物!!
2. 生态体系概览
经过长时间的发展,Hadoop已经形成了自己的生态体系。
有些框架是诸如一些大公司如Yahoo, Facebook团队所开发的,下面我们来看一下它的生态图:
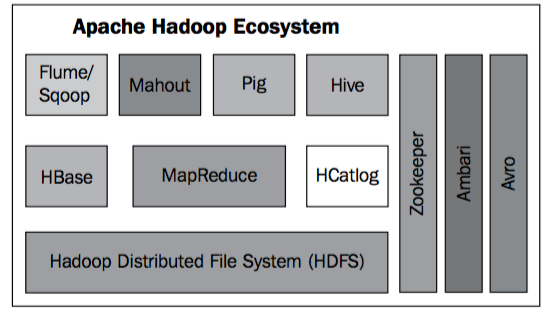
从上图可以看出,Apache Hadoop包含如下主要组件:
* HDFS and MapReduce: 这是Hadoop的核心框架(也就是Doug Cutting和他的团队所开发的)
* HBase, Hive, Pig: 这3个框架主要负责数据存储和查询,分别由不同公司开发,我们后面会介绍到
* Flume, Sqoop: 负责数据的导入/导出
* Mahout: 机器学习和分析
* Zookeeper: 分布式协调
* Ambari: 集群管理
* Avro: 数据存储和序列化
* HCatalog: 元数据管理
3. 各组件分别介绍
1)Apache HBase
由于HDFS是只能追加数据的文件系统,它不允许数据的修改。
所以,Apache HBase由此而诞生。
HBase是一个分布式的,随机访问的,面向列的数据库系统。
HBase在HDFS的顶层运行,它允许应用程序开发人员直接读写HDFS数据。
但是,唯一的缺陷在于:HBase并不支持SQL语句。
所以,它也是NOSQL数据库的一种。
然而,它提供了基于命令行的界面以及丰富的API函数来更新数据。
需要提到的是:HBase中的数据是以键值对的形式存储在HDFS文件系统中的。
2)Apache Pig
Apache Pig由Yahoo开发,它提供了在MapReduce之上的抽象层。
它提供了一种叫做Pig Latin的被用来创建MapReduce程序的语言。
Pig Latin被程序员用来编写程序,分析数据,通过它可以创建并行执行的任务,
从而可以更有效地利用Hadoop的分布式集群。
Pig有很多成功的大公司项目案例,如:eBay, LinkedIn, Twitter。
3)Apache Hive
Hive被用来作为大数据的数据仓库,它也使用HDFS文件系统来存储数据。
在Hive中我们不编写MapReduce程序,因为Hive提供了一种类SQL语言,叫做HiveQL,
这让开发者能够迅速写出类似关系型数据SQL查询的点对点(ad-hoc)查询。
4)Apache ZooKeeper
Hadoop通过节点(nodes)的方式提供相互间的通信。
ZooKeeper便是被用来管理这些节点的,它被用来协调各个节点。
除了管理节点以外,它还维护一些配置信息,并且对分布式系统的服务进行分组。
ZooKeeper可以独立于Hadoop来运行,而不像生态系统中的其它组件一样。
由于ZooKeeper是基于内存来管理信息的,因此它的性能相对来说还是挺高的。
5)Apache Mahout
Mahout是一个开源的机器学习库,它能使Hadoop用户高效地进行诸如数据分析,数据挖掘以及集群等一些列操作。
Mahout对于大数据集特别高效,它提供的算法经过性能优化能够在HDFS文件系统上高效地运行MapReduce框架。
6)Apache HCatalog
HCatalog在Hadoop的顶层提供元数据的管理服务。
所有运行在Hadoop之上的软件能够使用HCatalog在HDFS文件系统中存储它们的计划(schema)。
HCatalog以REST API的方式使第三方的软件能够创建,编辑和暴露表格的定义以及生成的元数据。
因此,我们通过HCatalog并不需要知道数据的物理位置在那里。
HCatalog提供了数据定义语句(DDL),通过它们MapReduce, Pig, Hive等的工作任务将以队列的形式等待执行,如有需要
还可以监控它们各自的进度。
7)Apache Ambari
Ambari被用来监控Hadoop集群。
它提供了一些列特性,诸如:安装向导,系统警告,集群管理,任务性能等。
Ambari也提供了RESTful的API以便与其他软件进行整合。
8)Apache Avro
如何用过其它编程语言来有效地组织Hadoop的大数据,Avro便是为了这个目的而生。
Avro提供了各个节点上的数据的压缩以及存储。
基于Avro的数据存储能够轻松地被很多脚本语言诸如Python,或者非脚本语言如Java来读取。
另外,Avro还可被用来MapReduce框架中数据的序列化。
9)Apache Sqoop
Sqoop被用来在Hadoop中高效地加载大数据集,例如它允许开发人员轻松地从一些数据源,如:
关系型数据库,企业级数据仓库,甚至应用程序导入/导出数据数据。
10)Apache Flume
Flume常被用来进行日志的聚合操作,它被用来作为ETL(Extract-Transform-Load) - 解转加(解压-转换-加载)工具来使用。
好了,Hadoop生态体系以及它们的主要组件就大致介绍到这里了!

