在我的印象中,一直以来都会收到一封报警邮件,之前分析过,排查过,最后发现是一个遗留问题,协调开发同学,停业务维护还是有一些难度,最后不了了之了,在今天又突然想起了这件事情,觉得还是需要做点什么。
报警邮件类似下面的形式: ZABBIX-监控系统:
------------------------------------
报警内容: Disk I/O is overloaded on 10.127.2.134_xx机房_xxxx
------------------------------------
报警级别: PROBLEM
------------------------------------
监控项目: CPU iowait time:17.21 %
------------------------------------
报警时间:2016.09.26-04:05:33
这是一台备库11gR2的环境,在ADG模式下的数据变化也会单独采样,这一点非常难得。所以很看到备库的DB time情况,可以明显看到在早间的时候有很大的抖动。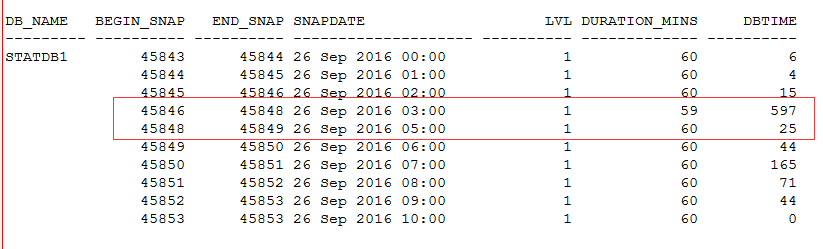
而基于快照,定位到具体的语句情况下,可见SQL_ID(4rhpc838qfsmy)就是我们要攻坚的重点了。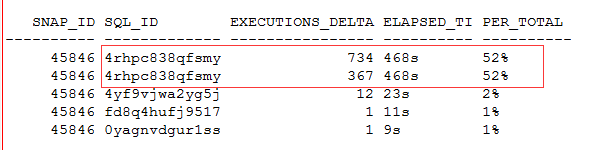
这是什么样的一个语句呢,让我很感意外。语句竟然看起来很简单,而且看起来竟然有两个执行计划。
$ sh showsqltext.sh 4rhpc838qfsmy
select * from (select user_ip,end_time from bill_logout_cn where cn=:1 order by end_time desc) where rownum=1
而且仔细看语句还是有一点优化的味道。 这样一个语句怎么性能会很差呢。
通过awrsqrpt得到的结果如下: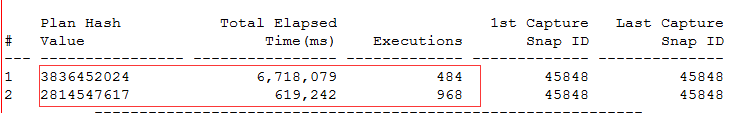
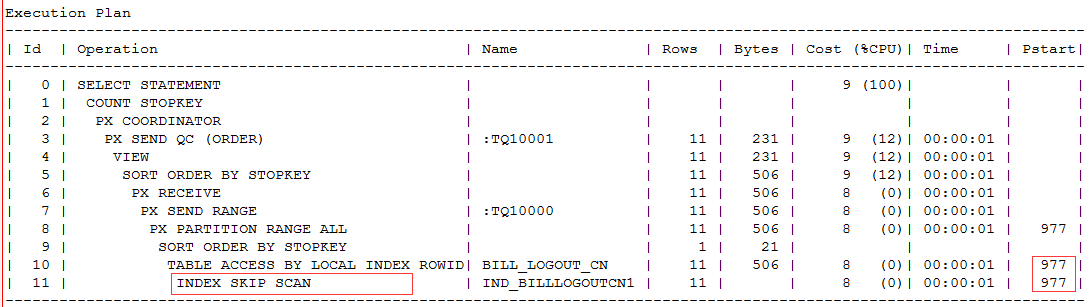
对这样一个语句,存在两个执行计划,就很奇怪了。
第一个执行计划虽然是索引扫描,但是I/O等待很高。
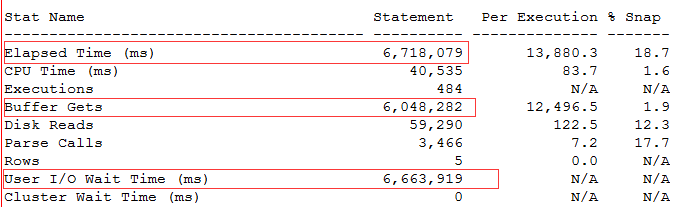
Plan 2(PHV: 2814547617)
-----------------------
第二个执行计划产生了大量的buffer gets,使用了全表扫描。
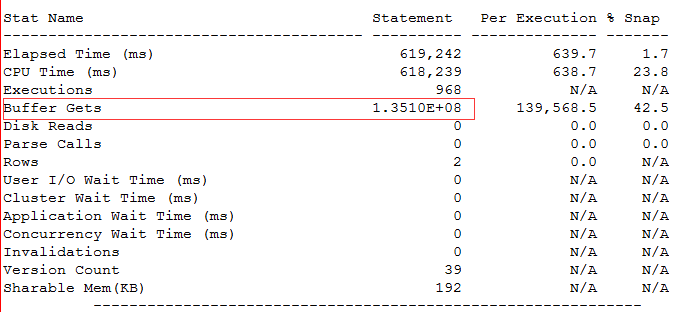
这是一个什么类型的表呢,数据量有2亿多,CN字段存在一个非唯一性索引。
执行计划如下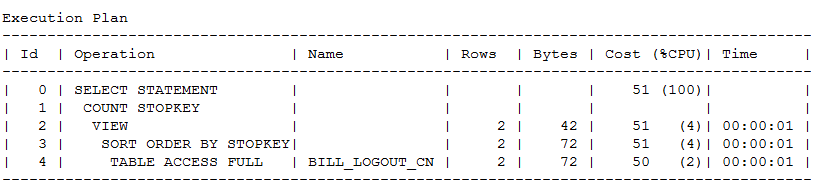
这个语句一个是使用了index skip scan,瓶颈在于扫描了大量的分区,结果大量的IO等待都在于此。
而第二个执行计划索性走了全表扫描,可见还是在运行中根据CBO评估而得全表的代价要相对低一些。
对于这个问题有几个疑问,首先这个语句性能如此之差,为什么在主库没有报警而在备库呢,其实原因是这样,主库的配置信息要好很多,这些问题和负载在主库都不是问题,以至于这个问题的影响在主库被弱化了。
而为什么语句走索引全扫描,全表扫描呢。这个其实说来话长,我查看了表的结构信息发现,这个表存在大量的分区,每天会生成一个分区,结果在2014年的某一天开始突然就停止了分区的维护,结果导致分区数据现在全都堆积在了默认分区上,这样就会性能一个很奇怪的数据分布,绝大多数的数据都分布在一个分区上,而还有很多历史数据分布在更多以日期为单位的分区上。
如果了解了问题的原委,其实也可以理解数据库在处理这个问题时的艰辛。
而对于这个问题的改进,就是需要重构分区,摆在我面前的由几件事情。首先是需要和开发确认是否历史数据可以清理,这个经过讨论,大家都带着保守态度;第二个问题是分区的维护,需要添加最近的一些分区,这个是否可以给出维护时间,不过经过讨论,在了解了业务特征之后,其实也可以做一个折中,那就是使用在线重定义来完成,尽管这是一个亿级数据的大表,但是因为是统计系统,所以数据更新很少,而且基本都是在凌晨胡统一更新,其他时段主要是查询为主,这样来看这个问题使用在线重定义其实还蛮不错的,互相成就,也不用互相协调区停业务应用了。
第二个问题解决之后第一个问题就好办了,可以在确认之后再具体部署。
好了,来到了重点的内容,那就是亿级大表的在线重定义,虽然之前做了周密的测试,但是还是有一些期待和小紧张。
和开发同学约定了下午的时间来在线维护,留给我的时间也不到一个小时了,要生成近900多个额外的分区,这个工作量着实不小,我采用了如下的SQL来动态生成需要补充的分区。
select 'PARTITION BILL_LOGOUT_CN_'||to_char((trunc(sysdate)-990+level),'yyyymmdd')||' VALUES LESS THAN (TO_DATE('||chr(39)||(trunc(sysdate)-990+level+1)||chr(39)||', '||chr(39)||'YYYY-MM-DD HH24:MI:SS'||chr(39)||')) '
||'TABLESPACE ACCSTAT_DATA ,' from dual connect by level<990;
生成的语句类似下面的形式:
PARTITION BILL_LOGOUT_CN_20160924 VALUES LESS THAN (TO_DATE('2016-09-25 00:00:00', 'YYYY-MM-DD HH24:MI:SS')) TABLESPACE ACCSTAT_DATA ,
。。。
我创建了一个新表BILL_LOGOUT_CN_DEF来和BILL_LOGOUT_CN最后做数据字典信息的交换。
在线重定义的前几步都是套路,因为没有主键,所以我使用rowid的方式。
exec DBMS_REDEFINITION.CAN_REDEF_TABLE('TEST','BILL_LOGOUT_CN',2);
exec DBMS_REDEFINITION.START_REDEF_TABLE('TEST','BILL_LOGOUT_CN','BILL_LOGOUT_CN_DEF',NULL,2);
第二步运行之后,后台就开始忙碌起来了。
可以看到有会话在运行这样的语句。
SQL_FULLTEXT
----------------------------------------------------------------------------------------------------
INSERT /*+ BYPASS_RECURSIVE_CHECK APPEND SKIP_UNQ_UNUSABLE_IDX */ INTO "TEST"."BILL_LOGOUT_CN_DEF"(M_ROW$$,"CN",XXXX) SELECT XXXX FROM "TEST"."BILL_LOGOUT_CN" "BILL_LOGOUT_CN"
而查看物化视图相关的数据字典,可以赫然看到有一个prebuilt物化视图,采用快速刷新的方式。![]()
而在数据刷新之后,可以看到后台对于rowid的方式采用了下面的处理方式,即创建一个唯一性索引
SQL_FULLTEXT
----------------------------------------------------------------------------------------------------
CREATE UNIQUE INDEX "TEST"."I_SNAP$_BILL_LOGOUT_CN_DEF" ON "TEST"."BILL_LOGOUT_CN_DEF" ("M_ROW$$")
PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
TABLESPACE "TEST_DATA"
而这个索引也在不断增大。
SEGMENT_NAME SIZE_M BLOCKS
------------------------------ --------- ----------
I_SNAP$_BILL_LOGOUT_CN_DEF 8065 1032320
---------
sum 8065
好了,有的同学可能会说,在线重定义了解那么多干嘛,够用就行了。
没过多久,就看到数据复制的过程抛错了。
SQL> exec DBMS_REDEFINITION.START_REDEF_TABLE('TEST','BILL_LOGOUT_CN','BILL_LOGOUT_CN_DEF',NULL,2);
BEGIN DBMS_REDEFINITION.START_REDEF_TABLE('TEST','BILL_LOGOUT_CN','BILL_LOGOUT_CN_DEF',NULL,2); END;
*
ERROR at line 1:
ORA-14010: this physical attribute may not be specified for an index partition
ORA-06512: at "SYS.DBMS_REDEFINITION", line 56
ORA-06512: at "SYS.DBMS_REDEFINITION", line 1490
ORA-06512: at line 1
这个问题如果查看metalink,博客可能还没有很针对性的解答,这个就需要对在线重定义的过程很熟悉。
简单分析发现就是在表空间上出了问题。
重新分配扩展空间之后,再次开启重定义,会抛出下面的错误。
SQL> exec DBMS_REDEFINITION.START_REDEF_TABLE('TEST','BILL_LOGOUT_CN','BILL_LOGOUT_CN_DEF',NULL,2);
BEGIN DBMS_REDEFINITION.START_REDEF_TABLE('TEST','BILL_LOGOUT_CN','BILL_LOGOUT_CN_DEF',NULL,2); END;
*
ERROR at line 1:
ORA-23539: table "TEST"."BILL_LOGOUT_CN" currently being redefined
ORA-06512: at "SYS.DBMS_REDEFINITION", line 56
ORA-06512: at "SYS.DBMS_REDEFINITION", line 1490
ORA-06512: at line 1
为了加快处理过程,我们也可以手工处理一部分
删除对应的物化视图和物化视图日志
SQL> drop materialized view test.BILL_LOGOUT_CN_DEF;
Materialized view dropped.
SQL> drop materialized view log on test.BILL_LOGOUT_CN;
Materialized view log dropped.
看来这个过程可以完全证明在线重定义是使用物化视图快速刷新的。
来终止一下重定义过程,重新来过。其实这个步骤就在做truncate的操作。
execute dbms_redefinition.ABORT_REDEF_TABLE ('TEST','BILL_LOGOUT_CN','BILL_LOGOUT_CN_DEF');
重新开始数据复制,重定义。
SQL> exec DBMS_REDEFINITION.CAN_REDEF_TABLE('TEST','BILL_LOGOUT_CN',2);
SQL>exec DBMS_REDEFINITION.START_REDEF_TABLE('TEST','BILL_LOGOUT_CN','BILL_LOGOUT_CN_DEF',NULL,2);
这一次就顺利多了,一次搞定。
最后完成前可以再手工刷新一下增量数据,保持数据的gap尽可能小。
SQL> execute dbms_redefinition.sync_interim_table ('TEST','BILL_LOGOUT_CN','BILL_LOGOUT_CN_DEF');
PL/SQL procedure successfully completed.
最后交换数据字典信息即可完成。
SQL> exec DBMS_REDEFINITION.FINISH_REDEF_TABLE('TEST','BILL_LOGOUT_CN','BILL_LOGOUT_CN_DEF');
PL/SQL procedure successfully completed.
Elapsed: 00:00:39.82
解决了之个问题之后,后续还有一些小的地方需要注意,补充新的分区,持续观察性能改进,历史分区数据的清理等。