之前也列举了几期的MySQL死锁问题,光有操作演练,还缺少一些自己的分析,所以我就打算补充一下。
首先对于死锁问题,我们分析的背景是基于MySQL事务隔离级别为RR,存储引擎为InnoDB,在MySQL 5.6,5.7版本均可复现问题。
怎么来分析一个死锁问题呢,我一直在琢磨这个问题,自己也总结了不少出现的场景,但是感觉还是有一些欠缺或者不完善的地方。那么我们就换一个思路来分析死锁问题,通过日志来反推死锁产生的可能场景,然后依次深入,扩展,这样一来,这个问题的分析就带有通过很多不确定性分析判断,得到确定性的结果,然后分析和预期一致,这个问题就算基本搞明白了。
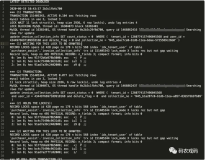
所以在此我不给出表结构,只给出死锁的日志来。这样一段日志,是在MySQL设置了死锁检测,输出日志的参数后得到的。
通过一段死锁日志来挖掘一些有价值的信息。
整个死锁的日志分为了两个事务,Transaction 1和Transaction 2,这里需要指出的是,这其实是发生死锁的临界状态的事务信息,就好似一个印章。我们看到的是最后得到的一个状态信息(类似盖上印章的一瞬间),而完整的过程是没法通过日志体现出来的,还有一个,如果仔细看上面的日志就会发现,事务1的日志还是不够完整,持有的锁,等待的锁,只打印出了等待的锁,有很多业内朋友是通过修改内核代码来把这个信息补充完整的。
但是发生死锁的时候是有两个事务互相阻塞,循环形成死锁,我们就依次来分析两个事务的日志信息。
事务1的日志信息如下,我们可以看到整个事务持续(阻塞)了46秒钟,很快就会达到触发超时的阈值,涉及的表有1个(tables in use 1),有2个锁(一个表级意向锁,一个行锁)语句为: delete from dtest1 where num=10,,加锁的对象是索引num,这个唯一的行锁处于等待状态(WAITING FOR THIS LOCK TO BE GRANTED),相关的锁等待为(lock_mode X waiting,next key锁)。
*** (1) TRANSACTION:
TRANSACTION 2844, ACTIVE 46 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s)
MySQL thread id 5, OS thread handle 140582228653824, query id 55 localhost root updating
delete from dtest1 where num=10
2017-09-11T10:07:08.103195Z 6 [Note] InnoDB: *** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 34 page no 4 n bits 72 index num of table `test`.`dtest1` trx id 2844 lock_mode X waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
0: len 4; hex 8000000a; asc ;;
1: len 4; hex 8000000a; asc ;;
再来看看第二个事务,内容略长一些。可以看到分为两部分内容,一部分是持有的锁(HOLDS THE LOCK),锁模式为(lock_mode X locks rec but not gap,no gap lock),另一部分是等待的锁,锁模式为(lock mode S waiting)
2017-09-11T10:07:08.103243Z 6 [Note] InnoDB: *** (2) TRANSACTION:
TRANSACTION 2843, ACTIVE 92 sec inserting
mysql tables in use 1, locked 1
4 lock struct(s), heap size 1136, 3 row lock(s), undo log entries 2
MySQL thread id 6, OS thread handle 140582228387584, query id 58 localhost root update
insert into dtest1 values(11,10)
2017-09-11T10:07:08.103260Z 6 [Note] InnoDB: *** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 34 page no 4 n bits 72 index num of table `test`.`dtest1` trx id 2843 lock_mode X locks rec but not gap
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
0: len 4; hex 8000000a; asc ;;
1: len 4; hex 8000000a; asc ;;
2017-09-11T10:07:08.103301Z 6 [Note] InnoDB: *** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 34 page no 4 n bits 72 index num of table `test`.`dtest1` trx id 2843 lock mode S waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 32
0: len 4; hex 8000000a; asc ;;
1: len 4; hex 8000000a; asc ;;
2017-09-11T10:07:08.103348Z 6 [Note] InnoDB: *** WE ROLL BACK TRANSACTION (1)
大体我们得到了这样的信息,一个事务等待的行锁模式为next key lock,另外一个事务持有record lock,等待的锁为S锁,出现S锁看来是一个突破口,我们就需要明白为什么会是S锁,事务2中相关的SQL是insert语句,如果需要进行唯一性冲突检查的时候,是需要先加一个S锁,所以由此我们可以进一步推理出这个Num对应的索引是一个唯一性索引。
由此我们可以进一步分析,何时得到这个S锁,肯定是在另外一个事务(也可能是其他的事务,比一定是事务1)中会去触发,在事务2中才会持有一个S锁,所以这样一来insert之前是有一个事务在做一个和唯一性索引相关的操作,我们理一下。
事务1相关的SQL:
delete from dtest1 where num=10
事务2相关的SQL:
insert into dtest1 values(11,10)
根据持有的S锁我们可以猜测可能是在事务2之前有一个DML操作阻塞了唯一性索引,我们假设为insert或者delete操作(限定下范围),进一步限定是两个会话中的事务,下面的分析就很重要了。
事务2中的持有的S锁,我们可以从下往上去推理,事务1上面肯定是一个delete操作,也就是日志中的第一部分显示,是一个delete操作。
按照这个方向往下去想,整个死锁的场景应该是下面这样的。
事务2:
insert/delete操作待分析
事务1:
delete from dtest1 where num=10;
事务2:
insert into dtest1 values(11,10);
如果在事务2中先做的是一个insert操作,显然在事务2中会直接抛出duplicate的报错,所以此处在insert,delete中只能是delete的操作,
所以整个死锁的过程真实的情况就是:
事务2:
delete from dtest1 where num=10; --record lock
事务1:
delete from dtest1 where num=10; --申请X锁,进入锁请求队列
事务2:
insert into dtest1 values(11,10); --申请S锁,产生了循环等待。
这个过程也是抛砖引玉,希望大家提出更多的想法。建表语句为:
create table dtest1 (id int primary key,num int unique);