这种类似实时监控的语句,从第一印象来说,很可能通过awr捕获不到,如果通过ash来捕获,因为测试环境中有几十套测试环境在运行,就算得到某个时间点的一些sql语句,直接在报告中映射到语句对应的schema信息还是有一些困难的。因为测试时间确实很短,有很多的语句执行了,可能不一定被ash收集到。
我和他首先做了沟通,因为我压根不知道这是哪个应用的环境,所以先需要几分钟的时间来熟悉一下环境,提前准备一下。
数据库中存在大概50套测试环境,占用的session数大概在4000个左右。整体来看测试环境中的数据量都不大。每个环境都大概在10G-30G以内。
定位到制定的测试环境中,发现session占用情况也不高。都是一些常规的job使用,没有看到其它明显的session消耗,查看相关的锁信息,也没有发现什么问题。
简单确认之后,发现awr在这个时候是用不了了,最多使用下ash来看,除此之外,还可以使用脚本实时监控。
类似下面这样的操作。
> getash.sh
I SID SER# USERNAME OSUSER STA RPID SPID MACHINE PROGRAM ELAP_SEC TEMP_MB UNDO_MB SQL_ID TSPS SQL
-- ------ ------ ------------ ---------- --- ------- ------ ---------- -------------------- ----------- ------- ------- ------------- ------ -------------------------------------------------
1 19 16945 xxxx blwrk01 ACT 9442 9442 ccbdbprx oracle@xxxxxx 00 05:35:02 b9xg175fbzuk5 INSERT INTO xxxx (CYCLE_SEQ_NO, PAY
上面的语句也可以通过watch来指定频率看到每个用户下的信息实时变化情况。监控的过程中确实也能看到不少的信息变化,但是执行的时间确实很短,只能够抓取到一部分sql语句。简单分析了下,那些语句都没有发现有什么问题。
这个时候还是得靠开发协助,希望他们提示一些更细节的信息,这个业务场景要做的事情和一些指定的数据,他们提供说使用了某个表中资源号为 x271051128的数据,这个时候通过v$sql从缓存中就能够快速定位到语句,这个时候再和ash配合起来就能够确认是否是相关的用户在调用了。
最后抓取到了几条语句,和开发确认之后定位到一条语句,语句类似下面这样的形式。
select owner_id,
l3_balance_amount,
expiration_date,
customer_id,
c64_1,
l3_balance_Status,
sys_update_date,
sys_creation_Date
from accumulators
where customer_id in
(select customer_id
from subscriber
where prim_Resource_Val in ('x271051128'))
and owner_type = 'P'
通过抓取执行计划,发现subscriber表走了全表扫描。这个对应生产环境中的性能影响还是比较大的。
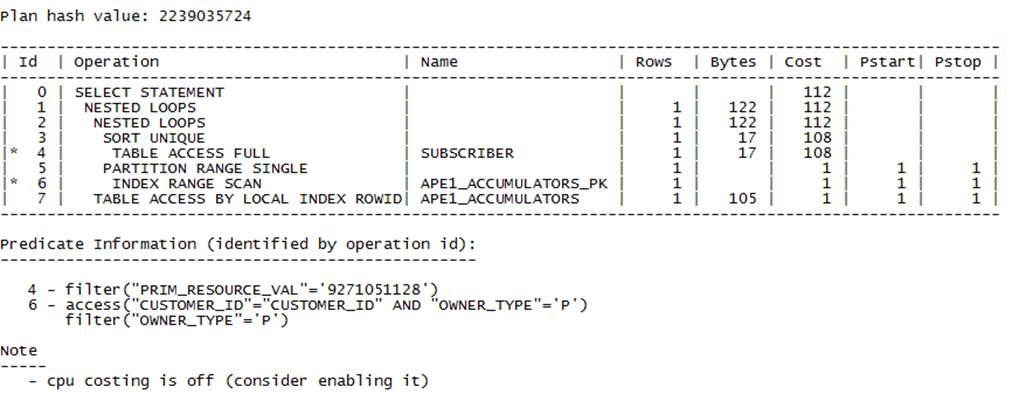
对于这个问题的调优,其实可以完全通过业务层面来优化,可以参考http://blog.itpub.net/23718752/viewspace-1312163/
问题是类似的,略有不同。我们可以引入一个更大的资源表,资源表agreement_resource和用户表subscriber,使用索引字段来关联,就避免了subscriber表的全表扫描。
调整后的语句如下:
select owner_id,
l3_balance_amount,
expiration_date,
customer_id,
c64_1,
l3_balance_Status,
sys_update_date,
sys_creation_Date
from ape1_accumulators
where customer_id in
(
select customer_id
from subscriber s
where (subscriber_no, PRIM_RESOURCE_TP) in
(select agreement_no, RESOURCE_TYPE
from agreement_resource r
where r.resource_value in ('x271051128'))
)
and owner_type = 'P'
通过调整后的执行计划可以看出,性能的提升还是很大的。这个是测试环境的数据,如果在数据量大的时候,优势就更加明显了。
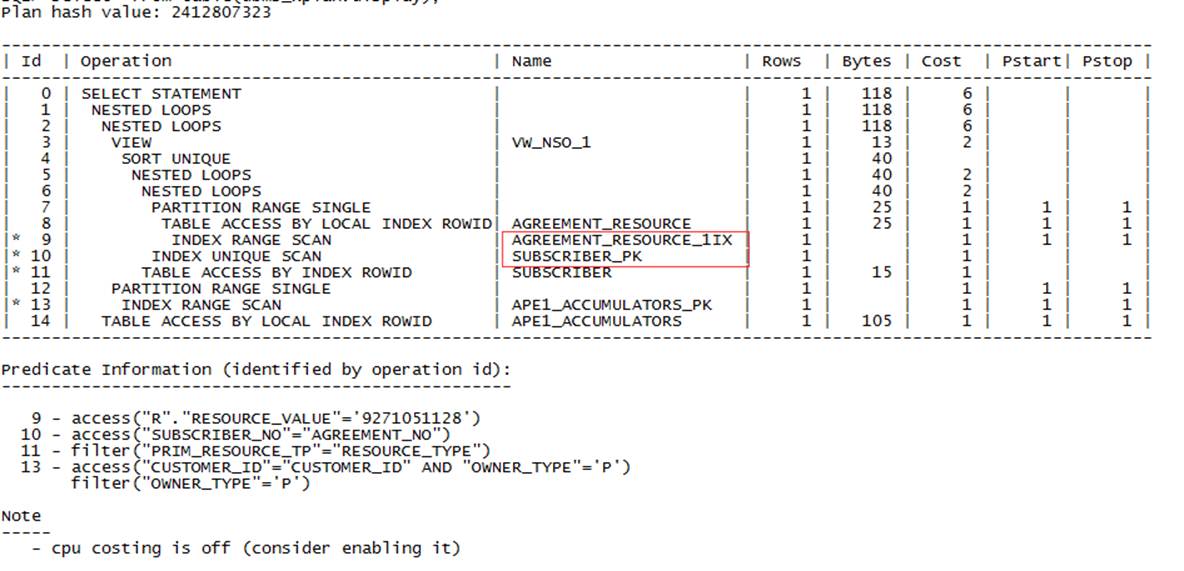
所以对于这个问题,起因是 有个job数据处理的 频率比较高,在测试环境中很难定位出在哪有问题 ,而且速度也还能接受, 但是在生产环境中总是会慢一些,其实深究起来还是有原因的,只能通过各种细节去诊断发现了。
