昨天在睡觉前接到了一条报警短信,本来已经疲倦的身轻如燕,但是看到报警,还是警觉了起来
Filesystem Size Used Avail Use% Mounted on
/dev/sda8 243G 103G 129G 45% /home
/dev/sdb 1.7T 1.6T 29G 99% /U01
对于这个问题,自己为了火速进行处理,就从/U01下面开始找文件进行清理,首要就是找归档文件,但是失望的是发现归档文件现在确实也不多了。而且目前的归档删除策略也是半个小时删除一次。截止到问题发生的时候,归档文件只有4个,而且也是半个小时内生成的,就算删除了也腾不出多少空间,更关键的是还需要到备库去查看是否归档已经接受。所以简单确认之后从主库删除了已经被备库应用的归档,省下来1个G多一点的空间,问题暂时解决了,就开始从其他目录查看是否还有更多的空间清理,但是发现除了一些历史的日志,其实可清理的空间也就不到1G.
所以这个时候问题很可能再次发生,需要马上进行处理。
从目前的情况来看/U01下的空间确实屈指可数,改进空间已经不大了。那么还有一个分区就是/home大概还有几百个G还能勉强应付一下。
这个时候一种方法就是把归档路径直接切换到/home分区下,但是这种变更很快会导致dg broker报警,为了减少给监控同学更多的解释和对系统本身的影响,我决定下临时把归档目录切过去。
比如今天是12月27日,就在/home/下生成一个软链接,比如我现在给自己几天的buffer时间,这部分的100多G的空间就先在这个目录下刷新,不会有太大的抖动。
[oracle@tlbb3dbidb arch]$ ll
lrwxrwxrwx 1 oracle oinstall 71 Dec 27 01:17 2015_12_27 -> /U01/app/oracle/oradata/test/archive/TEST/archivelog/2015_12_27
lrwxrwxrwx 1 oracle oinstall 71 Dec 27 01:21 2015_12_28 -> /U01/app/oracle/oradata/test/archive/TEST/archivelog/2015_12_28
lrwxrwxrwx 1 oracle oinstall 71 Dec 27 01:22 2015_12_29 -> /U01/app/oracle/oradata/test/archive/TEST/archivelog/2015_12_29
lrwxrwxrwx 1 oracle oinstall 71 Dec 27 01:22 2015_12_30 -> /U01/app/oracle/oradata/test/archive/TEST/archivelog/2015_12_30
当然这个问题为什么没有早点发现,其实很早就发现了,但是对于这个统计库的空间问题,阀值设置为90~95%,但是老是报警,而且又没有更多的空间就搁置下来了。所以先这样处理,自己也好协调跟进。
当然回过头来,这么多空间都消耗在哪里了。可以从下面的图形看出,其实最近的归档切换频率在凌晨会有一个小高峰,应该是批量的数据处理。之后基本趋于稳定。
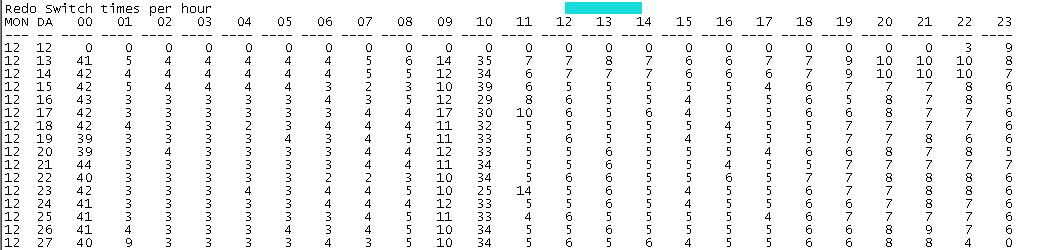
所以对于这个问题的更深一层的分析,就是如果空间的消耗在逐渐增大,那么这个空间的消耗瓶颈在哪里。
其实想得到这个结果,也是分分钟就会有结果。直接从dba_segments里面查找即可。可以看到下面的几个表的空间占用极高。
segment_name segment_type bytes_MB
LOGIN_LOG TABLE PARTITION 103331
M_START_LOG TABLE PARTITION 117842
MOL_TIME INDEX PARTITION 120922
M_ONLINE_LOG TABLE PARTITION 809661
这个M_ONLINE_LOG竟然占用了近800多个G,作为一个分区表而言数据量也着实惊人。
那么这部分数据是不是历史数据太多了呢,发现数据量也是在逐渐递增,而且都是近半年的数据。没有之前的历史数据了。
分区从4月份开始的数据增长情况如下:
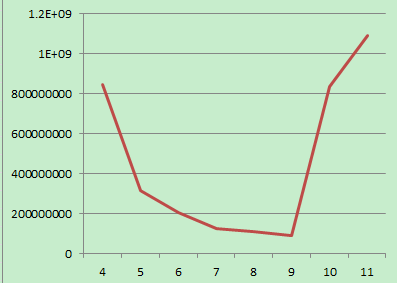
看来最近的数据增长情况还在不断递增,所以这个问题还是有很多的确认之处,是否需要这么多的数据,如果确实需要,需要进一步考虑挂载新的分区,如果只是需要部分的数据,那么就需要考虑一个持久的数据清理方案。夜深了,看看手机,应很晚了。工作是干不完的,睡觉睡觉。
ZABBIX-监控系统:
------------------------------------
报警内容: DG_issue
------------------------------------
报警级别: PROBLEM
------------------------------------
监控项目: dg_issue:2015-12-27 00:35:17.0Log Transport ServicesErrorARC0: Encountered disk I/O error 195022015-12-27 00:35:17.0Log Transport ServicesErrorARC0: I/O error 19502 archiving log 1 to '/U01/app/oracle/oradata/test/archive/TEST/archivelog/2015_12_27/o1_mf_1_71969_c7xjg564_.arc'
------------------------------------
报警时间:2015.12.27-00:35:22
Filesystem Size Used Avail Use% Mounted on
/dev/sda8 243G 103G 129G 45% /home
/dev/sdb 1.7T 1.6T 29G 99% /U01
对于这个问题,自己为了火速进行处理,就从/U01下面开始找文件进行清理,首要就是找归档文件,但是失望的是发现归档文件现在确实也不多了。而且目前的归档删除策略也是半个小时删除一次。截止到问题发生的时候,归档文件只有4个,而且也是半个小时内生成的,就算删除了也腾不出多少空间,更关键的是还需要到备库去查看是否归档已经接受。所以简单确认之后从主库删除了已经被备库应用的归档,省下来1个G多一点的空间,问题暂时解决了,就开始从其他目录查看是否还有更多的空间清理,但是发现除了一些历史的日志,其实可清理的空间也就不到1G.
所以这个时候问题很可能再次发生,需要马上进行处理。
从目前的情况来看/U01下的空间确实屈指可数,改进空间已经不大了。那么还有一个分区就是/home大概还有几百个G还能勉强应付一下。
这个时候一种方法就是把归档路径直接切换到/home分区下,但是这种变更很快会导致dg broker报警,为了减少给监控同学更多的解释和对系统本身的影响,我决定下临时把归档目录切过去。
比如今天是12月27日,就在/home/下生成一个软链接,比如我现在给自己几天的buffer时间,这部分的100多G的空间就先在这个目录下刷新,不会有太大的抖动。
[oracle@tlbb3dbidb arch]$ ll
lrwxrwxrwx 1 oracle oinstall 71 Dec 27 01:17 2015_12_27 -> /U01/app/oracle/oradata/test/archive/TEST/archivelog/2015_12_27
lrwxrwxrwx 1 oracle oinstall 71 Dec 27 01:21 2015_12_28 -> /U01/app/oracle/oradata/test/archive/TEST/archivelog/2015_12_28
lrwxrwxrwx 1 oracle oinstall 71 Dec 27 01:22 2015_12_29 -> /U01/app/oracle/oradata/test/archive/TEST/archivelog/2015_12_29
lrwxrwxrwx 1 oracle oinstall 71 Dec 27 01:22 2015_12_30 -> /U01/app/oracle/oradata/test/archive/TEST/archivelog/2015_12_30
当然这个问题为什么没有早点发现,其实很早就发现了,但是对于这个统计库的空间问题,阀值设置为90~95%,但是老是报警,而且又没有更多的空间就搁置下来了。所以先这样处理,自己也好协调跟进。
当然回过头来,这么多空间都消耗在哪里了。可以从下面的图形看出,其实最近的归档切换频率在凌晨会有一个小高峰,应该是批量的数据处理。之后基本趋于稳定。
所以对于这个问题的更深一层的分析,就是如果空间的消耗在逐渐增大,那么这个空间的消耗瓶颈在哪里。
其实想得到这个结果,也是分分钟就会有结果。直接从dba_segments里面查找即可。可以看到下面的几个表的空间占用极高。
segment_name segment_type bytes_MB
LOGIN_LOG TABLE PARTITION 103331
M_START_LOG TABLE PARTITION 117842
MOL_TIME INDEX PARTITION 120922
M_ONLINE_LOG TABLE PARTITION 809661
这个M_ONLINE_LOG竟然占用了近800多个G,作为一个分区表而言数据量也着实惊人。
那么这部分数据是不是历史数据太多了呢,发现数据量也是在逐渐递增,而且都是近半年的数据。没有之前的历史数据了。
分区从4月份开始的数据增长情况如下:
看来最近的数据增长情况还在不断递增,所以这个问题还是有很多的确认之处,是否需要这么多的数据,如果确实需要,需要进一步考虑挂载新的分区,如果只是需要部分的数据,那么就需要考虑一个持久的数据清理方案。夜深了,看看手机,应很晚了。工作是干不完的,睡觉睡觉。



