前几天碰到一个CPU负载较高的问题。从系统层面来看,情况不是很严重,但是从应用的角度来说,已经感觉到很慢了。因为前端的调用频率还是比较高。所以会把这个问题放大。
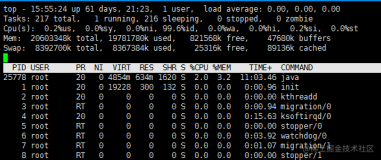
使用top -c查看了基本的服务器信息。可以看到负载大概在30%左右。IO wait不高。
top - 19:30:48 up 179 days, 4:54, 3 users, load average: 4.43, 4.28, 4.14
Tasks: 669 total, 6 running, 661 sleeping, 0 stopped, 2 zombie
Cpu(s): 24.1%us, 3.4%sy, 0.0%ni, 69.0%id, 0.0%wa, 0.0%hi, 3.4%si, 0.0%st
Mem: 32949016k total, 32835380k used, 113636k free, 292028k buffers
Swap: 16771776k total, 4563936k used, 12207840k free, 25528396k cached
而首当其冲的几个进程都是CPU利用率100%
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9014 oracle 18 0 16.1g 1.1g 1.1g R 100.0 3.5 13:01.09 oraclexxx (LOCAL=NO)
9024 oracle 16 0 16.1g 1.5g 1.5g R 100.0 4.8 36:31.23 oraclexxx (LOCAL=NO)
9100 oracle 17 0 16.1g 1.1g 1.1g R 100.0 3.4 8:34.87 oraclexxx (LOCAL=NO)
22975 root 15 0 13164 1568 812 R 100.0 0.0 0:00.04 top -c
看看这几个进程在干嘛?发现都在执行相同的sql语句。
$sh showpid.sh 9014
SQL_ID SQL_TEXT
------------------------------ ------------------------------------------------------------
5h92pf9xtbps4 UPDATE SWD_DRAWCN SET WEAPONLISTNO=:1,IP=:2, ROLE_NAME=:3, G
ROUP_ID=:4, SERVER_IP=:5, SERVER_NAME=:6, ROLE_GUID=:7, ROLE
_LEVEL=:8, DRAWED='Y',DRAWDATE=sysdate,SN_GET=:9 WHERE ID=:1
0 AND CN=LOWER(:11) AND DRAW_TYPE=:12
PREV_SQL_ID SQL_TEXT
------------------------------ ------------------------------------------------------------
5h92pf9xtbps4 UPDATE SWD_DRAWCN SET WEAPONLISTNO=:1,IP=:2, ROLE_NAME=:3, G
ROUP_ID=:4, SERVER_IP=:5, SERVER_NAME=:6, ROLE_GUID=:7, ROLE
_LEVEL=:8, DRAWED='Y',DRAWDATE=sysdate,SN_GET=:9 WHERE ID=:1
0 AND CN=LOWER(:11) AND DRAW_TYPE=:12
所以看起来很有可能是sql语句导致的问题。从最近的快照里面的sql对应的db time使用情况可以看出,5h92pf9xtbps4竟然有三行内容。这个当然是从awr报告里面直接看不到的。
$ sh showsnapsql.sh 105206
Current Instance
~~~~~~~~~~~~~~~~
DBID DB_NAME INST_NUM INST_NAME
---------- --------- ---------- ----------------
1720209052 XXX 1 xxx
SNAP_ID SQL_ID EXECUTIONS_DELTA ELAPSED_TI PER_TOTAL
---------- ------------- ---------------- ---------- ----------
105206 5h92pf9xtbps4 6783 6863s 96%
105206 5h92pf9xtbps4 0 6863s 96%
105206 5h92pf9xtbps4 47032 6863s 96%
所以初步感觉是执行计划发生了变化,如果从这个思路来看,这个问题似乎也能说得通了,为什么之前没有问题,现在有问题了。
我们来看看awr报告里面怎么说。
当然这个语句可以看出这个语句还是有些问题。可以用coe的脚本看出,这个语句存在3个不同的执行计划,而且执行计划之间的差别看起来差别不是很大,但是在调用频繁的系统中,这个影响就会被放大。
SQL_ID: 5h92pf9xtbps4
PLAN_HASH_VALUE AVG_ET_SECS
--------------- -----------
2762405514 .037
889840933 .103
3278101387 .194
从awrsqrpt里面得到一些更具体的信息,可以看到第一个执行计划较好的语句在1个小时内执行次数近1万多次。而第二条执行频率高了很多10万多次,但是执行时间要低很多。第三个执行计划执行次数为0.
所以针对这种情况,我把注意力放在了前两个执行计划上。 来看看语句的索引情况,对应的表有两个索引,一个字段建立在draw_type上,另外一个建立在类似id的字段CN上。这个表中的数据有1千万左右。
PLAN hash value为 3278101387的执行计划为:
而PLAN hash value为
2762405514的执行计划为:
看两个执行计划,貌似差别也不大。但是这种细微的差别的影响就导致了执行时间近40倍的差别。
为什么之前有问题,现在没有,如果查看以前的执行情况,是肯定走了CN的索引,而现在出现问题是走了TYPE的索引。
为什么执行计划发生了一些改变,还是和统计信息的情况和统计信息收集的一些规则有关。
那么这个问题基本已经有了方向,怎么修复呢。主要有两种思路,一种是重新收集统计信息,尽可能创建符合索引CN,TYPE, 第二种思路就是修改执行计划,让语句执行目前最优的执行计划,这个时候,sqlprofile就派上大的用处了。
打开coe脚本,把原来的outline部分修改为下面的形式
h := SYS.SQLPROF_ATTR(
q'[BEGIN_OUTLINE_DATA]',
q'[IGNORE_OPTIM_EMBEDDED_HINTS]',
q'[OPTIMIZER_FEATURES_ENABLE('10.2.0.4')]',
q'[OPT_PARAM('optimizer_index_cost_adj' 30)]',
q'[OPT_PARAM('optimizer_index_caching' 90)]',
q'[ALL_ROWS]',
q'[OUTLINE_LEAF(@"UPD$1")]',
q'[INDEX_RS_ASC(@"UPD$1" "SWD_DRAWCN"@"UPD$1" ("SWD_DRAWCN"."CN"))]',
q'[END_OUTLINE_DATA]');
然后替换,回车以后马上查看top情况,发现问题马上缓解了下来,
等了几分钟,可以看到确实cpu利用率降下来了。当然这种情况处理完之后,从业务的反馈已经正常了。
但是对于这个问题目前的方案还是一个临时解决,还是需要持续改进。
使用top -c查看了基本的服务器信息。可以看到负载大概在30%左右。IO wait不高。
top - 19:30:48 up 179 days, 4:54, 3 users, load average: 4.43, 4.28, 4.14
Tasks: 669 total, 6 running, 661 sleeping, 0 stopped, 2 zombie
Cpu(s): 24.1%us, 3.4%sy, 0.0%ni, 69.0%id, 0.0%wa, 0.0%hi, 3.4%si, 0.0%st
Mem: 32949016k total, 32835380k used, 113636k free, 292028k buffers
Swap: 16771776k total, 4563936k used, 12207840k free, 25528396k cached
而首当其冲的几个进程都是CPU利用率100%
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9014 oracle 18 0 16.1g 1.1g 1.1g R 100.0 3.5 13:01.09 oraclexxx (LOCAL=NO)
9024 oracle 16 0 16.1g 1.5g 1.5g R 100.0 4.8 36:31.23 oraclexxx (LOCAL=NO)
9100 oracle 17 0 16.1g 1.1g 1.1g R 100.0 3.4 8:34.87 oraclexxx (LOCAL=NO)
22975 root 15 0 13164 1568 812 R 100.0 0.0 0:00.04 top -c
看看这几个进程在干嘛?发现都在执行相同的sql语句。
$sh showpid.sh 9014
SQL_ID SQL_TEXT
------------------------------ ------------------------------------------------------------
5h92pf9xtbps4 UPDATE SWD_DRAWCN SET WEAPONLISTNO=:1,IP=:2, ROLE_NAME=:3, G
ROUP_ID=:4, SERVER_IP=:5, SERVER_NAME=:6, ROLE_GUID=:7, ROLE
_LEVEL=:8, DRAWED='Y',DRAWDATE=sysdate,SN_GET=:9 WHERE ID=:1
0 AND CN=LOWER(:11) AND DRAW_TYPE=:12
PREV_SQL_ID SQL_TEXT
------------------------------ ------------------------------------------------------------
5h92pf9xtbps4 UPDATE SWD_DRAWCN SET WEAPONLISTNO=:1,IP=:2, ROLE_NAME=:3, G
ROUP_ID=:4, SERVER_IP=:5, SERVER_NAME=:6, ROLE_GUID=:7, ROLE
_LEVEL=:8, DRAWED='Y',DRAWDATE=sysdate,SN_GET=:9 WHERE ID=:1
0 AND CN=LOWER(:11) AND DRAW_TYPE=:12
所以看起来很有可能是sql语句导致的问题。从最近的快照里面的sql对应的db time使用情况可以看出,5h92pf9xtbps4竟然有三行内容。这个当然是从awr报告里面直接看不到的。
$ sh showsnapsql.sh 105206
Current Instance
~~~~~~~~~~~~~~~~
DBID DB_NAME INST_NUM INST_NAME
---------- --------- ---------- ----------------
1720209052 XXX 1 xxx
SNAP_ID SQL_ID EXECUTIONS_DELTA ELAPSED_TI PER_TOTAL
---------- ------------- ---------------- ---------- ----------
105206 5h92pf9xtbps4 6783 6863s 96%
105206 5h92pf9xtbps4 0 6863s 96%
105206 5h92pf9xtbps4 47032 6863s 96%
所以初步感觉是执行计划发生了变化,如果从这个思路来看,这个问题似乎也能说得通了,为什么之前没有问题,现在有问题了。
我们来看看awr报告里面怎么说。
| Elapsed Time (s) | CPU Time (s) | Executions | Elap per Exec (s) | % Total DB Time | SQL Id | SQL Module | SQL Text |
|---|---|---|---|---|---|---|---|
| 12,605 | 12,605 | 113,557 | 0.11 | 96.90 | 5h92pf9xtbps4 | xxxtest@BJ-YF-4-166 (TNS V1-V3) | UPDATE SWD_DRAWCN SET WEAPONLI... |
SQL_ID: 5h92pf9xtbps4
PLAN_HASH_VALUE AVG_ET_SECS
--------------- -----------
2762405514 .037
889840933 .103
3278101387 .194
从awrsqrpt里面得到一些更具体的信息,可以看到第一个执行计划较好的语句在1个小时内执行次数近1万多次。而第二条执行频率高了很多10万多次,但是执行时间要低很多。第三个执行计划执行次数为0.
| # | Plan Hash Value | Total Elapsed Time(ms) | Executions | 1st Capture Snap ID | Last Capture Snap ID |
|---|---|---|---|---|---|
| 1 | 3278101387 | 12,227,848 | 12,610 | 105205 | 105206 |
| 2 | 2762405514 | 377,370 | 100,947 | 105205 | 105206 |
| 3 | 889840933 | 0 | 0 | 105205 | 105206 |
PLAN hash value为 3278101387的执行计划为:
| Id | Operation | Name | Rows | Bytes | Cost (%CPU) | Time |
|---|---|---|---|---|---|---|
| 0 | UPDATE STATEMENT | 62 (100) | ||||
| 1 | UPDATE | SWD_DRAWCN | ||||
| 2 | TABLE ACCESS BY INDEX ROWID | SWD_DRAWCN | 1 | 111 | 62 (0) | 00:00:01 |
| 3 | INDEX RANGE SCAN | IND_DRAWCN_TYPE | 8465 | 9 (0) | 00:00:01 |
| Id | Operation | Name | Rows | Bytes | Cost (%CPU) | Time |
|---|---|---|---|---|---|---|
| 0 | UPDATE STATEMENT | 48 (100) | ||||
| 1 | UPDATE | SWD_DRAWCN | ||||
| 2 | TABLE ACCESS BY INDEX ROWID | SWD_DRAWCN | 1 | 123 | 48 (0) | 00:00:01 |
| 3 | INDEX RANGE SCAN | IND_SWD_DRAWCN_CN | 891 | 2 (0) | 00:00:01 |
为什么之前有问题,现在没有,如果查看以前的执行情况,是肯定走了CN的索引,而现在出现问题是走了TYPE的索引。
为什么执行计划发生了一些改变,还是和统计信息的情况和统计信息收集的一些规则有关。
那么这个问题基本已经有了方向,怎么修复呢。主要有两种思路,一种是重新收集统计信息,尽可能创建符合索引CN,TYPE, 第二种思路就是修改执行计划,让语句执行目前最优的执行计划,这个时候,sqlprofile就派上大的用处了。
打开coe脚本,把原来的outline部分修改为下面的形式
h := SYS.SQLPROF_ATTR(
q'[BEGIN_OUTLINE_DATA]',
q'[IGNORE_OPTIM_EMBEDDED_HINTS]',
q'[OPTIMIZER_FEATURES_ENABLE('10.2.0.4')]',
q'[OPT_PARAM('optimizer_index_cost_adj' 30)]',
q'[OPT_PARAM('optimizer_index_caching' 90)]',
q'[ALL_ROWS]',
q'[OUTLINE_LEAF(@"UPD$1")]',
q'[INDEX_RS_ASC(@"UPD$1" "SWD_DRAWCN"@"UPD$1" ("SWD_DRAWCN"."CN"))]',
q'[END_OUTLINE_DATA]');
然后替换,回车以后马上查看top情况,发现问题马上缓解了下来,
等了几分钟,可以看到确实cpu利用率降下来了。当然这种情况处理完之后,从业务的反馈已经正常了。
但是对于这个问题目前的方案还是一个临时解决,还是需要持续改进。