昨天刚到公司,开发的同事就找到我,让我帮他看看某一台mysql的库,似乎数据是不同步了。大体的意思是,A地库中的数据会同步到B地,B地的数据会同步到C地,C地就是开发最终需要访问的数据,这些业务都是独立的,但是一部分数据是需要同步的。听起来比较拗口,实现方式也比较有意思。
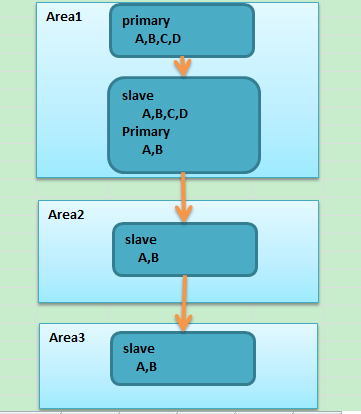
采用了下面的方式来实现。列出一部分的架构图。
图中的数据分布在三个区域,可以理解跨越了三个大洲,各个洲有自己的业务,也就是Area1,2,3,我们用区域ABC来替代。由于需要同步一部分数据到北京来。就是区域C通过区域B是作为中转的。因为区域A到区域C的网络带宽很差,需要代理中转,数据库都是使用了aws
这个图比较有意思的就是区域A中的备库,其实在这个架构中既是从库,同时又是区域B的主库。但是指同步一部分数据比如A,B
按照这样的结构图,目前发现是Area3中的数据没有同步过来,所以排查的思路也就很清晰了。
首先查看了Area1中的备库
mysql> select count(*) from fact_recharge;
+----------+
| count(*) |
+----------+
| 3295669 |
+----------+
1 row in set (6 min 10.75 sec)
但是在Area3中进行查询,发现差得倒不是很多。
> select count(*)from fact_recharge;
+----------+
| count(*) |
+----------+
| 3294066 |
+----------+
1 row in set (10.80 sec)
如果算作异地的同步,还说明不了问题所在。
继续登录到Area2进行排查。发现通过终端ssh连接很缓慢。
ssh: connect to host 46.1.22.90 port 22: Connection timed out
好不容易登录上去,赶紧抓取了一个top结果。
发现CPU都是空闲,负载非常低。
top - 18:47:27 up 108 days, 14:45, 2 users, load average: 0.05, 0.05, 0.00
Tasks: 539 total, 2 running, 537 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.3%us, 0.7%sy, 0.0%ni, 99.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 3932160k total, 3917400k used, 14760k free, 108268k buffers
Swap: 8393920k total, 2587788k used, 5806132k free, 580288k cached
这个时候通过本地的网络去连接缓慢,但是从top来看却显然不是系统负载高,因为用的是aws的服务,所以让运维的同学帮忙去看看。
过了一会,他们反馈,网络问题解决了。
这个时候连接Area2,发现速度就快多了。查看备库的状态,发现没有问题,于是继续排查问题,看看Area3的备库是否正常。
发现结果slave的状态是Reconnecting,这就意味着Area3备库还在尝试做同步,但是似乎还是没有奏效。
> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Reconnecting after a failed master event read
Master_Host: 46.1.22.90
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000311
Read_Master_Log_Pos: 598159165
Relay_Log_File: mysql-relay-bin.001428
Relay_Log_Pos: 61280882
Relay_Master_Log_File: binlog.000311
Slave_IO_Running: Connecting
Slave_SQL_Running: Yes
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 2003
Last_IO_Error: error reconnecting to master 'repl@46.1.22.90:3306' - retry-time: 60 retries: 86400
这个时候查看最近的IO_Error已经超时,反复尝试了多次了。
同时查看错误日志,发现一段内容,可见确实是出现了网络的问题。
151104 13:56:45 [ERROR] Slave I/O: error reconnecting to master 'repl@46.1.22.90:3306' - retry-time: 60 retries: 86400, Error_code: 2003
这个时候如果确认网络没有问题之后,可以尝试stop slave,start slave来重新开启数据应用
但是还是没有奏效。使用telnet也没有反应,还有报错。
telnet 46.1.22.90 3306
Trying 46.1.22.90...
telnet: connect to address 46.1.22.90: No route to host
telnet: Unable to connect to remote host: No route to host
如果使用ssh的22端口来处理,发现端口是通的。
# telnet 46.1.22.90 22
Trying 46.1.22.90...
Connected to wg_in_46.1.22.90 (46.1.22.90).
Escape character is '^]'.
SSH-2.0-OpenSSH_4.3
Protocol mismatch.
Connection closed by foreign host.
反复排查,最后发现Area2上的防火墙被开启了,过滤了一些访问。重新设置就好了。
所以早上的问题因为网络问题导致了数据的不同步,但是初步的网络问题解决了,不知道怎么的,又把防火墙设置进行了修改,导致Area3的备库压根连不到Area2,所以日志始终接收不了。
网络问题修复后,也不用设置stop slave,start slave,同步就开始自动更新了。
初始状态是
> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Queueing master event to the relay log
自动重连后,根据状态就发现确实开始应用数据日志了。
> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
当然同步之后,简单确认之后就可以告知研发,问题已经得到了解决。
这个问题虽然比较简单,但是作为MySQL新手还是需要好好了解一下开源中的数据复制实现方式与方法。这个问题的分析中根据业务的架构实现还是需要很熟练的掌握,这样在问题发生的时候才不至于太手忙脚乱。
采用了下面的方式来实现。列出一部分的架构图。
图中的数据分布在三个区域,可以理解跨越了三个大洲,各个洲有自己的业务,也就是Area1,2,3,我们用区域ABC来替代。由于需要同步一部分数据到北京来。就是区域C通过区域B是作为中转的。因为区域A到区域C的网络带宽很差,需要代理中转,数据库都是使用了aws
这个图比较有意思的就是区域A中的备库,其实在这个架构中既是从库,同时又是区域B的主库。但是指同步一部分数据比如A,B
按照这样的结构图,目前发现是Area3中的数据没有同步过来,所以排查的思路也就很清晰了。
首先查看了Area1中的备库
mysql> select count(*) from fact_recharge;
+----------+
| count(*) |
+----------+
| 3295669 |
+----------+
1 row in set (6 min 10.75 sec)
但是在Area3中进行查询,发现差得倒不是很多。
> select count(*)from fact_recharge;
+----------+
| count(*) |
+----------+
| 3294066 |
+----------+
1 row in set (10.80 sec)
如果算作异地的同步,还说明不了问题所在。
继续登录到Area2进行排查。发现通过终端ssh连接很缓慢。
ssh: connect to host 46.1.22.90 port 22: Connection timed out
好不容易登录上去,赶紧抓取了一个top结果。
发现CPU都是空闲,负载非常低。
top - 18:47:27 up 108 days, 14:45, 2 users, load average: 0.05, 0.05, 0.00
Tasks: 539 total, 2 running, 537 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.3%us, 0.7%sy, 0.0%ni, 99.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 3932160k total, 3917400k used, 14760k free, 108268k buffers
Swap: 8393920k total, 2587788k used, 5806132k free, 580288k cached
这个时候通过本地的网络去连接缓慢,但是从top来看却显然不是系统负载高,因为用的是aws的服务,所以让运维的同学帮忙去看看。
过了一会,他们反馈,网络问题解决了。
这个时候连接Area2,发现速度就快多了。查看备库的状态,发现没有问题,于是继续排查问题,看看Area3的备库是否正常。
发现结果slave的状态是Reconnecting,这就意味着Area3备库还在尝试做同步,但是似乎还是没有奏效。
> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Reconnecting after a failed master event read
Master_Host: 46.1.22.90
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000311
Read_Master_Log_Pos: 598159165
Relay_Log_File: mysql-relay-bin.001428
Relay_Log_Pos: 61280882
Relay_Master_Log_File: binlog.000311
Slave_IO_Running: Connecting
Slave_SQL_Running: Yes
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 2003
Last_IO_Error: error reconnecting to master 'repl@46.1.22.90:3306' - retry-time: 60 retries: 86400
这个时候查看最近的IO_Error已经超时,反复尝试了多次了。
同时查看错误日志,发现一段内容,可见确实是出现了网络的问题。
151104 13:56:45 [ERROR] Slave I/O: error reconnecting to master 'repl@46.1.22.90:3306' - retry-time: 60 retries: 86400, Error_code: 2003
这个时候如果确认网络没有问题之后,可以尝试stop slave,start slave来重新开启数据应用
但是还是没有奏效。使用telnet也没有反应,还有报错。
telnet 46.1.22.90 3306
Trying 46.1.22.90...
telnet: connect to address 46.1.22.90: No route to host
telnet: Unable to connect to remote host: No route to host
如果使用ssh的22端口来处理,发现端口是通的。
# telnet 46.1.22.90 22
Trying 46.1.22.90...
Connected to wg_in_46.1.22.90 (46.1.22.90).
Escape character is '^]'.
SSH-2.0-OpenSSH_4.3
Protocol mismatch.
Connection closed by foreign host.
反复排查,最后发现Area2上的防火墙被开启了,过滤了一些访问。重新设置就好了。
所以早上的问题因为网络问题导致了数据的不同步,但是初步的网络问题解决了,不知道怎么的,又把防火墙设置进行了修改,导致Area3的备库压根连不到Area2,所以日志始终接收不了。
网络问题修复后,也不用设置stop slave,start slave,同步就开始自动更新了。
初始状态是
> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Queueing master event to the relay log
自动重连后,根据状态就发现确实开始应用数据日志了。
> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
当然同步之后,简单确认之后就可以告知研发,问题已经得到了解决。
这个问题虽然比较简单,但是作为MySQL新手还是需要好好了解一下开源中的数据复制实现方式与方法。这个问题的分析中根据业务的架构实现还是需要很熟练的掌握,这样在问题发生的时候才不至于太手忙脚乱。