一、场景以及需求
为了让大家本文介绍的主题有一个比较直观的认识,我们给出一个具体的应用场景。一个跨国公司开发一套统一的办公系统,供遍布全球的所有分公司使用。客户端的UI采用Smart Client (Windows Forms应用),而主要的业务逻辑均通过WCF服务的形式提供。我们将承载业务服务的服务器成为应用服务器,如右图(点击看大图)所示,应用服务器部属于中国境内(东8区)。主要的客户端(分公司)分布于三个主要的国家和地区:北美、欧州和澳洲。
不论客户端和服务器之间,还是不同的客户端之间所处的时区均不相同,在进行时间处理的时候就会遇到一些麻烦:某个客户端通过服务调用获取的时间值应该基于哪个时区?对于这个问题,不同的场景可能有不同的要求。在大部分情况下,我们希望获取的时间值就是基于客户端的本地时区。不过也有些场景我们希望获取的时间值对应的时区是描述对象基于的那个时区。比如说,美国分公司于当地时间9月1号早8点举行开业典礼,欧洲分公司员工读取这条信息就没有必要将时间转换成基于本地时区的时间。
不过,本文不考虑这种情况,我们的最终要求是:客户端应用根本不用考虑时区问题,就像是一个单纯的本地应用一样。客户端调用服务传入的时间是DateTimeKind.Local时间或者DateTimeKind.Unspecified时间,同理通过服务调用返回的时间也应该是基于客户端所在时区的时间。
二、解决方案实现原理
现在我们就来谈谈如何解决上面提出的问题。既然时区的处理不能在客户端做,换言之就必须在服务端实现。我们的一个前提是:在数据库中不存储时区的任何信息。在这样一个前提下实现上述的目标,需要解决两个问题:时间的保存和时间获取。
 在时间的保存方面,既然数据库中能保存任何时区偏移之类的信息。在这种情况下,我们必须让所有保存在数据库中的时间都是基于同一个时区。我们可以选择应用服务器所在的时区,也可以直接采用UTC时间。我们的方案采用后者,即数据库所有时间保存为UTC时间 。
在时间的保存方面,既然数据库中能保存任何时区偏移之类的信息。在这种情况下,我们必须让所有保存在数据库中的时间都是基于同一个时区。我们可以选择应用服务器所在的时区,也可以直接采用UTC时间。我们的方案采用后者,即数据库所有时间保存为UTC时间 。
时间在数据库中的存储形式确定了,现在又出现一个问题:客户端传来的时间为客户端所在时区的当地时间,服务端接收到客户端发送的时间后,需要基于客户端相应时区转换成UTC时间才能保存到数据库。那么,服务端如何获取客户端所在的时区信息呢?将其作为服务操作的参数肯定是不可取的。
如果你看过我之前的WCF系列文章,可能会记得我有一篇介绍如何通过WCF扩展实现在客户端和服务端之间传递上下文的文章:《通过WCF Extension实现Context信息的传递》。在这篇文章中我通过WCF扩展实现了将可户端的Culture和UICulture自动传向了服务端,从而确保两边保存一样的语言文化环境上下文。如果我们能够将基于客户端本地的TimeZoneInfo作为上下文进行传递,就能解决服务端对客户端的时区识别问题了。
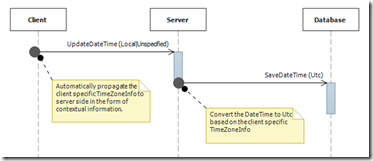
关于保存时间的处理大体可以通过上面的序列图(点击看大图)来描述。客户端将基于本地时区的DateTimeKind.Local或者DateTimeKind.Unspecified时间作为输入操作调用某个服务,与此同时,本地的TimeZoneInfo序列化后作为上下文传递到服务端。服务端接将接收到的时间,根据接收到TimeZoneInfo上下文转换成DateTimeKind.Utc时间,并保存到数据库中。
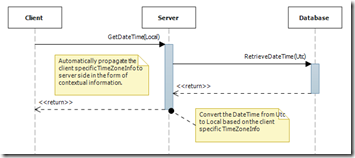
`当客户端调用服务获取某个时间的时候,本地的同样作为上下文信息被传递到服务端。借助于这个TimeZoneInfo,服务端可以将数据库中以UTC形式保存的时间转换成基于客户端时区的DateTimeKind.Local时间。下图(点击看大图)所示的序列图反映了这个过程。
三、TimeZoneInfo的序列化问题
在《谈谈你最熟悉的System.DateTime[上篇]》对TimeZoneInfo这个类进行介绍中,我说该类是可以被序列化的,序列化对于解决跨时区问题很重要。就是因为我们需要将TimeZoneInfo作为上下文在客户端和服务端进行传递,换言之,就是将TimeZoneInfo对象进行序列化,将序列化后的内容放入出栈消息(Outgoing Message)的消息报头(Message Header)中。
不过关于TimeZoneInfo对象序列化,我们一般并不会真正地将整个TimeZoneInfo对象交给序列化器去做序列化,而是利用定义在TimeZoneInfo中的两个特殊的方法来进行序列化和反序列化的工作。一个是实例方法ToSerializedString,将TimeZoneInfo转换成序列化后的一个字符串;另一个则静态方法FromSerializedString,对序列化后的字符转进行反序列化生成TimeZoneInfo对象。这两个方法的定义如下:
1: [Serializable]
2: public sealed class TimeZoneInfo
3: {
4: //Others
5: public static TimeZoneInfo FromSerializedString(string source);
6: public string ToSerializedString();
7: }
下面的代码演示了通过上述的这两个方法对TimeZoneInfo的序列化和反序列化的实现:
1: string serializedString = TimeZoneInfo.Local.ToSerializedString();
2: Console.WriteLine("SerializedString: {0}\n", serializedString);
3: TimeZoneInfo deserializedTimeZone = TimeZoneInfo.FromSerializedString(serializedString);
4: Console.WriteLine("deserializedTimeZone.Equals(TimeZoneInfo.Local) ? {0}", deserializedTimeZone.Equals(TimeZoneInfo.Local));
5: Console.WriteLine("deserializedTimeZone == TimeZoneInfo.Local ? {0}", deserializedTimeZone == TimeZoneInfo.Local);
下面是输出结果,从中我们看出最终被序列化后的文本的内容。此外,输出结果也反映两个另一个信息:两个包含时区信息的TimeZoneInfo对象,调用Equals方法和使用==操作符得到不一样的结果。个人觉得这是微软作得不太到位的地方。
1: SerializedString: China Standard Time;480;(UTC+08:00) Beijing, Chongqing, Hong Kong, Urumqi;China Standard Time;China Daylight Time;;
2:
3: deserializedTimeZone.Equals(TimeZoneInfo.Local) ? True
4: deserializedTimeZone == TimeZoneInfo.Local ? False
关于这个分布式系统中跨时区问题的讨论暂时就到这里,在下篇中我将给出一个完整的例子,相信会使你对本文给出的解决方案有一个深刻的认识。