今天要介绍的是消息中间件KafKa,应该说是一个很牛的中间件吧,背靠Apache 与很多有名的中间件搭配起来用效果更好哦 ,为什么不用RabbitMQ,因为公司需要它。
网上已经有很多怎么用和用到哪的内容,但结果很多人都倒在了入门第一步 环境都搭不起来,可谓是从了解到放弃,所以在此特记录如何在linux环境搭建,windows中配置一样,只是启动运行bat文件。
想要用它就先必须了解它能做什么及能做到什么程度,先看看它是什么吧。
当今社会各种应用系统诸如商业、社交、搜索、浏览等像信息工厂一样不断的生产出各种信息,在大数据时代,我们面临如下几个挑战:
如何收集这些巨大的信息
如何分析它
如何及时做到如上两点
以上几个挑战形成了一个业务需求模型,即生产者生产(produce)各种信息,消费者消费(consume)(处理分析)这些信息,而在生产者与消费者之间,需要一个沟通两者的桥梁-消息系统。从一个微观层面来说,这种需求也可理解为不同的系统之间如何传递消息。
kafka 应用场景
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
流式处理:比如spark streaming和storm
事件源解耦 在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
冗余有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
扩展性 因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。
灵活性 & 峰值处理能力 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
可恢复性 系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
顺序保证 在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。Kafka能保证一个Partition内的消息的有序性。
缓冲 在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行———写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。
用于数据流 在一个分布式系统里,要得到一个关于用户操作会用多长时间及其原因的总体印象,是个巨大的挑战。消息系列通过消息被处理的频率,来方便的辅助确定那些表现不佳的处理过程或领域,这些地方的数据流都不够优化。
异步通信 很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
Kafka主要特点:
同时为发布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失。
分布式系统,易于向外扩展。所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器。
消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡。
支持online和offline的场景。
Kafka的架构:
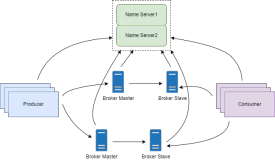
Kafka 的整体架构非常简单,是显式分布式架构,producer、broker(kafka)和consumer都可以有多个。 Producer,consumer实现Kafka注册的接口,数据从producer发送到broker,broker承担一个中间缓存和分发的作用。 broker分发注册到系统中的consumer。broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。客户端和服务器端的通信,是基 于简单,高性能,且与编程语言无关的TCP协议。
几个基本概念:
- Topic:特指Kafka处理的消息源(feeds of messages)的不同分类。
- Partition:Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。
- Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
- Producers:消息和数据生产者,向Kafka的一个topic发布消息的过程叫做producers。
- Consumers:消息和数据消费者,订阅topics并处理其发布的消息的过程叫做consumers。
- Broker:缓存代理,Kafa集群中的一台或多台服务器统称为broker。
消息发送的流程:
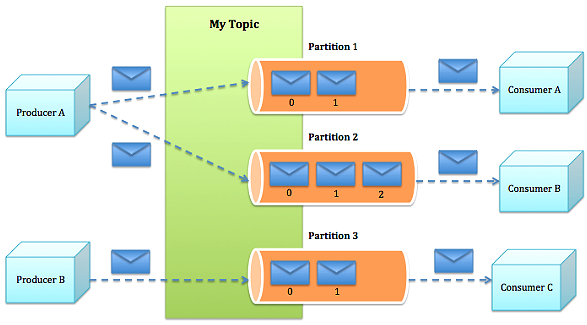
- Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面
- kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长(可配置),而不关注消息是否被消费。
- Consumer从kafka集群pull数据,并控制获取消息的offset
环境
CentOS7.0
kafka_2.11-0.10.1.0版本
用root用户安装
Java环境,最好是最新版本的。
安装Zookeeper
分布式时多机间要确保能正常通讯,关闭防火墙或让涉及到的端口通过。
下载
去官网下载 :http://kafka.apache.org/downloads.html 选择最新版本(在此下载编译好的包,不要下载src源码包)。
下载后放进CentOS中的/usr/local/ 文件夹中,并解压到当前文件中 /usr/local/kafka212
安装配置
由于Kafka集群需要依赖ZooKeeper集群来协同管理,所以需要事先搭建好ZK集群。
安装之前先要启动zookeeper,如何安装可参考之前的 一步到位分布式开发Zookeeper实现集群管理 一文
将压缩文件夹压到当前文件夹
tar -zxvf kafka_2.12-0.10.2.0.tgz,产生文件夹kafka_2.12-0.10.2.0 并更改名为kafka212
进入config目录,修改server.properties文件
vi server.properties
broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样 port=9092 #当前kafka对外提供服务的端口默认是9092 log.dirs=//usr/local/kafka212/kafka-logs zookeeper.connect=192.168.80.32:2181,192.168.80.33:2181,192.168.80.30:2181
注意:
broker.id=0 值每台服务器上的都不一样
启动
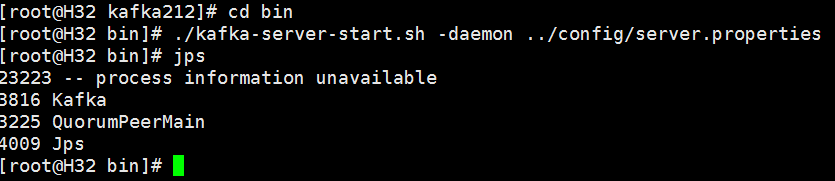
首先启动独立的ZK集群,三台都要启动(./zkServer.sh start) 进入到kafka的bin目录,然后启动服务 ./kafka-server-start.sh ../config/server.properties (三台服务器都要启动) 或启动daemon守护进程后台程序 进入到kafka的bin目录 ./kafka-server-start.sh -daemon ../config/server.properties
验证启动进程
jps
显示包含
25014 QuorumPeerMain
25778 Kafka
使用客户端进入zk
[root@H32 bin]# zkCli.sh -server 192.168.80.32:2181
查看目录情况
[zk: 192.168.80.32:2181(CONNECTED) 0] ls /
显示
[controller_epoch, controller, brokers, zookeeper, test, admin, isr_change_notification, consumers, config]

创建一个topic:
[root@H32 bin]# ./kafka-topics.sh --create --zookeeper 192.168.80.32:2181,192.168.80.33:2181,192.168.80.30:2181 --replication-factor 3 --partitions 1 --topic hotnews --replication-factor 2 #复制两份 --partitions 1 #创建1个分区 --topic #主题
查看topic状态:
[root@H32 bin]# ./kafka-topics.sh --describe --zookeeper 192.168.80.32:2181,192.168.80.33:2181,192.168.80.30:2181 --topic hotnews

发送消息:
[root@H32 bin]# ./kafka-console-producer.sh --broker-list 192.168.80.32:9092,192.168.80.33:9092,192.168.80.30:9092 --topic hotnews

接收消息:
[root@H32 bin]# ./kafka-console-consumer.sh --zookeeper 192.168.80.32:2181,192.168.80.33:2181,192.168.80.30:2181 --topic hotnews --from-beginning

NET-KafKa编程
对于net来说需要相应的插件才能与之通讯,网上比较推荐的是 rdkafka-dotnet 有需要的可以git中下载demo。
扩展
找到为0的leader的进程,并杀死
[root@bin /]# ps -ef | grep kafka kill -9 25285
启动各服务器上的kafka后,有机器访问主机时出现:
WARN Fetching topic metadata with correlation id 5 for topics [Set(hotnews)] from broker [BrokerEndPoint(1,H33,9092)] failed (kafka.client.ClientUtils$)
这里需要关闭机器的防火墙或将9092加入防火墙。
Kafka在分布式设计中有着相当重要的作用,算是一个基础工具,因此需要不断的学习了解与实践,如何处理大并发订单这只是一种场景。
这里留有一个问题:如何确定Kafka的分区数、key和consumer线程数