云计算和大数据
http://www.cstor.cn/textdetail_6067.html

大数据和云计算两者的区别
http://www.csdn.net/article/2015-09-11/2825674 盘点大数据生态圈,那些繁花似锦的开源项目
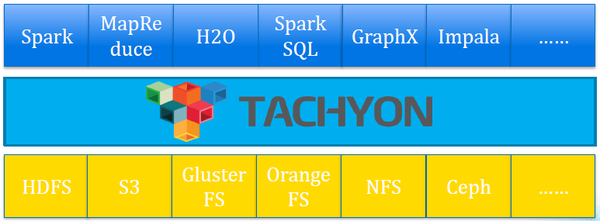
云存储技术
开源的分布式文件存诸系统有GlusterFS、Hadoop 、FastDFS 等等非常多
Tachyon http://www.csdn.net/article/2015-06-25/2825056
Ceph与Swift
Ceph用C++编写而Swift用Python编写,性能上应当是Ceph占优。但是与Ceph不同,Swift专注于对象存储,作为OpenStack组件之一经过大量生产实践的验证,与OpenStack结合很好,目前不少人使用Ceph为OpenStack提供块存储,但仍旧使用Swift提供对象存储。
Swift的开发者曾写过文章对比Ceph和Swift: Ceph and Swift: Why we are not fighting.
Ceph与HDFS
Ceph对比HDFS优势在于易扩展,无单点。HDFS是专门为Hadoop这样的云计算而生,在离线批量处理大数据上有先天的优势,而Ceph是一个通用的实时存储系统。虽然Hadoop可以利用Ceph作为存储后端(根据Ceph官方的教程死活整合不了,自己写了个简洁的步骤Running-Hadoop-on-CEPH),但执行计算任务上性能还是略逊于HDFS(时间上慢30%左右 Haceph: Scalable Meta- data Management for Hadoop using Ceph)。
http://www.chinaz.com/program/2015/0504/403143.shtml 历经十年:关于Ceph现状与未来的一些思考
http://www.oschina.net/project/tag/104/storage 不同类别的存储系统开源项目
Hadoop生态系统
http://blog.csdn.net/woshiwanxin102213/article/details/19688393
Hadoop是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。
Hadoop的核心是HDFS和Mapreduce,hadoop2.0还包括YARN。
下图为hadoop的生态系统:

Spark / Storm
http://www.zhihu.com/question/26568496
http://developer.51cto.com/art/201412/460116.htm
Spark基于这样的理念,当数据庞大时,把计算过程传递给数据要比把数据传递给计算过程要更富效率。每个节点存储(或缓存)它的数据集,然后任务被提交给节点。所以这是把过程传递给数据。这和Hadoop map/reduce非常相似,除了积极使用内存来避免I/O操作,以使得迭代算法(前一步计算输出是下一步计算的输入)性能更高。Shark只是一个基于Spark的查询引擎(支持ad-hoc临时性的分析查询)
而Storm的架构和Spark截然相反。Storm是一个分布式流计算引擎。每个节点实现一个基本的计算过程,而数据项在互相连接的网络节点中流进流出。和Spark相反,这个是把数据传递给过程。
两个框架都用于处理大量数据的并行计算。
Storm在动态处理大量生成的“小数据块”上要更好(比如在Twitter数据流上实时计算一些汇聚功能或分析)。
Spark工作于现有的数据全集(如Hadoop数据)已经被导入Spark集群,Spark基于in-memory管理可以进行快讯扫描,并最小化迭代算法的全局I/O操作。
http://blog.csdn.net/hguisu/article/details/8454368 使用Storm实现实时大数据分析
大数据的生态系统
http://www.csdn.net/article/2012-12-21/2813066-database-road-map 一张图让你知道大数据的生态系统
http://www.aboutyun.com/thread-11944-1-1.html 开源大数据(hadoop生态系统、流式处理系统等)处理工具汇总
开源云
http://www.oschina.net/news/54700/most-popular-opensource-cloud-projects 2014 上半年最受欢迎的开源云项目集合
http://www.chinacloud.cn/show.aspx?id=19743&cid=22 盘点Linux下的开源云平台
OpenStack Docker KVM
实时数据流处理
http://www.csdn.net/article/2014-06-12/2820196-Storm 实时计算,流数据处理系统简介与简单分析
http://www.csdn.net/article/2014-12-09/2823038 在云上搭建大规模实时数据流处理系统
http://tech.it168.com/a2014/0730/1651/000001651470_all.shtml LinkedIn大数据专家深度解读日志的意义
Appendix
https://en.wikipedia.org/wiki/NoSQL
http://docs.openstack.org/developer/swift/
