Steffen Rendle于2010年提出Factorization Machines(下面简称FM),并发布开源工具libFM。
一、与其他模型的对比
与SVM相比,FM对特征之间的依赖关系用factorized parameters来表示。对于输入数据是非常稀疏(比如自动推荐系统),FM搞的定,而SVM搞不定,因为训出的SVM模型会面临较高的bias。还有一点,通常对带非线性核函数的SVM,需要在对偶问题上进行求解;而FM可以不用转为对偶问题,直接进行优化。
目前还有很多不同的factorization models,比如matrix factorization和一些特殊的模型SVD++, PITF, FPMC。这些模型的一个缺点是它们只适用于某些特定的输入数据,优化算法也需要根据问题专门设计。而经过一些变换,可以看出FM囊括了这些方法。
二、模型简介
2-way FM(degree = 2)是FM中具有代表性,且比较简单的一种。就以其为例展开介绍。其对输出值是如下建模:
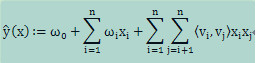
公式说明:
(1) 模型的参数包括: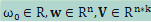 ;
;
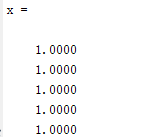
(2) n是特征维度;
(3) k是定义factorization维度的超参数,是正整数。
(4) 在FM中,如何对特征之间的依赖关系建模?首先用k维向量去描述每个维度,然后对2个维度所对应的vi和vj求点积,以此来刻画2个特征之间的特征关系。如果需要刻画x(x>2)个特征之间的关系,可以用x-way FM模型。
(5) 表面上看式子的第3项的计算复杂度为O(kn2),但其实可以经过简单的数学处理,计算复杂度降为O(kn)。
三、模型分析
他的思想应该是从推荐系统中经典的SVD模型(因子分解模型)得到的,经典的SVD模型当中相当于只有两种类型的feature,一类feature是user,一类feature是item,而libFM是把这个模型推广到了多类feature的情况。为简单起见,考虑因子维数为1的情况,SVD模型用a∗ba∗b来作为对打分的预测。而libFM要面对的是多类feature,假设是3类,那么就用a∗b+b∗c+c∗aa∗b+b∗c+c∗a来作为对结果的预测。这时候就要问了,如果feature很多,这不就有平方量级的乘法次数了么?当然不是,libFM的文章中提到,他利用((a+b+c)2−a2−b2−c2)/2((a+b+c)2−a2−b2−c2)/2来计算刚才的式子,但是你可以看到,他们其实是相等的,不同的是,这样的计算量只是线性复杂度的。当然libFM也同时支持bias项,这和经典SVD模型类似。
以上就是libFM的创新之处,其实如果很了解SVD模型,那这个改进并不难理解。
论文中还提到,经典的SVD++模型等对于SVD模型的改进,也只是libFM的一个子集而已。只要合适的去添加feature即可。比如SVD++模型就相当于对每个item增加一个feature,来描述用户是否也给这个item打过分即可。所以有了libFM以后,最需要人工解决的问题就是添加合适的feature了。
另外再说明一下推荐系统的数据如何转化成libFM接受的形式。假设User ID范围是[0,99],Item ID范围是[0,199],则定义feature 0到feature 99对应于User,feature 100到feature 299对应于Item,假设第一条打分记录是User 4对Item 9的打分,则feature 4和feature 109的取值为1,其余feature取值都是0。由于数据文件是稀疏格式的,所以取值为0的feature都不用写,这样文件不会太大。其余对经典SVD模型的改进就需要增加一些对应feature。他的代码中,每条记录是使用map存储feature的,可以随机存取任意一个feature的值(但是可能用链表就可以了?因为一般都是顺序访问的)。
FM可以用于多种预测问题,包括回归、分类和排序。对不同的预测问题,可以选择合适的loss term和regularization term。另外,FM的梯度也很容易求。