NIPS2017的最佳论文今年被“冷扑大师”拿下,在深度学习大行其道的今天,一个使用非深度学习方法的研究拿下最佳论文,着实有些意外,算是“冷扑大师”创造的一个小冷门。
12月18日,《Science》上发布了题为《Superhuman AI for heads-up no-limit poker: Libratus beats top professionals》的文章,介绍“冷扑大师”的工作原理。同一天,论文的两位作者——CMU博士生Noam Brown和教授Tuomas Sandholm 在Reddit上进行Q&A问答。对大家关心的问题,比如:为什么不使用深度学习?AlphaZero会打败Libratus吗?不完备信息博弈的下一个大方向等一一作了回答。
以下为第一人称的介绍:
大家好!我们是CMU博士生Noam Brown和Tuomas Sandholm教授。今年早些时候,我们的AI Libratus首次在无限注扑克(详细说来,是一对一无限注德州扑克)中击败了顶级职业玩家。我们在持续了20天的12万手比赛中击败了4位顶级人类玩家。

我们最近的论文讨论了AI,安全和子博弈(subgame)博弈的核心技术之一,赢得了NIPS 2017最佳论文奖。
我们很高兴回答您关于Libratus,比赛,人工智能,不完备信息博弈,卡内基梅隆,教授或博士生的学术生活等问题,或者您可能遇到的任何其他问题!
什么时候会实现通用人工智能?问:AI在接下来2年到5年,或者5年到10年内,最不可能解决的问题有哪些?(概率大于90%)未来会有哪些AI进展会让你觉得(大于40%的概率)通用人工智能会在2-5年、5-10年或者1年内实现?
NoamBrown:这是一个非常主观的问题,所以我只说说我的个人看法。我不认为AI在接下来的10年内可以原创地写出一部可以获奖的、具有思想启发性的作品。如果这真的发生了,我可能会非常害怕通用人工智能的诞生。
为什么不使用深度学习?问:Libratus没有利用深度学习。是故意为之吗?或者就是没有想过使用它?又或者是试过了,没有效果?考虑到DeepStack(另一个扑克AI,使用深度学习)的成功,如果来一次,你会考虑使用它吗?
NoamBrown:Libratus不使用任何深度学习。我们希望这有助于人们认识到AI比深度学习更重要!深度学习本身不足以玩扑克这样的游戏。
也就是说,我们介绍的技术与深度学习并不矛盾。我会把它们描述成MCTS(蒙特卡洛树搜索)的替代品。对于像扑克这样的游戏来说,深度学习并不是特别必要的。但是我认为对于其他一些游戏来说,某种类型的函数近似是相当有用的。
DeepStack确实使用深度学习,但不清楚它是多么有效。举例来说,它并没有一对一地战胜过人类玩家。我认为DeepStack做得相当好的原因是因为它使用了由两个团队独立并且同时开发的嵌套子博弈解决方案。这并不需要深度学习。 Libratus使用嵌套子博弈解决方案的更高级版本,加上一些其他的好东西,带来了真正强大的性能。
追加提问:你为什么没有最终在模型中使用强化学习?似乎是自然而然的事情。
NoamBrown :我们在Libratus中使用了CFR的变体。具体说来,我们使用Monte Carlo CFR来计算蓝图策略,而CFR +则是在实时子博弈求解中。
CFR是一种类似于强化学习的self-play算法,但是CFR另外考虑了在self-play期间未被选择的假设动作的收益。 CFR存在一个纯粹的强化学习变体,但在实践中找到一个好的策略还需要更长的时间。
如何评价DeepStack,谁先做的?问:你如何看2017年5月在“科学”杂志上发布 DeepStack(https://arxiv.org/abs/1701.01724)?你们的工作发表在 NIPS 2017,是在2017年12月,是谁先做的呢?你们之间有合作吗?
(吃瓜)群众:我觉得Libratus可以碾压DeepStack。两个Bot所面对的玩家质量有着天壤之别。绝大多数的DeepStack的对手都是非常弱的专业扑克玩家(尽管有一些人非常熟练),我不认为它的对手都是专业的玩家,并且他们还设立了激励机制,以便奖励高回报方法(因为只有第一名被可以得到报酬)。
TuomasSandholm :虽然DeepStack在其方法中也有有趣的想法,但我同意LetterRip的评估。
现在我将讨论两个AI之间的一些相似之处和不同之处。我还建议阅读http://science.sciencemag.org/content/early/2017/12/15/science.aao1733,其中描述了Libratus,并包括与DeepStack的比较。
DeepStack的算法类似于Libratus的嵌套子博弈求解,他们称之为不断的重新求解。和Libratus一样,对手的确切赌注大小被添加到要解决的剩余子博弈的新抽象中。我们于2016年10月在网上发布了我们的论文(2017年2月发表在AAAI-17研讨会),DeepStack团队于2017年1月在arXiv上发表了他们的论文(2017年春末在Science上发表了)。考虑到开发这些技术需要多长时间,我认为这两个团队在这之前已经有了几个月的时间来研究这些想法,所以可以说它们是独立发展的、并行的。而且,这些技术有显著的差异。
另一个区别在于这两个AI如何在前两轮进行下注。 DeepStack通过神经网络估算深度极限值,在前两轮下注中解决了深度受限的子博弈问题。这允许它总是可以对对手off-tree行动的实时响应进行计算,而Libratus在前两轮中通常根据其的预先计算的蓝图策略(除了如果该plot很大,会使用其子博弈解算器)实时完成。由于在前两轮,Libratus通常根据提前计算的蓝图策略进行游戏,因此它会将对手的下注大小轮回到附近的抽取中。这些轮次的蓝图行动抽象是密集的,以弱化弱点。此外,Libratus还有一个独特的自我完善模块,用于随着时间的推移增加蓝图策略,以在对手聚集的策略中找到潜在漏洞,在部分游戏树中计算更接近纳什均衡的近似值。
在评估方面。 除了LetterRip上面写到的关于对人类的评估之外,DeepStack从来没有被证明超越了之前公开的顶级AI,而Libratus击败了之前最好的HUNL扑克AI Baby Tartanian8(赢得了2016年度计算机扑克大赛),性能大幅度提高(63MBb /局)。
在合作方面,两个研究小组已经相继发表了13年的技术和技术。此外,加拿大扑克组织负责人Michael Bowling在CMU获得了博士学位,并且在博士学位委员会任职。但是,我们迄今还没有直接合作。
AlphaZero会打败Libratus吗?
问:考虑到国际象棋最近的例子,AlphaZero会打败Libratus吗?
TuomasSandholm:不会。AlphaZero不玩不完备的信息博弈。
工业界能有什么应用?问:你认为这个研究对工业界最有用的应用是什么?你认为你的技术可以用来模拟贸易谈判吗?
NoamBrown :我认为这个研究对于将AI引入现实世界至关重要,因为大多数现实世界的战略交互都涉及隐藏的信息。这是我们在这项研究中要解决的根本问题。贸易谈判无疑是一个未来的应用,拍卖、金融市场、网络安全互动和军事情景也会是未来的应用。
也就是说,从像扑克这样的博弈延伸到现实世界的交互(例如贸易谈判),这肯定是一个挑战。但是如果能建立一个贸易谈判的模型,这个研究肯定是可以应用的。这将是未来研究的一个有趣方向。
下一个重大突破是什么?
问:你认为在解决不完备信息博弈方面,下一个重大突破将是什么?
NoamBrown :我认为目前Starcraft和Dota2的工作非常有趣!这些都是不完备信息博弈,这些技术将与这些游戏非常相关。
我也希望我们能看到能够处理涉及谈判和临时合作的半合作游戏的人工智能。这是我真正感兴趣的研究领域。
问:接下来你们会瞄准哪些任务或者游戏?
NoamBrown:有很多有趣的方向!我不认为我们只会选择一个
一个非常有趣的研究是像谈判一样的“半合作博弈”。在这里,玩家们有动力一起工作,但都试图最大化他们的个人的有用性。现有技术在这类游戏中是完全失败的,所以有很多有趣的研究要做。还有很多娱乐游戏能够捕捉到这种动态,例如Settlers of Catan(交易)和Diplomacy(谈判)。
我也认为像Dota2和暴风雪这样的即时战略游戏是非常有趣的领域,作为不完备的信息博弈,所有关于扑克的工作将与制定一个战无不胜的策略非常相关,这个策略可以击败这些游戏中的顶级人类。
我也认为,如何弥补AlphaZero和Libratus之间的差异,这会是一个非常有趣的问题, 我们拥有能很好地玩围棋和国际象棋这样的游戏的技术,并且像扑克这样的单独领域也分离出很棒的技术,但是我们应该有一个能够很好地玩所有这些博弈的算法。现在这些方法之间有很大的差距,如何弥合这个差异还不清楚。
一定要用超级计算机来完成吗?问:如果将Libratus在非超级计算机(或者只是一个较弱的单元)上运行,通过将类似的操作分组在一起并简化决策树,我们会看到多大的差异?结果会有很大不同/不是最理想的吗?
NoamBrown :在比赛之前,我们不知道如何击败顶级人类玩家。我们没有试图去猜测我们需要击败哪些资源,而是尽可能多地利用了所有资源。因此我们使用了超级计算机。我猜不用超级计算机,你在PC上也能实现超越人类的表现。 15 BB / 100的胜率表明,超级计算机的算力绝对是过度的。不过,使用普通计算机会损失一些准确性,减少投注数量,但我不认为这将是一个巨大的成本。
我也认为随着这些技术的提高,计算成本会下降。我们已经看到人工智能在不完备信息游戏方面的巨大进步,没有理由认为这个速度在未来几年会放缓。我想在5年之内,我们会看到一个像在智能手机上运行的Libratus一样强大的AI。
问:与在超级计算机上运行PIOsolver sim相比,你的软件有什么不同?
NoamBrown :有一些差异。 Libratus正在使用比PIOsolver更好的产品。这里有几个为什么你不能只使用PIOsolver进行这种比赛的原因。 (提醒:我对PIOsolver的知识是相当有限的,但我会尽我所能回答。)
1)PIOsolver需要一个人来输入双方玩家的belief分布。 Libratus自己就能完全确定这些信息。
2)通过选择在均衡中以零概率发生的行为,PIOsolver会被欺骗。如果你下注10%,PIOsolver 认为这不应该发生,对手牌的置信分布就不确定,给出的结果也就乱七八糟。我认为PIOsolver有一个明确的免责声明,如果对手做了“怪异”的事情,你不应该相信它。显然,如果你正在对付那些试图在AI中发现弱点的顶级人物,这将是一个严重的问题。 Libratus没有这个弱点。即使你选择在均衡中以零概率出现的行为,它也会对这些行为有一个稳健和正确的回应。
你心目中机器学习研究前五名的学校
问:你认为机器学习研究的排名前五的大学有哪些?
TuomasSandholm :这取决于机器学习的确切分支,这是我的粗略排名:CMU,Berkeley,Stanford,MIT,UMass,UW。
拿到的奖金怎么分配?问: 好棒的科学。谢谢你又推进了人类的知识。你打算怎么花赢来的钱?有没有在游艇上开party的计划?邀请我了吗?
NoamBrown:所有的钱都付给了专业玩家(当然取决于他们玩得多好)。当然我也很希望拿一部分奖金来做我学生的费用开销。

Sicence论文:AI玩德扑的三大难点,Libratus的三大模块
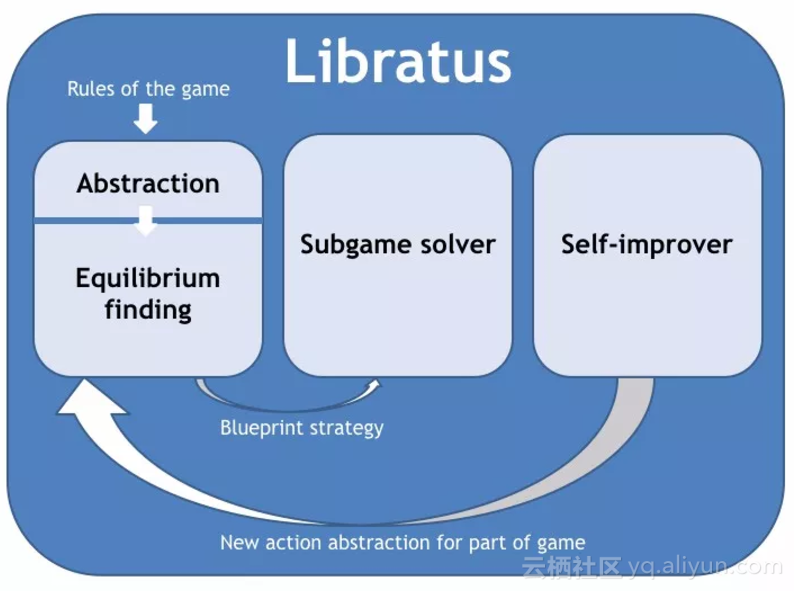
早在11月新智元主办的AI World 2017 世界人工智能大会上,TuomasSandholm就曾介绍过冷扑大师的三大模块,这次登上Science论文介绍的也大致相同。
Alpha Go在围棋领域的成功,可能会让人们认为人工智能已经超越人类的智慧,这是因为以Alpha Go为代表的围棋以及跳棋、象棋等棋类,是基于人工智能在基准游戏(benchmark games)中对人类的表现,这些棋类通常被称为“完美信息游戏(perfect-information games )”,玩家可以在每一点上都知道游戏的确切状态。
相反,在不完备信息游戏中,一些关于游戏状态的信息是隐藏于玩家的,例如,在德扑中,对手可能有对方不知道的隐藏牌。
隐藏的信息使游戏变得复杂得多。首先,AI玩德扑不是简单纯地搜索简单的动作序列,一个不完备信息游戏的AI必须决定如何恰当地平衡动作,这样对手就不会发现太多关于AI的原始信息。例如,在任何竞争性的扑克策略中,诈唬(bluffing)都是一个必要的特性,但是一直虚张声势将是一个糟糕的策略。换句话说,一个动作的价值取决于它被播放的概率。
其次,隐藏信息游戏的不同部分不能孤立地考虑。在给定情况下的最优策略可能取决于在没有发生的情况下所采用的策略。作为一种策略,一个具有竞争力的AI必须始终考虑整个游戏的策略。
无限注德州扑克“No-limit Texas hold’em”有庞大的规模和策略复杂性,是一般算法在不完善的信息博弈里面难以攻克的游戏之一,在Libratus之前,没有AI曾击败顶尖的人类选手。
Libratus的三大模块
根据论文,Libratus主要包括三大模块。
第一个模块:蓝图策略解决方案。
一对一无限注德扑有10的161次方种不同情况,Libratus将其抽象成一个比较简单的博弈,然后计算出抽象的游戏理论策略。这个抽象的解决方案为游戏的早期阶段提供了详细的策略,我们将抽象的解决方案称为blueprint策略。
第二个模块:嵌套安全子博弈求解(Nested safe subgame solving)。当游戏进入到后面部分时,Libratus的第二个模块构造了这个子游戏的细粒度抽象,并实时解决它。
与完全信息游戏的子博弈解决技术不同,Libratus并没有孤立地解决子博弈抽象;相反,它确保了子博弈的细粒度解决方案适合整个游戏的蓝图策略。每当对手做出不属于抽象的动作时,就会用包含的动作来解决子博弈。
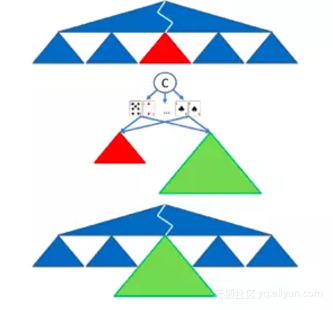
上:在游戏中出现子博弈。 中间:算法通过增强子博弈来确定该子博弈的更详细的策略,其中在每次迭代中对手被随机发牌,可选期望值来自旧的抽象(红色)或更新更细粒度的抽象(绿色),双方的策略都可以改变。 这迫使Libratus制定更细粒度的策略,至少和原来的抽象对手一样。 底部:用新的策略代替旧的策略。
第三大模块:自我完善。
Libratus的第三个模块——自我完善,填补了blueprint抽象中缺少的分支,并计算了这些分支的游戏理论策略。原则上,一个人可以提前进行所有的计算,但是游戏树太大了,这种计算不可行。
为了驯服这种复杂性,Libratus根据对手的实际赌注大小,来检测blueprint中潜在的漏洞,从而弥补自身不足。

一个嵌套子博弈解决的可视化图标。每次在游戏中进行子博弈时,就会构建一个更详细的抽象,并解决这个子博弈。
最后,Libratus的成功有着非凡的意义。因为隐藏信息在现实世界的战略中无处不在,例如商业战略、谈判、战略定价、金融、网络安全、军事应用等,这些都使得对非完美信息游戏的通用技术的研究显得尤为重要。
原文发布时间为:2017-12-19
本文作者:弗格森 常佩琦 张乾 文强
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号

