简单来说,它主要用来把所有特征值范围映射至同样的范围里面如(0,1)、(-1,1)、(-0.5,0.5)等。
Feature scaling (数据规范化) 是数据挖掘或机器学习常用到的步骤,这个步骤有时对算法的效率和准确率都会产生巨大的影响。
对精度的影响:很明显,这个步骤的必要性要依赖于数据特征的特性,如果有>=2特征,并且不同特征间的值变化范围差异大,那就很有必要使用Feature scaling。比如说,在信用卡欺诈检测中,如果我们只使用用户的收入作为学习特征,那就没有必要做这个步骤。但是如果我们同时使用用户的收入和用户年龄两个特征的话,在建模之前采用这个步骤就很有可能能提高检测精度,这是因为用户收入这个特征的取值范围可能为[50000,60000]甚至更大,但用户年龄只可能是[20,100]左右,这时候,假如说我用K最近邻的方法去做检测的话,用户收入这个特征的相似度对检测结果的影响将会大大大于用户年龄的作用,然而事实上,这两个特征对欺诈检测可能有着同等的重要性。因此,假如我们在检测实施前,对着两个特征进行规范化,那我们的检测方法中就能真正地同等对待它们。
对效率的影响:再举一个例子,该例子来源于Ng教授的ML课程,
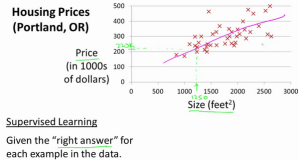
例子如上图,在该例子中,我们想用线性回归根据房屋的大小和房屋的卧室数量来预测房价,采用的优化方法为batch gradient descent。在建立模型的过程中,如果不对房屋的大小和房屋的卧室数量两个特征规范化,我们的优化问题将会在很skewed的区域中进行(如左图所示),这样会使得batch gradient descent的收敛很慢。而当我们对其进行规范化之后,问题就会转变为偏圆形的空间中优化,这时候,batch gradient descent的收敛速度将会得到大幅度提高。

实践:关于Feature Scaling: get every feature into approximately into [-1, 1]
a:每个维度的特征减去此维度特征均值,除以此维度特征的最大值与最小值之差:
(xi - mean(xi)) / (max(xi) - min(xi)) (mean normalization)
b:每个维度的特征减去此维度的均值,除以这个维度的标准差:
(xi - mean(xi)) / std(xi) (mean normalization)
c:常数项x0 = 1,已经在(或接近)合理的range内,无需缩放
特征缩放有助于算法快速收敛,可以通过迭代算法的公式来解释:
e:使用缩放特征计算得到的模型参数去做预测,预测样本是否也需要做Feature Scaling
对于一个待预测的sample instance X,使用模型参数预测前,应首先对X进行Feature Scaling
即:X = (X - mean(xi)) / std(xi),其中,mean(xi)和std(xi)是训练样本集第i维特征的均值和方差
f:使用Normal Equation(正规方程)计算模型参数,是否需要做特征缩放?
使用正规方程计算参数时,无需进行Feature Scaling
g:Why not Feature Scaling the y ?????
与正规方程(Normal Equation)不同,梯度下降算法需要选择合适的Learning rate,以便控制
算法的迭代效果和迭代速度。通常情况下,先选择一个较小的初始学习率,观察效果,然后可
以按照3倍、10倍递增的方式逐步提高学习率,观察效果。直到能够找到一个合适的Learning rate
b:学习率过小,会导致算法迭代速度过慢,影响算法效率
a:X为design matrix,每行为一个sample instance的特征,共n + 1项,n为特征维数
每个sample instance的第一项都为1,为常数项(为便于计算而引入的)
b:X^T表示矩阵X的转置,^(-1)表示矩阵求逆,y表示训练样本中的预测值,为mx1维,m为
sample instance的个数,theta表示要计算的模型参数向量,为n + 1维
c:假设矩阵A维数为nxn,则A^(-1)的计算复杂度为O(n^3)
何时使用Normal Equation,何时使用Gradient Descent
m = number of training samples, n = number of features
n=10000时,Normal Equation需要计算逆矩阵,所以Normal Equation方法效率会慢下来,可以
考虑使用Gradient descent代替, n=100000时,计算Normal Equation中的(XT*X)^(-1)会变得非常慢,此时,definitely使用Gradient Descent。