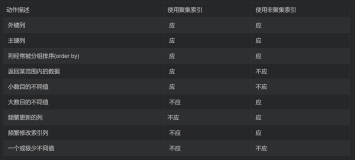
在探究awr第一篇中介绍了awr的一些基本操作 http://blog.itpub.net/23718752/viewspace-1123134/
在这一篇中,我们来分析几个awr报告来探究一下awr的一些信息,其实在报告中有很多的信息是可以互相印证的。对于我们深入理解awr报告还是很有帮助的。
首先来看看CPU负载的分析,这个也是理解awr的一个切入点。
CPU资源的考虑也是衡量系统系统的一个很好的标准,CPU的信息有基于系统级的,实例级的,通过awr报告的几个部分来互相印证。
在11g中,我们可以从报告的开头看到如下的一段。可以看到cpu core是40,总体的配置还不错。
来看看报告的“Host CPU”部分。这个部分是系统级的cpu使用信息。
报告中,系统级的cpu的消耗为: (用户级 14.9%+系统级3.9%+空闲部分80.2%)
所以busy%=100%-80.2%=19.8% 可见系统级的CPU使用率并不高。
我们再来看看实例级别的。可以从"Instance CPU"部分找到相关的部分。
这个部分的信息是在系统级别的基础上。本来系统级CPU的使用率在19.8%,在19.8%的基础上,实例级别的CPU消耗为16.2%,16.2/19.8=81.8% 和报告中%Busy CPU是基本吻合的。
在load profile中已经有所体现,这个可以从另外一个角度来印证。
DB CPU每秒平均为12.8,因为CPU有80个,所以CPU的使用情况为12.8/80=16%,和Instance CPU中的情况是吻合的。
报告中的" Operating System Statistics"也很重要。我们来通过这部分内容来印证Total CPU%为16%
这里BUSY_TIME+IDLE_TIME=
950,192+3,854,487=4804679毫秒,需要转为为秒。
另外Elapsed time也有很紧密的联系。
比如我们通过报告得到Elapsed time为10分钟(600秒). 那么BUSY_TIME+IDLE_TIME=4804s=Elapsed_time*CPU_COUNT=600秒*80=4800s
此外对于报告中的" Time Model Statistics"也是一个很重要的部分。
Total CPU= DB CPU+ background cpu time= 7,707.47+ 94.97=7802 s
如果想查看Total CPU的情况,就是实例级的使用情况/系统级的使用情况= (Total CPU)/(BUSY_TIME+IDEL_TIME)=7802/(4804679/1000)=16.2%
在这一篇中,我们来分析几个awr报告来探究一下awr的一些信息,其实在报告中有很多的信息是可以互相印证的。对于我们深入理解awr报告还是很有帮助的。
首先来看看CPU负载的分析,这个也是理解awr的一个切入点。
CPU资源的考虑也是衡量系统系统的一个很好的标准,CPU的信息有基于系统级的,实例级的,通过awr报告的几个部分来互相印证。
在11g中,我们可以从报告的开头看到如下的一段。可以看到cpu core是40,总体的配置还不错。
| Host Name | Platform | CPUs | Cores | Sockets | Memory (GB) |
|---|---|---|---|---|---|
| xxxx | Linux x86 64-bit | 80 | 40 | 4 | 346.22 |
来看看报告的“Host CPU”部分。这个部分是系统级的cpu使用信息。
Host CPU (CPUs: 80 Cores: 40 Sockets: 4)
| Load Average Begin | Load Average End | %User | %System | %WIO | %Idle |
|---|---|---|---|---|---|
| 71.07 | 60.81 | 14.9 | 3.9 | 0.1 | 80.2 |
报告中,系统级的cpu的消耗为: (用户级 14.9%+系统级3.9%+空闲部分80.2%)
所以busy%=100%-80.2%=19.8% 可见系统级的CPU使用率并不高。
我们再来看看实例级别的。可以从"Instance CPU"部分找到相关的部分。
Instance CPU
| %Total CPU | %Busy CPU | %DB time waiting for CPU (Resource Manager) |
|---|---|---|
| 16.2 | 82.1 | 0.0 |
在load profile中已经有所体现,这个可以从另外一个角度来印证。
Load Profile
| Per Second | Per Transaction | Per Exec | Per Call | |
|---|---|---|---|---|
| DB Time(s): | 79.0 | 0.9 | 0.01 | 0.01 |
| DB CPU(s): | 12.8 | 0.2 | 0.00 | 0.00 |
DB CPU每秒平均为12.8,因为CPU有80个,所以CPU的使用情况为12.8/80=16%,和Instance CPU中的情况是吻合的。
Instance CPU
| %Total CPU | %Busy CPU | %DB time waiting for CPU (Resource Manager) |
|---|---|---|
| 16.2 | 82.1 | 0.0 |
报告中的" Operating System Statistics"也很重要。我们来通过这部分内容来印证Total CPU%为16%
| Statistic | Value | End Value |
|---|---|---|
| BUSY_TIME | 950,192 | |
| IDLE_TIME | 3,854,487 | |
| IOWAIT_TIME | 7,195 | |
| NICE_TIME | 0 | |
| SYS_TIME | 185,332 | |
| USER_TIME | 714,673 | |
| LOAD | 71 | 61 |
| RSRC_MGR_CPU_WAIT_TIME | 0 | |
| VM_IN_BYTES | 118,528,572,416 | |
| VM_OUT_BYTES | 6,399,748,096 | |
| PHYSICAL_MEMORY_BYTES | 371,746,160,640 | |
| NUM_CPUS | 80 | |
| NUM_CPU_CORES | 40 | |
| NUM_CPU_SOCKETS | 4 | |
| GLOBAL_RECEIVE_SIZE_MAX | 134,217,728 | |
| GLOBAL_SEND_SIZE_MAX | 134,217,728 | |
| TCP_RECEIVE_SIZE_DEFAULT | 87,380 | |
| TCP_RECEIVE_SIZE_MAX | 134,217,728 | |
| TCP_RECEIVE_SIZE_MIN | 32,768 | |
| TCP_SEND_SIZE_DEFAULT | 87,380 | |
| TCP_SEND_SIZE_MAX | 134,217,728 | |
| TCP_SEND_SIZE_MIN | 32,768 |
另外Elapsed time也有很紧密的联系。
比如我们通过报告得到Elapsed time为10分钟(600秒). 那么BUSY_TIME+IDLE_TIME=4804s=Elapsed_time*CPU_COUNT=600秒*80=4800s
| Snap Id | Snap Time | Sessions | Cursors/Session | |
|---|---|---|---|---|
| Begin Snap: | 24741 | 23-Dec-14 09:00:37 | 5131 | 7.3 |
| End Snap: | 24742 | 23-Dec-14 09:10:39 | 5097 | 11.4 |
| Elapsed: | 10.02 (mins) | |||
| DB Time: | 792.19 (mins) |
此外对于报告中的" Time Model Statistics"也是一个很重要的部分。
| Statistic Name | Time (s) | % of DB Time |
|---|---|---|
| sql execute elapsed time | 44,362.14 | 93.33 |
| DB CPU | 7,707.47 | 16.22 |
| parse time elapsed | 3,107.67 | 6.54 |
| hard parse elapsed time | 1,894.13 | 3.99 |
| hard parse (sharing criteria) elapsed time | 774.55 | 1.63 |
| PL/SQL execution elapsed time | 69.29 | 0.15 |
| RMAN cpu time (backup/restore) | 12.60 | 0.03 |
| inbound PL/SQL rpc elapsed time | 8.00 | 0.02 |
| connection management call elapsed time | 7.77 | 0.02 |
| sequence load elapsed time | 1.88 | 0.00 |
| repeated bind elapsed time | 0.41 | 0.00 |
| failed parse elapsed time | 0.24 | 0.00 |
| hard parse (bind mismatch) elapsed time | 0.16 | 0.00 |
| PL/SQL compilation elapsed time | 0.03 | 0.00 |
| DB time | 47,531.51 | |
| background elapsed time | 1,139.42 | |
| background cpu time | 94.97 |
Total CPU= DB CPU+ background cpu time= 7,707.47+ 94.97=7802 s
如果想查看Total CPU的情况,就是实例级的使用情况/系统级的使用情况= (Total CPU)/(BUSY_TIME+IDEL_TIME)=7802/(4804679/1000)=16.2%