本文转载http://www.cnblogs.com/lxblog/archive/2012/09/29/2708724.html
在SQL中分拆列值和合并列值老生常谈了,从网上搜刮了一下并记录下来,以便不时之需 :)
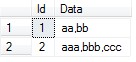
什么叫分拆列值和合并列值呢?就只是这样的,比如有如下表A结构及数据:
| Id | Data |
| 1 | aa,bb |
| 2 | aaa,bbb,ccc |
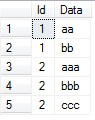
将该表A的Data字段数据根据 “,” 进行分拆得到如下表B
| Id | Data |
| 1 | aa |
| 1 | bb |
| 2 | aaa |
| 2 | bbb |
| 2 | ccc |
这就是表A-->表B 叫做分拆列值,表B-->表A 叫做合并列值。
一、分拆列值:

CREATE TABLE t_Demo1 ( Id INT, Data VARCHAR(30) ) GO INSERT INTO t_Demo1 VALUES(1,'aa,bb') INSERT INTO t_Demo1 VALUES(2,'aaa,bbb,ccc')
分拆方法一:(古老方法,适合于SQL 2000)
--方法一:适用于SQL 2000 SELECT TOP 8000 id = IDENTITY(int, 1, 1) INTO #t FROM syscolumns a, syscolumns b SELECT A.Id, SUBSTRING(A.Data, B.Id, CHARINDEX(',', A.Data + ',', B.Id) - B.Id) AS Data FROM t_Demo1 as A, #t as B WHERE SUBSTRING(',' + A.Data, B.Id, 1) = ',' DROP TABLE #t
分拆方法二:(适合于SQL2005及以上版本)
--方法二:适用于SQL 2005及之后版本 SELECT A.Id, B.Data FROM( SELECT Id, Data = CONVERT(xml,' <root> <v>' + REPLACE(Data, ',', ' </v> <v>') + ' </v> </root>') FROM t_Demo1 )A OUTER APPLY( SELECT Data = N.v.value('.', 'varchar(100)') FROM A.Data.nodes('/root/v') N(v) )B
执行结果如下图:
二、合并列值:
REATE TABLE t_Demo2 ( Id INT, Data VARCHAR(30) ) GO INSERT INTO t_Demo2 VALUES(1, 'aa') INSERT INTO t_Demo2 VALUES(1, 'bb') INSERT INTO t_Demo2 VALUES(2, 'aaa') INSERT INTO t_Demo2 VALUES(2, 'bbb') INSERT INTO t_Demo2 VALUES(2, 'ccc')
合并方法一:(适用于SQL2000 版本,只能用函数的方式来实现)
--方法一(适用于SQL2000 版本只能用函数的方式来实现): CREATE FUNCTION dbo.Fun_GetStr(@id INT) RETURNS VARCHAR(8000) AS BEGIN DECLARE @r VARCHAR(8000) SET @r = '' SELECT @r = @r + ',' + CAST(Data AS VARCHAR) FROM t_Demo2 WHERE id=@id SET @r=STUFF(@r, 1, 1, '') --或者 --SET @r=RIGHT(@r , len(@r) - 1) RETURN @r END GO --使用该函数 SELECT Id, Data = dbo.Fun_GetStr(Id) FROM t_Demo2 GROUP BY Id --或者 SELECT DISTINCT Id ,dbo.Fun_GetStr(Id) AS Data FROM t_Demo2 --删除该函数 DROP FUNCTION dbo.Fun_GetStr GO
合并方法二:(适用于SQL2005及其以后版本)
--方法二(适用于SQL2005及其以后版本) SELECT Id, Data=STUFF((SELECT ','+ Data FROM t_Demo2 AS t WHERE Id=t_Demo2.Id FOR XML PATH('')), 1, 1, '') FROM t_Demo2 GROUP BY Id
执行结果如下图:
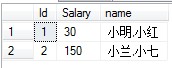
三、合并列值并使用聚合函数:
CREATE TABLE t_Price ( Id INT, Salary FLOAT, Name NVARCHAR(10) ) GO INSERT INTO t_Price VALUES(1,10,'小明') INSERT INTO t_Price VALUES(1,20,'小红') INSERT INTO t_Price VALUES(2,50,'小兰') INSERT INTO t_Price VALUES(2,100,'小七') GO --方法一:(利用函数) CREATE FUNCTION Fun_HbStr(@id int) RETURNS NVARCHAR(100) AS BEGIN DECLARE @s NVARCHAR(100) SELECT @s=ISNULL(@s+',','')+ CAST(Name AS NVARCHAR) FROM t_Price where id=@id RETURN @s END GO SELECT Id ,SUM(Salary) AS Salary,dbo.Fun_HbStr(Id) AS Data FROM t_Price GROUP BY Id --删除函数 DROP FUNCTION Fun_HbStr GO --方法二: SELECT Id, SUM(Salary) AS Salary,name=STUFF((SELECT ','+ Name FROM t_Price AS t WHERE Id=t_Price.Id FOR XML PATH('')), 1, 1, '') FROM t_Price GROUP BY Id --删除表 t_Price DROP TABLE t_Price GO
执行结果如下图: