
之前画过一版MHA的故障图,最近和同事做了系统详细的测试,发现了一些问题,有些是预料之外的场景,有些是目前MHA没有更好的保证和实现,斟酌再三做了取舍。
因为有些场景是组合出现的,比如网络波动,ssh不可达,但是已有的应用连接正常,那么这种情况就需要一些更全面的校验机制。所以MHA的测试如果简单那还是比较简单清晰的,如果想深入测试就需要考虑很多细节,保证技术完全可控。
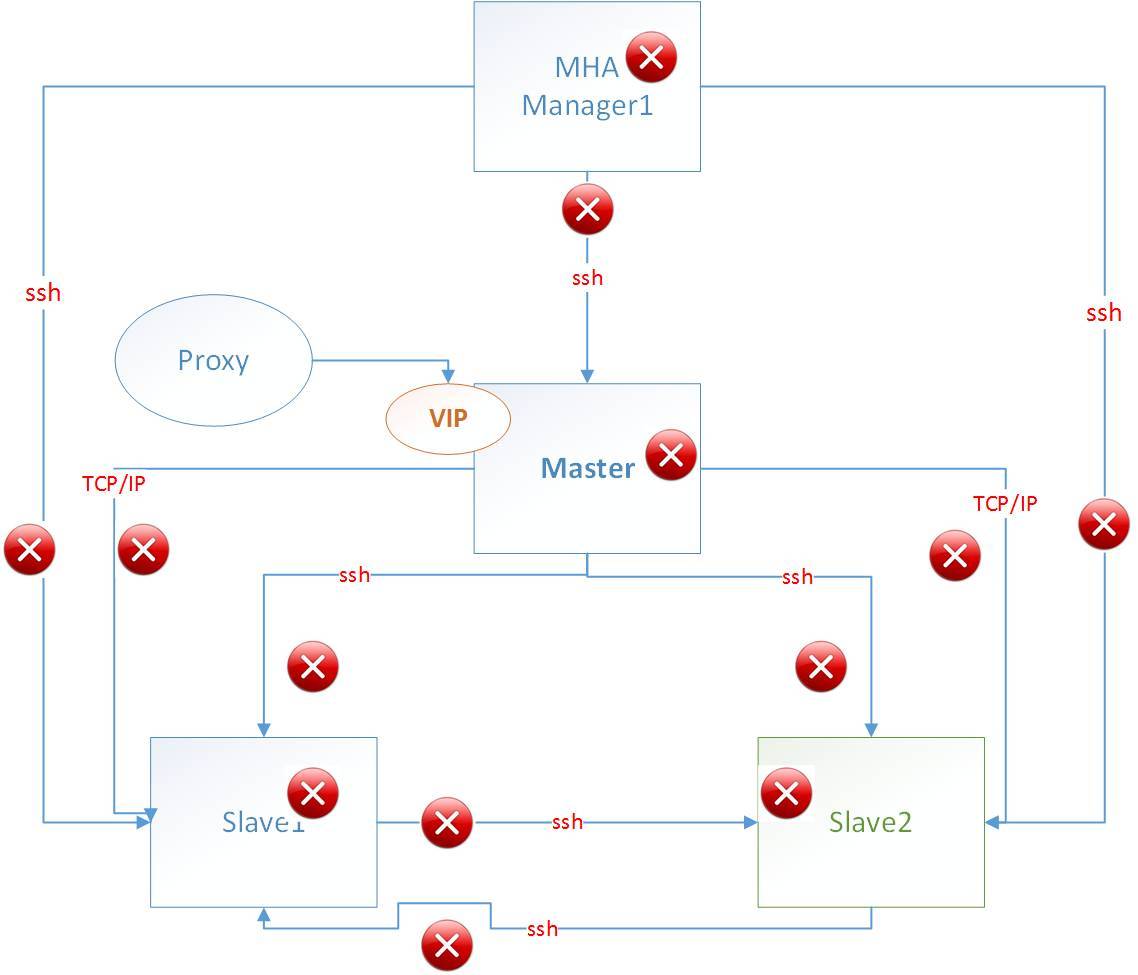
对于MHA的部分,因为要接入的是大量的环境,如何在大批量的环境中能够管理自如,就需要对已有的MHA做一些功能定制,自成一个体系。这种情况很可能出现,本来运行一套环境是OK的,但是再加入几套环境,原来的逻辑和方式就得全部改造,改造的同时还需要保证已有的逻辑不会出现意外。这个是尤其需要注意的。
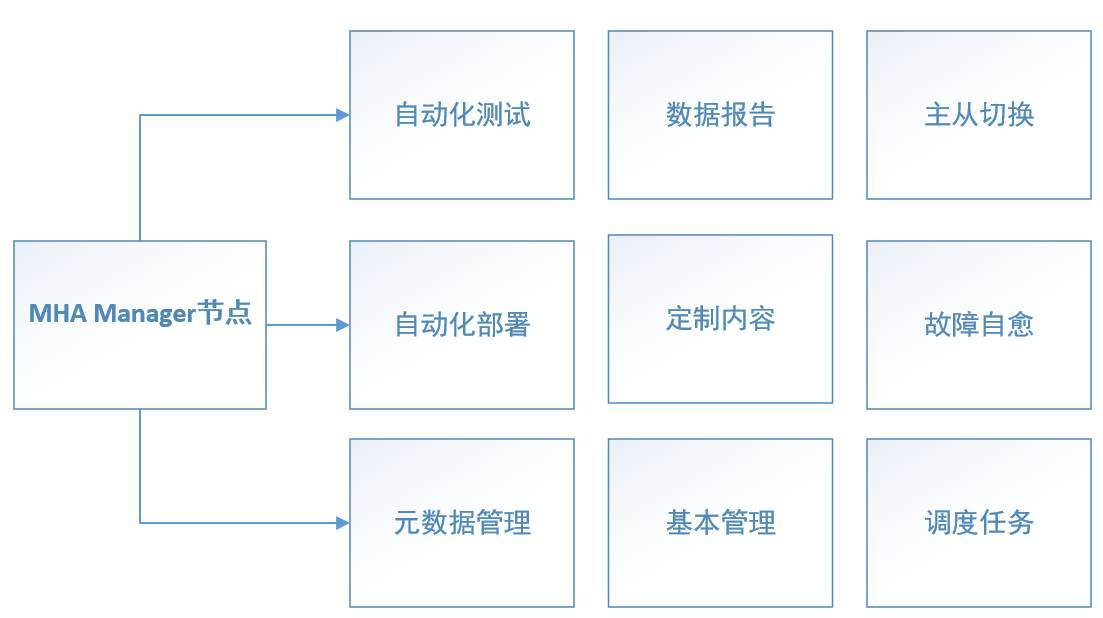
具体该怎么做呢,我们做了一些基本的规划,现在正在按照这个方向来逐步完善。
自动化部署
根据配置文件生成节点信任关系
根据配置文件生成部署脚本
根据切换情况更新部署脚本
根据切换情况更新dblist
主从切换
switchover脚本化
MHA管理
查看主从延迟
查看节点通信情况
MHA集群检测
启动MHA的检查脚本sanity_check.sh
启动MHA
停止MHA
元数据管理
配置dblist
主从复制关系
同步推送信息到mis里面的元数据库
MHA_Report
failover_report
网络延迟报告
MHA参数定制
定制超时时间,默认为4秒,改为10秒
修改ssh端口为定制端口,默认为22
修改日志的格式,根据需求来定制内容
后续考虑secondary_check的补充场景
调度任务
日志截断
周期行发送状态报告
自动化测试
测试场景和配置
自动化脚本
故障自愈
在已有的基础上做一些更动态的处理。




