今天本来是处理一个简单的故障,但是发现是一环套一环,花了我快一天的时间。
开始是早上收到一条报警:
报警内容: CPUutilization is too high
------------------------------------
报警级别: PROBLEM
------------------------------------
监控项目: CPU idle time:59.94 %
------------------------------------
报警时间:2017.01.06-06:35:22开始也没有在意,准备花几分钟处理完事,但是发现这个坑越来越大。对于问题的处理,我觉得还是能够刨坑问底,你能说服自己,弄明白了,碰到类似的问题就会得心应手。
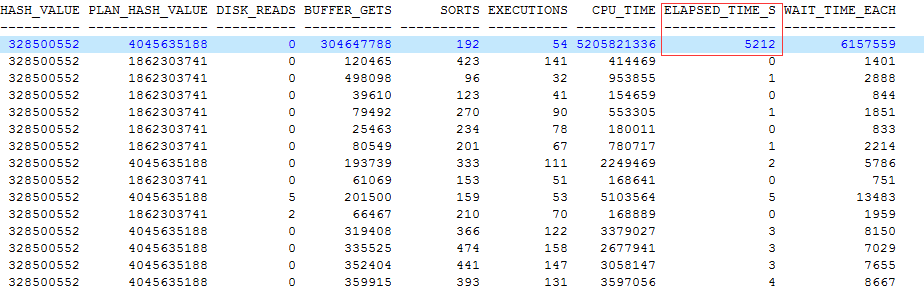
我发现数据库的负载有了较大的提升,查看快照级别的DB time负载如下:
BEGIN_SNAP END_SNAP SNAPDATE DURATION_MINS DBTIME
---------- ---------- --------------------------------- ----------
19028 19029 06 Jan 2017 00:00 60 104
19029 19030 06 Jan 2017 01:00 60 233
19030 19031 06 Jan 2017 02:00 60 331
19031 19032 06 Jan 2017 03:00 60 409
19032 19033 06 Jan 2017 04:00 60 465
19033 19034 06 Jan 2017 05:00 60 513
19034 19035 06 Jan 2017 06:00 60 538
19035 19036 06 Jan 2017 07:00 59 591
19036 19037 06 Jan 2017 08:00 60 614
19037 19038 06 Jan 2017 09:00 60 622
19038 19039 06 Jan 2017 10:00 60 665
这个情况不容乐观,很快就定位到是一个SQL语句引起的。
可以看到语句的执行计划发生了改变,本来执行2秒的语句,现在执行近5000多秒。这个差距实在是有些大了。
语句的结构如下:
merge into xxxx using
(
select xxxx from h1_first_dev d, ua_td_active_log a
where d.dt = to_date(:1, 'yyyy-mm-dd')
and a.dt = :2
and d.deviceid is not null
and (d.deviceid = a.idfa or d.deviceid = a.mac or
a.idfa =lower(utl_raw.cast_to_raw(dbms_obfuscation_toolkit.md5(input_string => d.deviceid))))
...
union
select xxxx from h1_first_dev d, ua_td_active_log a
where d.dt = to_date(:1, 'yyyy-mm-dd')
and a.dt = :2
and d.deviceid is not null
and (d.deviceid = a.idfa or d.deviceid = a.mac or
and (a.idfa =lower(utl_raw.cast_to_raw(dbms_obfuscation_toolkit.md5(input_string => nvl(case when instr(d.deviceid, ':') > 0 then replace(substr(substr(d.deviceid, 19, 15), 1, 15), chr(2), '') else replace(substr(d.deviceid, 1, 15), chr(2), '') end, 'null')))))
....
)
on(xxxx) when matched xxx
看起来语句结构也蛮复杂,而且调用了几个大家平时很少见到的包,这个时候就有两个问题需要解释清楚。
-
之前为什么没有这个问题
-
问题的解决方法是什么
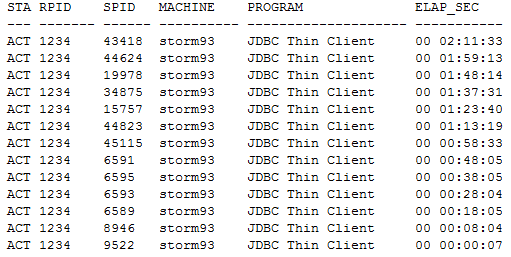
查看数据库层面的活跃会话情况,可以看到有大量的会话被阻塞了,而且看阻塞的频率,语句大概是10分钟执行一次。
我对比了变化前后的执行计划情况。
一个重要的变化是两个执行计划的表关联方式不同,左边的效率较差,使用了Nested Loop Join,右边的部分效率较高,使用了Hash Join
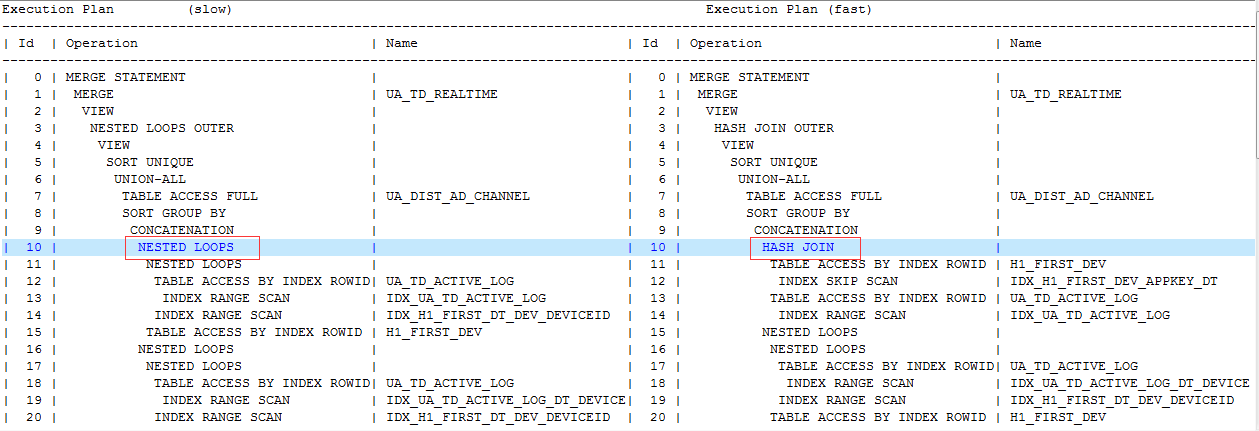
当然语句的执行计划很长,我点到为止,重点是如果单单是表关联方式发生变化,这个肯定说明不了Nested Loop Join比Hash Join要好。
简单总结了一下索引的扫描方式,也有了不同的结果。
IDX_H1_FIRST_DT_DEV_DEVICEID(Nested Loop Join) 使用了index range scan
IDX_H1_FIRST_DEV_APPKEY_DT(Hash Join) 使用了 index skip scan
不过这个地方我排查了直方图等信息,没有发现异常,对于NL Join和Hash Join,我可以简单通过如下的数据来论证。
SQL> select count(*)from mbi.h1_first_dev where dt between sysdate-1 and sysdate;
COUNT(*)
----------
3330
所以说这种的情况下,NL Join是完全没有问题的,支持绰绰有余。
那么这个问题我们怎么分析呢,我们分而治之。里面有几个子查询,我们可以拆开来看。
在子查询的执行计划中,我竟然看到了“MERGE JOIN CARTESIAN”的字样。
哪里来的笛卡尔积?
我拿出一个子查询来解释。
select xxxx from h1_first_dev d, ua_td_active_log a
where d.dt = to_date(:1, 'yyyy-mm-dd')
and a.dt = :2
and d.deviceid is not null
and (d.deviceid = a.idfa or d.deviceid = a.mac or
a.idfa =lower(utl_raw.cast_to_raw(dbms_obfuscation_toolkit.md5(input_string => d.deviceid))))
绑定变量值都是日期相关的。
Name Position Type Value
:1 1 VARCHAR2(32) 2017-01-06
:2 2 VARCHAR2(32) 2017-01-06
:3 3 VARCHAR2(32) 2017-01-06
:4 4 VARCHAR2(32) 2017-01-06
可以看出h1_first_dev的字段dt是日期型,ua_td_active_log的dt是字符型。
在这种情况下就是两个结果集的运算了。
本来根据时间条件,可以从两个表里各筛取出很小的一部分数据。

但是两个表的字段类型又不相同,一个date型,一个varchar2,而且没有映射关系,最要命的是后面的条件and (d.deviceid = a.idfa or d.deviceid = a.mac or ... 最后两个表的关联关系被这个条件给彻底破坏了。
所以如此一来,原本3000条左右的数据的关联,硬是给映射成了4千万数据的关联(表里的数据有4千万),想想就是心塞。
我用下面的一个图来表达我的这种心情吧。

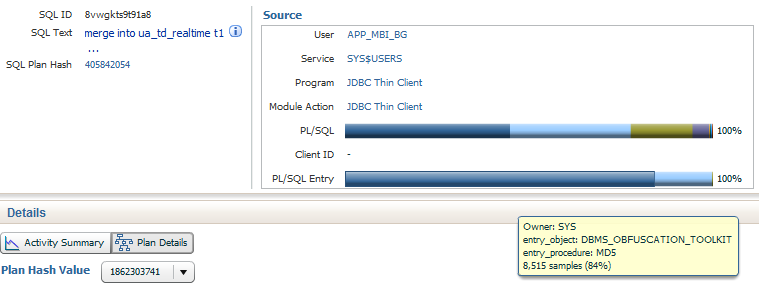
而且里面竟然还用到了几个比较少见的包dbms_obfuscation_toolkit utl_raw 导致CPU解析非常繁忙。
查看SQL Monitor报告,基本都被PL/SQL的包给攻占了。
所以这个问题解决起来其实还是要花一些功夫的。我对比模拟测试了一下。取得增量数据,然后运行同样的SQL
SQL> create table H1_FIRST_DEV as select * from mbi.H1_FIRST_DEV where dt=to_date('2017-01-06','yyyy-mm-dd');
SQL> create table UA_TD_ACTIVE_LOG as select * from mbi.UA_TD_ACTIVE_LOG where dt='2017-01-06';
没有任何索引,也没有收集统计信息,同样的语句消耗在1秒内。
SQL> @sqltune1.sql
no rows selected
Elapsed: 00:00:00.60
而更为奇怪的是返回竟然是0行。
这个时候回头来看开始性能较差的执行计划统计信息,就能理解了。
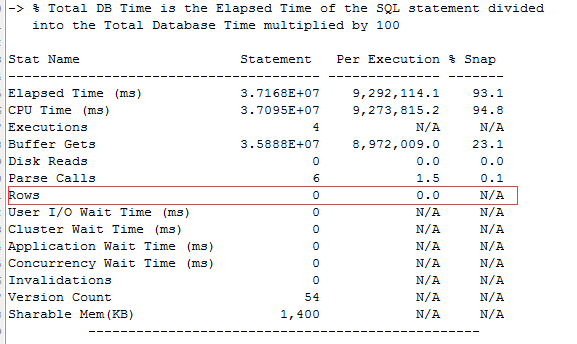
所以这个问题的解决方案可以稳定执行计划,让dt的过滤优先。或者是重新修改SQL语句,把一些逻辑做精简和改进,比如PL/SQL调用的包体可以通过数据过滤来处理,毕竟是很小的一部分数据。
当然和开发的同学沟通后,我发现问题还没想象的那么简单,因为还有几个更有挑战的SQL要优化,下一篇来谈谈怎么把一个平均执行20秒的核心SQL优化为2秒,关联的表都是千万级别。
