Lucene 源码剖析
1 目录
2 Lucene是什么
2.1.1 强大特性
2.1.2 API组成-
2.1.3 Hello World!
2.1.4 Lucene roadmap
3 索引文件结构
3.1 索引数据术语和约定 -
3.1.1 术语定义
3.1.2 倒排索引(inverted indexing)
3.1.3 Fields的种类
3.1.4 片断(segments)
3.1.5 文档编号(document numbers)
3.1.6 索引结构概述
3.1.7 索引文件中定义的数据类型 -
3.2 索引文件结构
3.2.1 索引文件概述
3.2.2 每个Index包含的文件
3.2.2.1 Segments文件
3.2.2.2 Lock文件
3.2.2.3 Deletable文件
3.2.2.4 Compound文件(.cfs)
3.2.3 每个Segment包含的文件
3.2.3.1 Field信息(.fnm)
3.2.3.2 Field数据(.fdx和.fdt)
3.2.3.3 Term字典(.tii和.tis)
3.2.3.4 Term频率数据(.frq)
3.2.3.5 Positions位置信息数据(.prx)
3.2.3.6 Norms调节因子文件(.nrm)-
3.2.3.7 Term向量文件 -
3.2.3.8 删除的文档 (.del)
3.3 局限性(Limitations)
4 索引是如何创建的
4.1 索引创建示例
4.2 索引创建类IndexWriter
4.2.1 org.apache.lucene.index.IndexWriter
4.2.2 org.apache.lucene.index.DocumentsWriter
4.2.3 org.apache.lucene.index.SegmentMerger -
5 数据是如何存储的
5.1 数据存储类Directory
5.1.1 org.apache.lucene.store.Directory
5.1.2 org.apache.lucene.store.FSDirectory
5.1.3 org.apache.lucene.store.RAMDirectory
5.1.4 org.apache.lucene.store.IndexInput
5.1.5 org.apache.lucene.store.IndexOutput
6 文档内容是如何分析的
6.1 文档分析类Analyzer
6.1.1 org.apache.lucene.store.Analyzer
6.1.2 org.apache.lucene.store.StandardAnalyzer -
7 如何给文档评分
7.1 文档评分类Similarity
7.1.1 org.apache.lucene.search.Similarity
7.2 Similarity评分公式
1Lucene是什么
Apache Lucene是一个高性能(high-performance)的全能的全文检索(full-featured text search engine)的搜索引擎框架库,完全(entirely)使用Java开发。它是一种技术(technology),适合于(suitable for)几乎(nearly)任何一种需要全文检索(full-text search)的应用,特别是跨平台(cross-platform)的应用。

Lucene 通过一些简单的接口(simple API)提供了强大的特征(powerful features):
可扩展的高性能的索引能力(Scalable, High-Performance Indexing)
ü 超过20M/分钟的处理能力(Pentium M 1.5GHz)
ü 很少的RAM内存需求,只需要1MB heap
ü 增量索引(incremental indexing)的速度与批量索引(batch indexing)的速度一样快
ü 索引的大小粗略(roughly)为被索引的文本大小的20-30%
强大的精确的高效率的检索算法(Powerful, Accurate and Efficient Search Algorithms)
ü 分级检索(ranked searching)能力,最好的结果优先推出在前面
ü 很多强大的query种类:phrase queries, wildcard queries, proximity queries, range queries等
ü 支持域检索(fielded searching),如标题、作者、正文等
ü 支持日期范围检索(date-range searching)
ü 可以按任意域排序(sorting by any field)
ü 支持多个索引的检索(multiple-index searching)并合并结果集(merged results)
ü 允许更新和检索(update and searching)并发进行(simultaneous)
跨平台解决方案(Cross-Platform Solution)
ü 以Open Source方式提供并遵循Apache License,允许你可以在即包括商业应用也包括Open Source程序中使用Lucene
ü 100%-pure Java(纯Java实现)
ü 提供其他开发语言的实现版本并且它们的索引文件是兼容的
Lucene API被分成(divide into)如下几种包(package)
· org.apache.lucene.analysis
定义了一个抽象的Analyser API,用于将text文本从一个java.io.Reader转换成一个TokenStream,即包括一些Tokens的枚举容器(enumeration)。一个TokenStream的组成(compose)是通过在一个Tokenizer的输出的结果上再应用TokenFilters生成的。一些少量的Analysers实现已经提供,包括StopAnalyzer和基于语法(gramar-based)分析的StandardAnalyzer。
· org.apache.lucene.document
提供一个简单的Document类,一个document只不过包括一系列的命名了(named)的Fields(域),它们的内容可以是文本(strings)也可以是一个java.io.Reader的实例。
· org.apache.lucene.index
提供两个主要类,一个是IndexWriter用于创建索引并添加文档(document),另一个是IndexReader用于访问索引中的数据。
· org.apache.lucene.search
提供数据结构(data structures)来呈现(represent)查询(queries):TermQuery用于单个的词(individual words),PhraseQuery用于短语,BooleanQuery用于通过boolean关系组合(combinations)在一起的queries。而抽象的Searcher用于转变queries为命中的结果(hits)。IndexSearcher实现了在一个单独(single)的IndexReader上检索。
· org.apache.lucene.queryParser
使用JavaCC实现一个QueryParser。
· org.apache.lucene.store
定义了一个抽象的类用于存储呈现的数据(storing persistent data),即Directory(目录),一个收集器(collection)包含了一些命名了的文件(named files),它们通过一个IndexOutput来写入,以及一个IndexInput来读取。提供了两个实现,FSDirectory使用一个文件系统目录来存储文件,而另一个RAMDirectory则实现了将文件当作驻留内存的数据结构(memory-resident data structures)。
· org.apache.lucene.util
包含了一小部分有用(handy)的数据结构,如BitVector和PriorityQueue等。
2Hello World!
下面是一段简单的代码展示如何使用Lucene来进行索引和检索(使用JUnit来检查结果是否是我们预期的):
1![]() // Store the index in memory:
// Store the index in memory:
2![]() Directory directory = new RAMDirectory();
Directory directory = new RAMDirectory();
3![]() // To store an index on disk, use this instead:
// To store an index on disk, use this instead:
4![]() //Directory directory = FSDirectory.getDirectory(”/tmp/testindex”);
//Directory directory = FSDirectory.getDirectory(”/tmp/testindex”);
5![]() IndexWriter iwriter = new IndexWriter(directory, analyzer, true);
IndexWriter iwriter = new IndexWriter(directory, analyzer, true);
6![]() iwriter.setMaxFieldLength(25000);
iwriter.setMaxFieldLength(25000);
7![]() Document doc = new Document();
Document doc = new Document();
8![]() String text = “This is the text to be indexed.“;
String text = “This is the text to be indexed.“;
9![]() doc.add(new Field(“fieldname“, text, Field.Store.YES,
doc.add(new Field(“fieldname“, text, Field.Store.YES,
10![]() Field.Index.TOKENIZED));
Field.Index.TOKENIZED));
11![]() iwriter.addDocument(doc);
iwriter.addDocument(doc);
12![]() iwriter.optimize();
iwriter.optimize();
13![]() iwriter.close();
iwriter.close();
14![]()
15![]() // Now search the index:
// Now search the index:
16![]() IndexSearcher isearcher = new IndexSearcher(directory);
IndexSearcher isearcher = new IndexSearcher(directory);
17![]() // Parse a simple query that searches for ”text”:
// Parse a simple query that searches for ”text”:
18![]() QueryParser parser = new QueryParser(“fieldname“, analyzer);
QueryParser parser = new QueryParser(“fieldname“, analyzer);
19![]() Query query = parser.parse(“text“);
Query query = parser.parse(“text“);
20![]() Hits hits = isearcher.search(query);
Hits hits = isearcher.search(query);
21![]() assertEquals(1, hits.length());
assertEquals(1, hits.length());
22![]() // Iterate through the results:
// Iterate through the results:
23![]()
![]() for (int i = 0; i < hits.length(); i++)
for (int i = 0; i < hits.length(); i++) ![]() {
{
24![]() Document hitDoc = hits.doc(i);
Document hitDoc = hits.doc(i);
25![]() assertEquals(“This is the text to be indexed.“, hitDoc.get(“fieldname“));
assertEquals(“This is the text to be indexed.“, hitDoc.get(“fieldname“));
26![]() }
}
27![]() isearcher.close();
isearcher.close();
28![]() directory.close();
directory.close();
为了使用Lucene,一个应用程序需要做如下几件事:
1. 通过添加一系列Fields来创建一批Documents对象。
2. 创建一个IndexWriter对象,并且调用它的AddDocument()方法来添加进Documents。
3. 调用QueryParser.parse()处理一段文本(string)来建造一个查询(query)对象。
4. 创建一个IndexReader对象并将查询对象传入到它的search()方法中。
3Lucene Roadmap

Lucene 源码剖析
2索引文件
为了使用Lucene来索引数据,首先你得把它转换成一个纯文本(plain-text)tokens的数据流(stream),并通过它创建出Document对象,其包含的Fields成员容纳这些文本数据。一旦你准备好些Document对象,你就可以调用IndexWriter类的addDocument(Document)方法来传递这些对象到Lucene并写入索引中。当你做这些的时候,Lucene首先分析(analyzer)这些数据来使得它们更适合索引。详见《Lucene In Action》

下面先了解一下索引结构的一些术语。
2.1 索引数据术语和约定
2.1.1 术语定义
Lucene中基本的概念(fundamental concepts)是index、Document、Field和term。
1 一条索引(index)包含(contains)了一连串(a sequence of)文档(documents)。
2 一个文档(document)是由一连串fields组成。
3 一个field是由一连串命名了(a named sequence of)的terms组成。
4 一个term是一个string(字符串)。
相同的字符串(same string)但是在两个不同的fields中被认为(considered)是不同的term。因此(thus)term被描述为(represent as)一对字符串(a pair of strings),第一个string取名(naming)为该field的名字,第二个string取名为包含在该field中的文本(text within the field)。
2.1.2 倒排索引(inverted indexing)
索引(index)存储terms的统计数据(statistics about terms),为了使得基于term的检索(term-based search)效率更高(more efficient)。Lucene的索引分成(fall into)被广为熟悉的(known as)索引种类(family of indexex)叫做倒排索引(inverted index)。这是因为它可以列举(list),对一个term来说,所有包含它的文档(documents that contain it)。这与自然关联规则(natural relationship)是相反,即由documents列举它所包含的terms。
2.1.3 Fields的种类
在Lucene中,fields可以被存储(stored),在这种情况(in which case)下它们的文本被逐字地(literally)以一种非倒排的方式(in non-inverted manner)存储进index中。那些被倒排的fields(that are inverted)称为(called)被索引(indexed)。一个field可以都被存储(stored)并且被索引(indexed)。
一个field的文本可以被分解为(be tokenized into)terms以便被索引(indexed),或者field的文本可以被逐字地使用为(used literally as)一个term来被索引(be indexed)。大多数fields被分解(be tokenized),但是有时候对某种唯一性(certain identifier)的field来逐字地索引(be indexed literally)又是非常有用的,如url。
2.1.4 片断(segments)
Lucene的索引可以由多个复合的子索引(multiple sub-indexes)或者片断(segments)组成(be composed of)。每一个segment都是一个完全独立的索引(fully independent index),它能够被分离地进行检索(be searched seperately)。索引按如下方式进行演化(evolve):
1. 为新添加的文档(newly added documents)创建新的片断(segments)。
2. 合并已存在的片断(merging existing segments)。
检索可以涉及(involve)多个复合(multiple)的segments,并且/或者多个复合(multiple)的indexes。每一个index潜在地(potentially)包含(composed of)一套(a set of)segments。

2.1.5 文档编号(document numbers)
在内部(internally),Lucene通过一个整数的(interger)文档编号(document number)来表示文档。第一篇被添加到索引中的文档编号为0(be numbered zero),每一篇随后(subsequent)被添加的document获得一个比前一篇更大的数字(a number one greater than the previous)。
需要注意的是一篇文档的编号(document’s number)可以更改,所以在Lucene之外(outside of)存储这些编号时需要特别小心(caution should be taken)。详细地说(in particular),编号在如下的情况(following situations)可以更改:
1 存储在每个segment中的编号仅仅是在所在的segment中是唯一的(unique),在它能够被使用在(be used in)一个更大的上下文(a larger context)中前必须被转变(converted)。标准的技术(standard technique)是给每一个segment分配(allocate)一个范围的值(a range of values),基于该segment所使用的编号的范围(the range of numbers)。为了将一篇文档的编号从一个segment转变为一个扩展的值(an external value),该片断的基础的文档编号(base document number)被添加(is added)。为了将一个扩展的值(external value)转变回一个segment的特定的值(specific value),该segment将该扩展的值所在的范围标识出来(be indentified),并且该segment的基础值(base value)将被减少(substracted)。例如,两个包含5篇文档的segments可能会被合并(combined),所以第一个segment有一个基础的值(base value)为0,第二个segment则为5。在第二个segment中的第3篇文档(document three from the second segment)将有一个扩展的值为8。
2 当文档被删除的时候,在编号序列中(in the numbering)将产生(created)间隔段(gaps)。这些最后(eventually)在索引通过合并演进时(index evolves through merging)将会被清除(removed)。当segments被合并后(merged),已删除的文档将会被丢弃(dropped),一个刚被合并的(freshly-merged)segment因此在它的编号序列中(in its numbering)不再有间隔段(gaps)。
2.1.6 索引结构概述
每一个片断的索引(segment index)管理(maintains)如下的数据:
1 Fields名称:这包含了(contains)在索引中使用的一系列fields的名称(the set of field names)。
2 已存储的field的值:它包含了,对每篇文档来说,一个属性-值数据对(attribute-value pairs)的清单(a list of),其中属性即为field的名字。这些被用来存储关于文档的备用信息(auxiliary information),比如它的标题(title)、url、或者一个访问一个数据库(database)的唯一标识(identifier)。这套存储的fields就是那些在检索时对每一个命中的(hits)文档所返回的(returned)信息。这些是通过文档编号(document number)来做为key得到的。
3 Term字典(dictionary):一个包含(contains)所有terms的字典,被使用在所有文档中所有被索引的fields中。它还包含了该term所在的文档的数目(the number of documents which contains the term),并且指向了(pointer to)term的频率(frequency)和接近度(proximity)的数据(data)。
4 Term频率数据(frequency data):对字典中的每一个term来说,所有包含该term(contains the term)的文档的编号(numbers of all documents),以及该term出现在该文档中的频率(frequency)。
5 Term接近度数据(proximity data):对字典中的每一个term来说,该term出现在(occur)每一篇文档中的位置(positions)。
6 调整因子(normalization factors):对每一篇文档的每一个field来说,为一个存储的值(a value is stored)用来加入到(multiply into)命中该field的分数(score for hits on that field)中。
7 Term向量(vectors):对每一篇文档的每一个field来说,term向量(有时候被称做文档向量)可以被存储。一个term向量由term文本和term的频率(frequency)组成(consists of)。怎么添加term向量到你的索引中请参考Field类的构造方法(constructors)。
8 删除的文档(deleted documents):一个可选的(optional)文件标示(indicating)哪一篇文档被删除。
关于这些项的详细信息在随后的章节(subsequent sections)中逐一介绍。
2.1.7 索引文件中定义的数据类型
| 数据类型 |
所占字节长度(字节) |
说明 |
||||||||||||||||||||||||||||||||||||||||||||
| Byte |
1 |
基本数据类型,其他数据类型以此为基础定义 |
||||||||||||||||||||||||||||||||||||||||||||
| UInt32 |
4 |
32位无符号整数,高位优先 |
||||||||||||||||||||||||||||||||||||||||||||
| UInt64 |
8 |
64位无符号整数,高位优先 |
||||||||||||||||||||||||||||||||||||||||||||
| VInt |
不定,最少1字节 |
动态长度整数,每字节的最高位表明还剩多少字节,每字节的低七位表明整数的值,高位优先。可以认为值可以为无限大。其示例如下
|
||||||||||||||||||||||||||||||||||||||||||||
| Chars |
不定,最少1字节 |
采用UTF-8编码[20]的Unicode字符序列 |
||||||||||||||||||||||||||||||||||||||||||||
| String |
不定,最少2字节 |
由VInt和Chars组成的字符串类型,VInt表示Chars的长度,Chars则表示了String的值 |
3.1索引文件结构
Lucene使用文件扩展名标识不同的索引文件,文件名标识不同版本或者代(generation)的索引片段(segment)。如.fnm文件存储域Fields名称及其属性,.fdt存储文档各项域数据,.fdx存储文档在fdt中的偏移位置即其索引文件,.frq存储文档中term位置数据,.tii文件存储term字典,.tis文件存储term频率数据,.prx存储term接近度数据,.nrm存储调节因子数据,另外segments_X文件存储当前最新索引片段的信息,其中X为其最新修改版本,segments.gen存储当前版本即X值,这些文件的详细介绍上节已说过了。
下面的图描述了一个典型的lucene索引文件列表:

如果将它们的关系划成图则如下所示

这些文件中存储数据的详细结构是怎样的呢,下面几个小节逐一介绍它们,熟悉它们的结构非常有助于优化Lucene的查询和索引效率和存储空间等。
3.2每个Index包含的单个文件
下面几节介绍的文件存在于每个索引index中,并且只有一份。
3.2.1Segments文件
索引中活动(active)的Segments被存储在segment info文件中,segments_N,在索引中可能会包含一个或多个segments_N文件。然而,最大一代的那个文件(the one with largest generation)是活动的片断文件(这时更旧的segments_N文件依然存在(are present)是因为它们暂时(temporarily)还不能被删除,或者,一个writer正在处理提交请求(in the process of committing),或者一个用户定义的(custom)IndexDeletionPolicy正被使用)。这个文件按照名称列举每一个片断(lists each segment by name),详细描述分离的标准(seperate norm)和要删除的文件(deletion files),并且还包含了每一个片断的大小。
对2.1版本来说,还有一个文件segments.gen。这个文件包含了该索引中当前生成的代(current generation)(segments_N中的_N)。这个文件仅用于一个后退处理(fallback)以防止(in case)当前代(current generation)不能被准确地(accurately)通过单独地目录文件列举(by directory listing alone)来确定(determened)(由于某些NFS客户端因为基于时间的目录(time-based directory)的缓存终止(cache expiration)而引起)。这个文件简单地包含了一个int32的版本头(version header)(SegmentInfos.FORMAT_LOCKLESS=-2),遵照代的记录(followed by the generation recorded)规则,对int64来说会写两次(write twice)。
| 版本 |
包含的项 |
数目 |
类型 |
描述 |
| 2.1之前版本 |
Format |
1 |
Int32 |
在Lucene1.4中为-1,而在Lucene 2.1中为-3(SegmentsInfos.FORMAT_SINGLE_NORM_FILE) |
| Version |
1 |
Int64 |
统计在删除和添加文档时,索引被更改了多少次。 |
|
| NameCounter |
1 |
Int32 |
用于为新的片断文件生成新的名字。 |
|
| SegCount |
1 |
Int32 |
片断的数目 |
|
| SegName |
SegCount |
String |
片断的名字,用于所有构成片断索引的文件的文件名前缀。 |
|
| SegSize |
SegCount |
Int32 |
包含在片断索引中的文档的数目。 |
|
| 2.1及之后版本 |
Format |
1 |
Int32 |
在Lucene 2.1和Lucene 2.2中为-3(SegmentsInfos.FORMAT_SINGLE_NORM_FILE) |
| Version |
1 |
Int64 |
同上 |
|
| NameCounter |
1 |
Int32 |
同上 |
|
| SegCount |
1 |
Int32 |
同上 |
|
| SegName |
SegCount |
String |
同上 |
|
| SegSize |
SegCount |
Int32 |
同上 |
|
| DelGen |
SegCount |
Int64 |
为分离的删除文件的代的数目(generation count of the separate deletes file),如果值为-1,表示没有分离的删除文件。如果值为0,表示这是一个2.1版本之前的片断,这时你必须检查文件是否存在_X.del这样的文件。任意大于0的值,表示有分离的删除文件,文件名为_X_N.del。 |
|
| HasSingleNormFile |
SegCount |
Int8 |
该值如果为1,表示Norm域(field)被写为一个单一连接的文件(single joined file)中(扩展名为.nrm),如果值为0,表示每一个field的norms被存储为分离的.fN文件中,参考下面的“标准化因素(Normalization Factors)” |
|
| NumField |
SegCount |
Int32 |
表示NormGen数组的大小,如果为-1表示没有NormGen被存储。 |
|
| NormGen |
SegCount * NumField |
Int64 |
记录分离的标准文件(separate norm file)的代(generation),如果值为-1,表示没有normGens被存储,并且当片断文件是2.1之前版本生成的时,它们全部被假设为0(assumed to be 0)。而当片断文件是2.1及更高版本生成的时,它们全部被假设为-1。这时这个代(generation)的意义与上面DelGen的意义一样。 |
|
| IsCompoundFile |
SegCount |
Int8 |
记录是否该片断文件被写为一个复合的文件,如果值为-1表示它不是一个复合文件(compound file),如果为1则为一个复合文件。另外如果值为0,表示我们需要检查文件系统是否存在_X.cfs。 |
|
| 2.3 |
Format |
1 |
Int32 |
在Lucene 2.3中为-4 (SegmentInfos.FORMAT_SHARED_DOC_STORE) |
| Version |
1 |
Int64 |
同上 |
|
| NameCounter |
1 |
Int32 |
同上 |
|
| SegCount |
1 |
Int32 |
同上 |
|
| SegName |
SegCount |
String |
同上 |
|
| SegSize |
SegCount |
Int32 |
同上 |
|
| DelGen |
SegCount |
Int64 |
同上 |
|
| DocStoreOffset |
1 |
Int32 |
如果值为-1则该segment有自己的存储文档的fields数据和term vectors的文件,并且DocStoreSegment, DocStoreIsCompoundFile不会存储。在这种情况下,存储fields数据(*.fdt和*.fdx文件)以及term vectors数据(*.tvf和*.tvd和*.tvx文件)的所有文件将存储在该segment下。另外,DocStoreSegment将存储那些拥有共享的文档存储文件的segment。DocStoreIsCompoundFile值为1如果segment存储为compound文件格式(如.cfx文件),并且DocStoreOffset值为那些共享文档存储文件中起始的文档编号,即该segment的文档开始的位置。在这种情况下,该segment不会存储自己的文档数据文件,而是与别的segment共享一个单一的数据文件集。 |
|
| [DocStoreSegment] |
1 |
String |
如上 |
|
| [DocStoreIsCompoundFile] |
1 |
Int8 |
如上 |
|
| HasSingleNormFile |
SegCount |
Int8 |
同上 |
|
| NumField |
SegCount |
Int32 |
同上 |
|
| NormGen |
SegCount * NumField |
Int64 |
同上 |
|
| IsCompoundFile |
SegCount |
Int8 |
同上 |
|
| 2.4及以上 |
Format |
1 |
Int32 |
在Lucene 2.4中为-7 (SegmentInfos.FORMAT_HAS_PROX) |
| Version |
1 |
Int64 |
同上 |
|
| NameCounter |
1 |
Int32 |
同上 |
|
| SegCount |
1 |
Int32 |
同上 |
|
| SegName |
SegCount |
String |
同上 |
|
| SegSize |
SegCount |
Int32 |
同上 |
|
| DelGen |
SegCount |
Int64 |
同上 |
|
| DocStoreOffset |
1 |
Int32 |
同上 |
|
| [DocStoreSegment] |
1 |
String |
同上 |
|
| [DocStoreIsCompoundFile] |
1 |
Int8 |
同上 |
|
| HasSingleNormFile |
SegCount |
Int8 |
同上 |
|
| NumField |
SegCount |
Int32 |
同上 |
|
| NormGen |
SegCount * NumField |
Int64 |
同上 |
|
| IsCompoundFile |
SegCount |
Int8 |
同上 |
|
| DeletionCount |
SegCount |
Int32 |
记录该segment中删除的文档数目 |
|
| HasProx |
SegCount |
Int8 |
值为1表示该segment中至少一个fields的omitTf设置为false,否则为0 |
|
| Checksum |
1 |
Int64 |
存储segments_N文件中直到checksum的所有字节的CRC32 checksum数据,用来校验打开的索引文件的完整性(integrity)。 |
3.2.2Lock文件
写锁(write lock)文件名为“write.lock”,它缺省存储在索引目录中。如果锁目录(lock directory)与索引目录不一致,写锁将被命名为“XXXX-write.lock”,其中“XXXX”是一个唯一的前缀(unique prefix),来源于(derived from)索引目录的全路径(full path)。当这个写锁出现时,一个writer当前正在修改索引(添加或者清除文档)。这个写锁确保在一个时刻只有一个writer修改索引。
需要注意的是在2.1版本之前(prior to),Lucene还使用一个commit lock,这个锁在2.1版本里被删除了。
3.2.3Deletable文件
在Lucene 2.1版本之前,有一个“deletable”文件,包含了那些需要被删除文档的详细资料。在2.1版本后,一个writer会动态地(dynamically)计算哪些文件需要删除,因此,没有文件被写入文件系统。
3.2.4 Compound文件s(.cfs)
从Lucene 1.4版本开始,compound文件格式成为缺省信息。这是一个简单的容器(container)来服务所有下一章节(next section)描述的文件(除了.del文件),格式如下:
| 版本 |
包含的项 |
数目 |
类型 |
描述 |
| 1.4之后版本 |
FileCount |
1 |
VInt |
|
| DataOffset |
FileCount |
Long |
||
| FileName |
FileCount |
String |
||
| FileData |
FileCount |
raw |
Raw文件数据是上面命名的所有单个的文件数据(the individual named above)。 |
结构如下图所示:

3.3每个Segment包含的文件
剩下的文件(remaining files)都是per-segment(每个片断文件),因此(thus)都用后缀来定义(defined by suffix)。
3.3.1Fields域数据文件
3.3.1.1Field信息(.fnm)
Field的名字都存储在Field信息文件中,后缀是.fnm。
| 文件 |
包含的项 |
数目 |
类型 |
版本 |
描述 |
| FieldsInfo(.fnm) |
FieldsCount |
1 |
VInt |
||
| FieldName |
FieldsCount |
String |
|||
| FieldBits |
FieldsCount |
Byte |
最低阶的bit位(low-order bit)值为1表示是被索引的Fields,0表示非索引的Fields。 |
||
| 第二个最低阶的bit位(second lowest-order bit)值为1表示该Field有term向量存储(term vectors stored),0表示该field没有term向量。 |
|||||
| >=1.9 |
如果第三个最低阶的bit位(third lowest-order bit)设置(0×04),term的位置(term positions)将和term向量一起被存储(stored with term vectors)。 |
||||
| >=1.9 |
如果第四个最低阶的bit位(fourth lowest-order bit)设置(0×08),term的偏移(term offsets)将和term向量一起被存储(stored with term vectors)。 |
||||
| >=1.9 |
如果第五个最低阶的bit位(fifth lowest-order bit)设置(0×10),norms将对索引的field忽略掉(norms are omitted for the indexed field)。 |
||||
| >=1.9 |
如果第六个最低阶的bit位(sixth lowest-order bit)设置(0×20),payloads将为索引的field存储(payloads are stored for the indexed field)。 |
注明:payloads概念:
词条载荷(payloads)――允许用户将任意二进制数据和索引中的任意词条(term)相关联。
词条载荷是一个允许信息在索引中按逐词条储存的新特性。例如,当索引Web页面时,储存某个关键词的额外信息可能会很有用,例如这个关键词关联的URL或者经过文字分析后得出的权重系数。在更高级的应用中,为了突出语句中的名次成分相对于其它成分的重要性,储存语句中这个关键词出现的部分可能会很有帮助。我今年在ApacheCon Europe会议上的演讲中就有几张讲述词条载荷的幻灯片,感兴趣的读者可以去看看。
Fields将使用它们在这个文件中的顺序来编号(fields are numbered by their order in this file)。需要注意的是,就像文档编号(document numbers)一样,field编号(field numbers)与片断是相关的(are segment relative)。结构如下图所示:

3.3.1.2存储的Field(.fdx和.fdt)
存储的fields(stored fields)通过两个文件来呈现(represented by two files),即field索引文件(.fdx)和field数据文件(.fdt)。
| 文件 |
包含的项 |
父项 |
数目 |
类型 |
版本 |
描述 |
| Fields Index(.fdx) 对每个文档来说,存储指向它的fields数据的指针(pointer) |
FieldValuesPosition |
SegSize |
UInt64 |
用于找详细文档(a particular document)的所有fields的field数据文件中的位置(position),因为它包含的(contains)是固定长度的数据(fixed-length data),这个文件可以很容易地进行随机访问(randomly accessed)。 |
||
| 文档n的field数据的位置是在该文件中n*8的位置中(UInt64类型)。 |
||||||
| Fields Data(.fdt)这个文件存储每个文档的field数据 |
DocFieldData |
SegSize |
||||
| FieldCount |
DocFieldData |
1 |
VInt |
|||
| FieldNum |
DocFieldData |
FieldCount |
VInt |
|||
| Bits |
DocFieldData |
FieldCount |
Byte |
<=1.4 |
只有最低阶的bit位(low-order bits of Bits)被使用,值为1表示tokenized field(分解过的field),0表示non-tokenized field。 |
|
| Byte |
>=1.9 |
最低阶的bit位表示tokenized field |
||||
| >=1.9 |
第二个bit(second bit)用于表示该field存储binary数据。 |
|||||
| >=1.9 |
第三个bit(third bit)表示该field的压缩选项被开启(field with compression enabled),如果压缩选项开启,采用的压缩算法(algorithm)是ZLIB |
|||||
| Value |
DocFieldData |
FieldCount |
String |
<=1.4 |
||
| String | BinaryValue |
>=1.9 |
依赖于Bits的值 |
||||
| BinaryValue |
>=1.9 |
ValueSize,<Byte>^ValueSize |
||||
| ValueSize |
Value |
1 |
VInt |
>=1.9 |
结构如下图所示:

3.3.2存储的term字典(.tii和.tis)
Term字典使用如下两种文件存储,第一种是存储term信息(TermInfoFile)的文件,即.tis文件,格式如下:
| 版本 |
包含的项 |
数目 |
类型 |
描述 |
| 全部版本 |
TIVersion |
1 |
UInt32 |
记录该文件的版本,1.4版本中为-2 |
| TermCount |
1 |
UInt64 |
||
| IndexInterval |
1 |
UInt32 |
||
| SkipInterval |
1 |
UInt32 |
||
| MaxSkipLevels |
1 |
UInt32 |
||
| TermInfos |
1 |
TermInfo… |
||
| TermInfos->TermInfo |
TermCount |
TermInfo |
||
| TermInfo->Term |
TermCount |
Term |
||
| Term->PrefixLength |
TermCount |
VInt |
Term文本的前缀可以共享,该项的值表示根据前一个term的文本来初始化的字符串前缀长度,前一个term必须已经预设成后缀文本以便构成该term的文本。比如,如果前一个term为“bone”,而当前term为“boy”,则该PrefixLength值为2,suffix值为“y” |
|
| Term->Suffix |
TermCount |
String |
如上 |
|
| Term->FieldNum |
TermCount |
VInt |
用来确定term的field,它们存储在.fdt文件中。 |
|
| TermInfo->DocFreq |
TermCount |
VInt |
包含该term的文档数目 |
|
| TermInfo->FreqDelta |
TermCount |
VInt |
用来确定包含在.frq文件中该term的TermFreqs的位置。特别指出,它是该term的数据在文件中位置与前一个term的位置的差值,当为第一个term时,该值为0 |
|
| TermInfo->ProxDelta |
TermCount |
VInt |
用来确定包含在.prx文件中该term的TermPositions的位置。特别指出,它是该term的数据在文件中的位置与前一个term的位置地差值,当为第一个term时,该值为0。如果fields的omitTF设置为true,该值也为0,因为prox信息没有被存储。 |
|
| TermInfo->SkipDelta |
TermCount |
VInt |
用来确定包含在.frq文件中该term的SkipData的位置。特别指出,它是TermFreqs之后即SkipData开始的字节数目,换句话说,它是TermFreq的长度。SkipDelta只有在DocFreq不比SkipInteval小的情况下才会存储。 |
TermInfoFile文件按照Term来排序,排序方法首先按照Term的field名称(按照UTF-16字符编码)排序,然后按照Term的Text字符串(UTF-16编码)排序。 结构如下图所示:

另一种是存储term信息的索引文件,即.tii文件,该文件包含.tis文件中每一个IndexInterval的值,与它在.tis中的位置一起被存储,这被设计来完全地读进内存中(read entirely into memory),以便用来提供随机访问.tis文件。该文件的结构与.tis文件非常相似,只是添加了一项数据,即IndexDelta。格式如下
| 版本 |
包含的项 |
数目 |
类型 |
描述 |
| 全部版本 |
TIVersion |
1 |
UInt32 |
同tis |
| IndexTermCount |
1 |
UInt64 |
同tis |
|
| IndexInterval |
1 |
UInt32 |
同tis |
|
| SkipInterval |
1 |
UInt32 |
是TermDocs存储在skip表中的分数(fraction),用来加速(accelerable)TermDocs.skipTo(int)的调用。在更小的索引中获得更大的结果值(larger values result),将获得更高的速度,但却更小开销?(fewer accelerable cases while smaller values result in bigger indexes, less acceleration (in case of a small value for MaxSkipLevels) |
|
| MaxSkipLevels |
1 |
UInt32 |
是.frq文件中为每一个term存储的skip levels的最大数目,A low value results in smaller indexes but less acceleration, a larger value results in slighly larger indexes but greater acceleration.参见.frq文件格式中关于skip levels的详细介绍。 |
|
| TermIndices |
IndexTermCount |
TermIndice |
同tis |
|
| TermIndice->TermInfo |
IndexTermCount |
TermInfo |
同tis |
|
| TermIndice->IndexDelta |
IndexTermCount |
VLong |
用来确定该Term的TermInfo在.tis文件中的位置,特别指出,它是该term的数据的位置与前一个term位置的差值。 |
结构如下图所示:

Lucene源代码剖析
3.3.3Term频率数据(.frq)
Term频率数据文件(.frq文件)存储容纳了每一个term的文档列表,以及该term出现在该文档中的频率(出现次数frequency,如果omitTf设置为fals时才存储)。
| 版本 |
包含的项 |
父类型 |
类型 |
描述 |
| 全部版本 |
TermFreqs |
TermCount |
TermFreq |
按照term顺序排序,term是隐含的(?implicit),来自.tis文件。TermFreq按文档编号递增的顺序排序。 |
| SkipData |
TermCount |
SkipData |
||
| TermFreq->DocDelta |
TermCount |
VInt |
如果omitTf设置为false,要同时检测文档编号和频率,特别指出,DocDelta/2时该文档编号与上一个文档编号的差值(如果是第一个文档值为0)。当DocDelta为单数时频率为1,当DocDelta为偶数时频率为读取下一个VInt的值。如果omitTf设置为true,DocDelta为文档编号之间的差值(gap,不用乘以2,multiplited),频率信息则不被存储。 |
|
| TermFreq->[Freq?] |
TermCount |
VInt |
||
| SkipData->SkipLevelLength |
NumSkipLevels-1 |
VInt |
||
| SkipData->SkipLevel |
TermCount |
SkipDatums |
||
| SkipLevel->SkipDatum |
DocFreq/(SkipInterval^(Level + 1)) |
SkipDatum |
||
| SkipData->SkipDatum |
TermCount |
SkipDatum |
||
| SkipDatum->DocSkip |
1 |
VInt |
||
| SkipDatum->PayloadLength? |
1 |
VInt |
||
| SkipDatum->FreqSkip |
1 |
VInt |
||
| SkipDatum->ProxSkip |
1 |
VInt |
||
| SkipDatum->SkipChildLevelPointer? |
1 |
VLong |
结构如下图所示:

举例来说,当omitTf设置为false时,一个term的TermFreqs在文档7出现1次并且在文档11中出现3次,则为如下的VInt数字序列:
15, 8, 3
如果omitTf设置为true时,则为如下数字序列:
7, 4
DocSkip记录在TermFreqs中每隔SkipInterval个文档之前的文档编号。如果该term的域fields中被禁用payloads时,则DocSkip呈现在序列中(in the sequence)与上一个值之间的差值(difference)。如果payloads启用时,则DocSkip/2表示序列中与上一个值之间的差值。如果payloads启用并且DocSkip为奇数时,PayloadLength将被存储并表示(indicating)在TermPositions中第SkipInterval个文档之前的最后一个payload的长度。FreqSkip和ProxSkip分别(respectively)记录在FreqFile和ProxFile文件中每SkipInterval个记录(entry)的位置。文件的位置信息对序列中前一个SkipDatumn来说与TermFreqs和Positions的起始信息相关。
例如,如果DocFreq=35并且SkipInterval=16,则在TermFreqs中有两个SkipData记录,容纳第15和第31个文档编号。第一个FreqSkip代表第16个SkipDatumn起始的TermFreqs数据开始之后的字节数目,第二个FreqSkip表示第32个SkipDatumn开始之后的字节数目。第一个ProxSkip代表第16个SkipDatumn起始的Positions数据开始之后的字节数目,第二个ProxSkip表示第32个SkipDatumn开始之后的字节数目。
在Lucene 2.2版本中介绍了skip levels的想法(notion),每一个term可以有多个skip levels。一个term的skip levels的数目等于NumSkipLevels = Min(MaxSkipLevels, floor(log(DocFreq/log(SkipInterval))))。对一个skip level来说SkipData记录的数目等于DocFreq/(SkipInterval^(Level + 1))。然而(whereas)最低的(lowest)skip level等于Level = 0。
例如假设SkipInterval = 4, MaxSkipLevels = 2, DocFreq = 35,则skip level 0有8个SkipData记录,在TermFreqs序列中包含第3、7、11、15、19、23、27和31个文档的编号。Skip level 1则有2个SkipData记录,在TermFreqs中包含了第15和第31个文档的编号。
在所有level>0之上的SkipData记录中包含一个SkipChildLevelPointer,指向(referencing)level-1中相应)(corresponding)的SkipData记录。在这个例子中,level 1中的记录15有一个指针指向level 0中的记录15,level 1中的记录31有一个指针指向level 0中的记录31。
3.3.4Positions位置信息数据(.prx)
Positions位置信息数据文件(.prx文件)容纳了每一个term出现在所有文档中的位置的列表。注意如果在fields中的omitTf设置为true时将不会在此文件中存储任何信息,并且如果索引中所有fields中的omitTf都设置为true,此.prx文件将不会存在。
| 版本 |
包含的项 |
数目 |
类型 |
描述 |
| 全部版本 |
TermPositions |
TermCount |
TermPositions |
按照term顺序排序,term是隐含的(?implicit),来自.tis文件。 |
| TermPositions->Positions |
DocFreq |
Positions |
按文档编号递增的顺序排序。 |
|
| Positions->PositionDelta |
Freq |
VInt |
如果term的fields中payloads被禁用,则取值为term出现在该文档中当前位置与前一个位置的差值(第一个位置取值0)。如果payloads被启用,则取值为当前位置与上一个位置之间差值的2倍。如果payloads启用并且PositionDelta为单数,则PayloadLength被存储,表示当前位置的payloads的长度。 |
|
| Positions->Payload? |
Freq |
Payload |
||
| Payload->PayloadLength? |
1 |
VInt |
||
| Payload->PayloadData |
PayloadLength |
byte |
结构如下图所示:

例如,如果一个term的TermPositions为一个文档中出现的第4个term,并且为后来的文档(subsequent document)中出现的第5个和第9个term,则将被存储为下面的VInt数据序列(payloads禁用):
4, 5, 4
PayloadData是与term的当前位置相关联元数据(metadata),如果该位置的PayloadLength被存储,则它表示此payload的长度。如果PayloadLength没存储,则此payload与前一个位置的payload拥有相等的PayloadLength。
3.3.5Norms调节因子文件(.nrm)
在Lucene 2.1版本之前,每一个索引都有一个norm文件给每一个文档都保存了一个字节。对每一个文档来说,那些.f[0-9]*包含了一个字节容纳一个被编码的分数,值为对hits结果集来说在那个field中被相乘得出的分数(multiplied into the score)。每一个分离的norm文件在适当的时候(when adequate)为复合的(compound)和非复合的segment片断创建,格式如下:
Norms (.f[0-9]*) –> <Byte> SegSize 在Lucene 2.1及以上版本,只有一个norm文件容纳了所有norms数据:
| 版本 |
包含的项 |
数目 |
类型 |
描述 |
| 2.1及之后版本 |
NormsHeader |
1 |
raw |
‘N’,'R’,'M’,Version:4个字节,最后字节表示该文件的格式版本,当前为-1 |
| Norms |
NumFieldsWithNorms |
Norms |
||
| Norms->Byte |
SegSize |
Byte |
每一个字节编码了一个float指针数值,bits 0-2 容纳 3-bit 尾数(mantissa),bits 3-8容纳 5-bit 指数(exponent),这些被转换成一个IEEE单独的float数值,如图所示 |
|
| NormsHeader->Version |
1 |
Byte |
结构如下图所示:

一个分离的norm文件在一个存在的segment的norm数据被更改的时候被创建,当field N被修改时,一个分离的norm文件.sN被创建,用来维护该field的norm数据。
Lucene 源码剖析
3.3.6Term向量文件
Term向量(vector)的支持是field基本组成中对一个field来说的可选项,它包含如下4种文件:
1. 文档索引或.tvx文件:对每个文档来说,它把偏移(offset)存储进文档数据(.tvd)文件和域field数据(.tvf)文件
| 版本 |
包含的项 |
数目 |
类型 |
描述 |
| 全部版本 |
TVXVersion |
1 |
Int |
在Lucene 2.4中为3 (TermVectorsReader.FORMAT_VERSION2) |
| DocumentPosition |
NumDocs |
UInt64 |
在.tvd文件中的偏移 |
|
| FieldPosition |
NumDocs |
UInt64 |
在.tvf文件中的偏移 |
结构如下图所示:

2. 文档或.tvd文件:对每个文档来说,它包含fields的数目,有term向量的fields的列表,还有指向term向量域文件(.tvf)中的域信息的指针列表。该文件用于映射(map out)出那些存储了term向量的fields,以及这些field信息在.tvf文件中的位置。
| 版本 |
包含的项 |
数目 |
类型 |
描述 |
| 全部版本 |
TVDVersion |
1 |
Int |
在Lucene 2.4中为3 (TermVectorsReader.FORMAT_VERSION2) |
| NumFields |
NumDocs |
VInt |
||
| FieldNums |
NumDocs |
FieldNums |
||
| FieldNums->FieldNumDelta |
NumFields |
VInt |
||
| FieldPositions |
NumDocs |
FieldPositions |
||
| FieldPositions->FieldPositionDelta |
NumField-1 |
VLong |
结构如下图所示:

3. 域field或.tvf文件:对每个存储了term向量的field来说,该文件包含了一个term的列表,及它们的频率,还有可选的位置和偏移信息。
| 版本 |
包含的项 |
数目 |
类型 |
描述 |
| 全部版本 |
TVFVersion |
1 |
Int |
在Lucene 2.4中为3 (TermVectorsReader.FORMAT_VERSION2) |
| NumTerms |
NumFields |
VInt |
||
| Position/Offset |
NumFields |
Byte |
||
| TermFreqs |
NumFields |
TermFreqs |
||
| TermFreqs->TermText |
NumTerms |
TermText |
||
| TermText->PrefixLength |
NumTerms |
VInt |
||
| TermText->Suffix |
NumTerms |
String |
||
| TermFreqs->TermFreq |
NumTerms |
VInt |
||
| TermFreqs->Positions? |
NumTerms |
Positions |
||
| Positions->Position |
TermFreq |
VInt |
||
| TermFreqs->Offsets? |
NumTerms |
Offsets |
||
| Offsets->StartOffset |
TermFreq |
VInt |
||
| Offsets->EndOffset |
TermFreq |
VInt |
结构如下图所示:

备注:
l Positions/Offsets 字节存储的条件是当该term向量含有存储的位置或偏移信息时。
l Term Text prefixes文本前缀是共享的,表示根据前一个term的文本来初始化的字符串前缀长度,前一个term必须已经预设成后缀文本以便构成该term的文本。比如,如果前一个term为“bone”,而当前term为“boy”,则该PrefixLength值为2,suffix值为“y”。
l Positions存储为Delta编码的VInts,意思是我们只能存储当前位置与最后位置的差值。
l Offsets存储为Delta编码的VInts,第一个VInt是startOffset,第二个VInt是endOffset。
3.3.7删除的文档 (.del)
删除的文档(.del)文件是可选的,而且仅当一个segment存在有被删除的文档时才存在。即使对每一单个segment,它也是维护复合segment的外部数据(exterior)。
对Lucene 2.1及以前版本,它的格式为:Deletions (.del) –> ByteCount,BitCount,Bits
对2.2及以上版本,格式如下:
| 版本 |
包含的项 |
数目 |
类型 |
描述 |
| 2.2之后版本 |
[Format] |
1 |
UInt32 |
可选,-1表示为DGaps,非负数(negative)值表示为Bit,并且此时不存储Format |
| ByteCount |
1 |
UInt32 |
代表Bit里的字节数目,而且一般值为(SegSize/8)+1 |
|
| BitCount |
1 |
UInt32 |
表示Bit里当前设置的字节数目 |
|
| Bit|DGaps |
1 |
Bit还是DGaps取决于Format。Bits中对每一个索引的文档均包含一个字节,当一个bit对应的一个文档编号被设置时,表示该文档被删除。Bit从最低(least)到最重要(significant)的文档排序。所以Bits包含两个字节,0×00和0×02,则文档9被标记为删除。DGaps表示松散(sparse)的bit-vector向量比Bits更有效率(efficiently)。DGaps由索引中非0的Bits位生成,以及非0的字节数据本身。Bits中非0字节数目(NonzeroBytesCoun)不会存储。 |
||
| Bit->Byte |
ByteCount |
Byte |
||
| DGaps->DGap |
NonzeroBytesCount |
VInt |
||
| DGaps-> NonzeroBytes |
NonzeroBytesCount |
Byte |
结构如下图所示:

举例来说,如果有8000 bits,并且只有bits 10, 12, 32 被设置,DGaps将会存储如下数据:
(VInt) 1 , (byte) 20 , (VInt) 3 , (Byte) 1
3.3.8局限性(Limitations)
有几个地方这些文件格式会让terms和文档的最大数目受限于32-bit的大小,大约最大40亿。这在今天不是一个问题,长远来看(in the long term)可能会成为个问题。因此它们应该替换为UInt64类型或者更好的类型,如VInt则没有大小限制。
Lucene 源码剖析
4索引是如何创建的
为了使用Lucene来索引数据,首先你比把它转换成一个纯文本(plain-text)tokens的数据流(stream),并通过它创建出Document对象,其包含的Fields成员容纳这些文本数据。一旦你准备好些Document对象,你就可以调用IndexWriter类的addDocument(Document)方法来传递这些对象到Lucene并写入索引中。当你做这些的时候,Lucene首先分析(analyzer)这些数据来使得它们更适合索引。详见《Lucene In Action》
4.1 索引创建示例
下面的代码示例如何给一个文件建立索引。
// Store the index on disk
Directory directory = FSDirectory.getDirectory(“/tmp/testindex“);
// Use standard analyzer
Analyzer analyzer = new StandardAnalyzer();
// Create IndexWriter object
IndexWriter iwriter = new IndexWriter(directory, analyzer, true);
iwriter.setMaxFieldLength(25000);
// make a new, empty document
Document doc = new Document();
File f = new File(“/tmp/test.txt“);
// Add the path of the file as a field named ”path”. Use a field that is
// indexed (i.e. searchable), but don’t tokenize the field into words.
doc.add(new Field(“path“, f.getPath(), Field.Store.YES, Field.Index.UN_TOKENIZED));
String text = “This is the text to be indexed.“;
doc.add(new Field(“fieldname“, text, Field.Store.YES, Field.Index.TOKENIZED));
// Add the last modified date of the file a field named ”modified”. Use
// a field that is indexed (i.e. searchable), but don’t tokenize the field
// into words.
doc.add(new Field(“modified“,
DateTools.timeToString(f.lastModified(), DateTools.Resolution.MINUTE),
Field.Store.YES, Field.Index.UN_TOKENIZED));
// Add the contents of the file to a field named ”contents”. Specify a Reader,
// so that the text of the file is tokenized and indexed, but not stored.
// Note that FileReader expects the file to be in the system’s default encoding.
// If that’s not the case searching for special characters will fail.
doc.add(new Field(“contents“, new FileReader(f)));
iwriter.addDocument(doc);
iwriter.optimize();
iwriter.close();
下面详细介绍每一个类的处理机制。
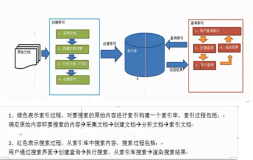
4.2 索引创建类IndexWriter
一个IndexWriter对象创建并且维护(maintains) 一条索引并生成segment,使用DocumentsWriter类来建立多个文档的索引数据,SegmentMerger类负责合并多个segment。
4.2.1 org.apache.lucene.store.IndexWriter
一个IndexWriter对象只创建并维护一个索引。IndexWriter通过指定存放的目录(Directory)以及文档分析器(Analyzer)来构建,direcotry代表索引存储(resides)在哪里;analyzer表示如何来分析文档的内容;similarity用来规格化(normalize)文档,给文档算分(scoring);IndexWriter类里还有一些SegmentInfos对象用于存储索引片段信息,以及发生故障回滚等。以下是它们的类图:

它的构造函数(constructor)的create参数(argument)确定(determines)是否一条新的索引将被创建,或者是否一条已经存在的索引将被打开。需要注意的是你可以使用create=true参数打开一条索引,即使有其他readers也在在使用这条索引。旧的readers将继续检索它们已经打开的”point in time”快照(snapshot),并不能看见那些新已创建的索引,直到它们再次打开(re-open)。另外还有一个没有create参数的构造函数,如果提供的目录(provided path)中没有已经存在的索引,它将创建它,否则将打开此存在的索引。
另一方面(in either case),添加文档使用addDocument()方法,删除文档使用removeDocument()方法,而且一篇文档可以使用updateDocument()方法来更新(仅仅是先执行delete在执行add操作而已)。当完成了添加、删除、更新文档,应该需要调用close方法。
这些修改会缓存在内存中(buffered in memory),并且定期地(periodically)刷新到(flush)Directory中(在上述方法的调用期间)。一次flush操作会在如下时候触发(triggered):当从上一次flush操作后有足够多缓存的delete操作(参见setMaxBufferedDeleteTerms(int)),或者足够多已添加的文档(参见setMaxBufferedDocs(int)),无论哪个更快些(whichever is sooner)。对被添加的文档来说,一次flush会在如下任何一种情况下触发,文档的RAM缓存使用率(setRAMBufferSizeMB)或者已添加的文档数目,缺省的RAM最高使用率是16M,为得到索引的最高效率,你需要使用更大的RAM缓存大小。需要注意的是,flush处理仅仅是将IndexWriter中内部缓存的状态(internal buffered state)移动进索引里去,但是这些改变不会让IndexReader见到,直到commit()和close()中的任何一个方法被调用时。一次flush可能触发一个或更多的片断合并(segment merges),这时会启动一个后台的线程来处理,所以不会中断addDocument的调用,请参考MergeScheduler。
构造函数中的可选参数(optional argument)autoCommit控制(controls)修改对IndexReader实体(instance)读取相同索引的能见度(visibility)。当设置为false时,修改操作将不可见(visible)直到close()方法被调用后。需要注意的是修改将依然被flush进Directory,就像新文件一样(as new files),但是却不会被提交(commit)(没有新的引用那些新文件的segments_N文件会被写入(written referencing the new files))直道close()方法被调用。如果在调用close()之前发生了某种严重错误(something goes terribly wrong)(例如JVM崩溃了),于是索引将反映(reflect)没有任何修改发生过(none of changes made)(它将保留它开始的状态(remain in its starting state))。你还可以调用rollback(),这样可以关闭那些没有提交任何修改操作的writers,并且清除所有那些已经flush但是现在不被引用的(unreferenced)索引文件。这个模式(mode)对防止(prevent)readers在一个错误的时间重新刷新(refresh)非常有用(例如在你完成所有delete操作后,但是在你完成添加操作前的时候)。它还能被用来实现简单的single-writer的事务语义(transactional semantics)(“all or none”)。你还可以执行两条语句(two-phase)的commit,通过调用prepareCommit()方法,之后再调用commit()方法。这在Lucene与外部资源(例如数据库)交互的时候是很需要的,而且必须执行commit或rollback该事务。
当autoCommit设为true的时候,该writer会周期性地提交它自己的数据。已过时:注意在3.0版本中,IndexWriter将不会接收autoCommit=true,它会硬设置(hardwired)为false。你可以自己在需要的时候经常调用commit()方法。这不保证什么时候一个确定的commit会处理。它被曾经用来在每次flush的时候处理,但是现在会在每次完成merge操作后处理,如2.4版本中即如此。如果你想强行执行commit,请调用commit方法或者close这个writer。一旦一个commit完成后,新打开的IndexReader实例将会看到索引中该commit更改的数据。当以这种模式运行时,当优化(optimize)或者片断合并(segment merges)正在进行(take place)的时候需要小心地重新刷新(refresh)你的readers,因为这两个操作会绑定(tie up)可观的(substantial)磁盘空间。
不管(Regardless)autoCommit参数如何,一个IndexReader或者IndexSearcher只会看到索引在它打开的当时的状态。任何在索引被打开之后提交到索引中的commit信息,在它被重新打开之前都不会见到。当一条索引暂时(for a while)将不会有更多的文档被添加,并且期望(desired)得到最理想(optimal)的检索性能(performance),于是optimize()方法应该在索引被关闭之前被调用。
打开IndexWriter会为使用的Directory创建一个lock文件。尝试对相同的Directory打开另一个IndexWriter将会导致(lead to)一个LockObtainFailedException异常。如果一个建立在相同的Directory的IndexReader对象被用来从这条索引中删除文档的时候,这个异常也会被抛出。
专家(Expert):IndexWriter允许指定(specify)一个可选的(optional)IndexDeletionPolicy实现。你可以通过这个控制什么时候优先的提交(prior commit)从索引中被删除。缺省的策略(policy)是KeepOnlyLastCommitDeletionPolicy类,在一个新的提交完成的时候它会马上所有的优先提交(prior commit)(这匹配2.2版本之前的行为)。创建你自己的策略能够允许你明确地(explicitly)保留以前的”point in time”提交(commit)在索引中存在(alive)一段时间。为了让readers刷新到新的提交,在它们之下没有被删除的旧的提交(without having the old commit deleted out from under them)。这对那些不支持“在最后关闭时才删除”语义(”delete on last close” semantics)的文件系统(filesystem)如NFS,而这是Lucene的“point in time”检索通常所依赖的(normally rely on)。
专家(Expert):IndexWriter允许你分别修改MergePolicy和MergeScheduler。MergePolicy会在该索引中的segment有更改的任何时候被调用。它的角色是选择哪一个merge来做,如果有(if any)则传回一个MergePolicy.MergeSpecificatio来描述这些merges。它还会选择merges来为optimize()做处理,缺省是LogByteSizeMergePolicy。然后MergeScheduler会通过传递这些merges来被调用,并且它决定什么时候和怎么样来执行这些merges处理,缺省是ConcurrentMergeScheduler。
4.2.2 org.apache.lucene.index.DocumentsWriter
DocumentsWriter是由IndexWriter调用来负责处理多个文档的类,它通过与Directory类及Analyzer类、Scorer类等将文档内容提取出来,并分解成一组term列表再生成一个单一的segment所需要的数据文件,如term频率、term位置、term向量等索引文件,以便SegmentMerger将它合并到统一的segment中去。以下是它的类图:

该类可接收多个添加的文档,并且直接写成一个单独的segment文件。这比为每一个文档创建一个segment(使用DocumentWriter)以及对那些segments执行合作处理更有效率。
每一个添加的文档都被传递给DocConsumer类,它处理该文档并且与索引链表中(indexing chain)其它的consumers相互发生作用(interacts with)。确定的consumers,就像StoredFieldWriter和TermVectorsTermsWriter,提取一个文档的摘要(digest),并且马上把字节写入“文档存储”文件(比如它们不为每一个文档消耗(consume)内存RAM,除了当它们正在处理文档的时候)。
其它的consumers,比如FreqProxTermsWriter和NormsWriter,会缓存字节在内存中,只有当一个新的segment制造出的时候才会flush到磁盘中。
一旦使用完我们分配的RAM缓存,或者已添加的文档数目足够多的时候(这时候是根据添加的文档数目而不是RAM的使用率来确定是否flush),我们将创建一个真实的segment,并将它写入Directory中去。
4.3 索引创建过程
文档的索引过程是通过DocumentsWriter的内部数据处理链完成的,DocumentsWriter可以实现同时添加多个文档并将它们写入一个临时的segment中,完成后再由IndexWriter和SegmentMerger合并到统一的segment中去。DocumentsWriter支持多线程处理,即多个线程同时添加文档,它会为每个请求分配一个DocumentsWriterThreadState对象来监控此处理过程。处理时通过DocumentsWriter初始化时建立的DocFieldProcessor管理的索引处理链来完成的,依次处理为DocFieldConsumers、DocInverter、TermsHash、FreqProxTermsWriter、TermVectorsTermsWriter、NormsWriter以及StoredFieldsWriter等。
索引创建处理过程及类的主线请求链表如下图所示:

下面介绍主要步骤的处理过程
4.3.1 DocFieldProcessorPerThread.processDocument()
该方法是处理一个文档的调度函数,负责整理文档的各个fields数据,并创建相应的DocFieldProcessorPerField对象来依次处理每一个field。该方法首先调用索引链表的startDocument()来初始化各项数据,然后依次遍历每一个fields,将它们建立一个以field名字计算的hash值为key的hash表,值为DocFieldProcessorPerField类型。如果hash表中已存在该field,则更新该FieldInfo(调用FieldInfo.update()方法),如果不存在则创建一个新的DocFieldProcessorPerField来加入hash表中。注意,该hash表会存储包括当前添加文档的所有文档的fields信息,并根据FieldInfo.update()来合并相同field名字的域设置信息。
建立hash表的同时,生成针对该文档的fields[]数组(只包含该文档的fields,但会共用相同的fields数组,通过lastGen来控制当前文档),如果field名字相同,则将Field添加到DocFieldProcessorPerField中的fields数组中。建立完fields后再将此fields数组按field名字排序,使得写入的vectors等数据也按此顺序排序。之后开始正式的文档处理,通过遍历fields数组依次调用DocFieldProcessorPerField的processFields()方法进行(下小节继续讲解),完成后调用finishDocument()完成后序工作,如写入FieldInfos等。
下面举例说明此过程,假设要添加如下一个文档:
| 文档域 |
内容 |
是否索引 |
| title |
Lucene 源码分析 |
true |
| url |
http://javenstudio.org |
false |
| content |
索引是如何创建的 |
true |
| content |
索引的创建过程 |
true |
下图描述处理后fields数组的数据结构

Lucene 源码剖析
5索引是如何存储的
5.1 数据存储类Directory
Directory及相关类负责文档索引的存储。
5.1.1 org.apache.lucene.store.Directory
一个Directory对象是一系列统一的文件列表(a flat list of files)。文件可以在它们被创建的时候一次写入,一旦文件被创建,它再次打开后只能用于读取(read)或者删除(delete)操作。并且同时在读取和写入的时候允许随机访问(random access)。
在这里并不直接使用Java I/O API,但是更确切地说,所有I/O操作都是通过这个API处理的。这使得读写操作方式更统一起来,如基于内存的索引(RAM-based indices)的实现(即RAMDirectory)、通过JDBC存储在数据库中的索引、将一个索引存储为一个文件的实现(即FSDirectory)。
Directory的锁机制是一个LockFactory的实例实现的,可以通过调用Directory实例的setLockFactory()方法来更改。

5.1.2 org.apache.lucene.store.FSDirectory
FSDirectory类直接实现Directory抽象类为一个包含文件的目录。目录锁的实现使用缺省的SimpleFSLockFactory,但是可以通过两种方式修改,即给getLockFactory()传入一个LockFactory实例,或者通过调用setLockFactory()方法明确制定LockFactory类。
目录将被缓存(cache)起来,对一个指定的符合规定的路径(canonical path)来说,同样的FSDirectory实例通常通过getDirectory()方法返回。这使得同步机制(synchronization)能对目录起作用。

5.1.3 org.apache.lucene.store.RAMDirectory
RAMDirectory类是一个驻留内存的(memory-resident)Directory抽象类的实现。目录锁的实现使用缺省的SingleInstanceLockFactory,但是可以通过setLockFactory()方法修改。

5.1.4 org.apache.lucene.store.IndexInput
IndexInput类是一个为了从一个目录(Directory)中读取文件的抽象基类,是一个随机访问(random-access)的输入流(input stream),用于所有Lucene读取Index的操作。BufferedIndexInput是一个实现了带缓冲的IndexInput的基础实现。

5.1.5 org.apache.lucene.store.IndexOutput
IndexOutput类是一个为了写入文件到一个目录(Directory)中的抽象基类,是一个随机访问(random-access)的输出流(output stream),用于所有Lucene写入Index的操作。BufferedIndexOutput是一个实现了带缓冲的IndexOutput的基础实现。RAMOuputStream是一个内存驻留(memory-resident)的IndexOutput的实现类。

文档内容是如何分析的
Analyzer类负责分析文档结构并提取内容。
6.1 文档分析类Analyzer
6.1.1 org.apache.lucene.store.Analyzer
Analyzer类构建用于分析文本的TokenStream对象,因此(thus)它表示(represent)用于从文本中分解(extract)出组成索引的terms的一个规则器(policy)。典型的(typical)实现首先创建一个Tokenizer,它将那些从Reader对象中读取字符流(stream of characters)打碎为(break into)原始的Tokens(raw Tokens)。然后一个或更多的TokenFilters可以应用在这个Tokenizer的输出上。警告:你必须在你的子类(subclass)中覆写(override)定义在这个类中的其中一个方法,否则的话Analyzer将会进入一个无限循环(infinite loop)中。

6.1.2 org.apache.lucene.store.StandardAnalyzer
StandardAnalyzer类是使用一个English的stop words列表来进行tokenize分解出文本中word,使用StandardTokenizer类分解词,再加上StandardFilter以及LowerCaseFilter以及StopFilter这些过滤器进行处理的这样一个Analyzer类的实现。

Lucene 源码剖析
7如何给文档评分
Similarity类负责给文档评分。
7.1 文档评分类Similarity
7.1.1 org.apache.lucene.search. Similarity
Similarity类实现算分(scoring)的API,它的子类实现了检索算分的算法。DefaultSimilarity类是缺省的算分的实现,SimilarityDelegator类是用于委托算分(delegating scoring)的实现,在Query.getSimilarity(Searcher)}的实现里起作用,以便覆写(override)一个Searcher中Similarity实现类的仅有的确定方法(certain methods)。

查询q相对于文档d的分数与在文档和查询向量(query vectors)之间的余弦距离(cosing-distance)或者点乘积(dot-product)有关系(correlates to),文档和查询向量存于一个信息检索(Information Retrieval)的向量空间模型(Vector Space Model (VSM))之中。一篇文档的向量与查询向量越接近(closer to),它的得分也越高(scored higher),这个分数按如下公式计算:
![]()
其中:
1. tf(t in d) 与term的出现次数(frequency)有关系(correlate to),定义为(defined as)term t在当前算分(currently scored)的文档d中出现(appear in)的次数(number of times)。对一个给定(gived)的term,那些出现此term的次数越多(more occurences)的文档将获得越高的分数(higher score)。缺省的tf(t in d)算法实现在DefaultSimilarity类中,公式如下:

2. idf(t) 代表(stand for)反转文档频率(Inverse Document Frequency)。这个分数与反转(inverse of)的docFreq(出现过term t的文档数目)有关系。这个分数的意义是越不常出现(rarer)的term将为最后的总分贡献(contribution)更多的分数。缺省idff(t in d)算法实现在DefaultSimilarity类中,公式如下:

3. coord(q,d) 是一个评分因子,基于(based on)有多少个查询terms在特定的文档(specified document)中被找到。通常(typically),一篇包含了越多的查询terms的文档将比另一篇包含更少查询terms的文档获得更高的分数。这是一个搜索时的因子(search time factor)是在搜索的时候起作用(in effect at search time),它在Similarity对象的coord(q,d)函数中计算。
4. queryNorm(q) 是一个修正因子(normalizing factor),用来使不同查询间的分数更可比较(comparable)。这个因子不影响文档的排名(ranking)(因为搜索排好序的文档(ranked document)会增加(multiplied)相同的因数(same factor)),更确切地说只是(but rather just)为了尝试(attempt to)使得不同查询条件(甚至不同索引(different indexes))之间更可比较性。这是一个搜索时的因子是在搜索的时候起作用,由Similarity对象计算。缺省queryNorm(q)算法实现在DefaultSimilarity类中,公式如下:
![]()
sumOfSquaredWeights(查询的terms)是由查询Weight对象计算的,例如一个布尔(boolean)条件查询的计算公式为:
![]()
5. t.getBoost() 是一个搜索时(search time)的代表查询q中的term t的boost数值,具体指定在(as specified in)查询的文本中(参见查询语法),或者由应用程序调用setBoost()来指定。需要注意的是实际上(really)没有一个直接(direct)的API来访问(accessing)一个多个term的查询(multi term query)中的一个term 的boost值,更确切地说(but rather),多个terms(multi terms)在一个查询里的表示形式(represent as)是多个TermQuery对象,所以查询里的一个term的boost值的访问是通过调用子查询(sub-query)的getBoost()方法实现的。
6. norm(t,d) 是提炼取得(encapsulate)一小部分boost值(在索引时间)和长度因子(length factor):
ú document boost – 在添加文档到索引之前通过调用doc.setBoost()来设置。
ú Field boost – 在添加Field到文档之前通过调用field.setBoost()来设置。
ú lengthNorm(field) – 在文档添加到索引的时候,根据(in accordance with)文档中该field的tokens数目计算得出,所以更短(shorter)的field会贡献更多的分数。lengthNorm是在索引的时候起作用,由Similarity类计算得出。
当一篇文档被添加到索引的时候,所有上面计算出的因子将相乘起来(multiplied)。如果文档拥有多个相同名字的fields(multiple fields with same name),所有这些fields的boost值也会被一起相乘起来(multiplied together):
![]()
然而norm数值的结果在被存储(stored)之前被编码成(encoded as)一个单独的字节(single byte)。在检索的时候,这个norm字节值从索引目录(index directory)中读取出来,并解码回(decoded back)一个norm浮点数值(float value)。这个编/解码(encoding/decoding)行为,会缩减(reduce)索引的大小(index size),这得自于(come with)精度损耗的代价(price of precision loss)- 它不保证decode(encode(x))=x,举例来说decode(encode(0.89))=0.75。还有需要注意的是,检索的时候再修改评分(scoring)的这个norm部分已近太迟了,例如,为检索使用不同的Similarity。
以前收集的关于lucene分析的资料,版本有点老,已经忘了是在哪找到的了,如果你是文档作者,侵犯了你的版权,@我即可