“当遇到一个文本处理问题时,如果你在第一时间想到了正则表达式,那么恭喜你,你的问题从一个变成了俩!“
如果你曾参与过文本数据分析,正则表达式(Regex)对你来说一定不陌生。词库索引、关键词替换……正则表达式的强大功能使其成为了文本处理的必备工具。然而, 在处理大文本的情境下,正则表达式的低效率却常常让人抓耳挠腮。今天,文摘菌将为你介绍一款比正则表达式快数百倍的Python库——FlashText。
让人抓狂的数据清洗工作
即便是最简单的文本分析,我们在进入正式分析之前也需要对文本作出数据清洗。清洗的工作往往涉及到搜索和替换关键词。例如,查询文本中是否出现““Python”这一关键词,或是将所有“python“都替换成”“Python”。如果仅有数百个被搜索和被替换的关键词,正则表达式处理起来会很快。但在自然语言处理任务中,有数万关键词的语料库和数百万的文档早已是家常便饭。这种情况下,运行正则表达式的时间就往往要以“天“来作计数单位了。

吓哭了的文摘菌
当然了,你会觉得并行运算能够解决这一问题,但实际上这一方案却收效甚微。有没有其他办法呢?
FlashText的创造者当年也面临了同样的问题,在经过了一番搜寻而无所获后,他决定自己来编写一个新算法。
在了解FlashText的实现原理之前,让我们先来看看FlashText和正则表达式在搜索任务中的性能对比图。
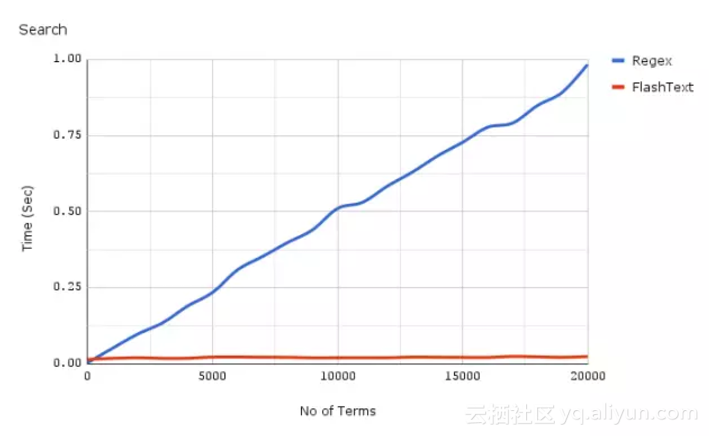
我们可以看到,当关键词数量上升时,Regex所花费的时间几乎呈线性增长,然而FlashText却几乎没受什么影响。

开心的文摘菌
再来看一张执行词语替换任务的对比图
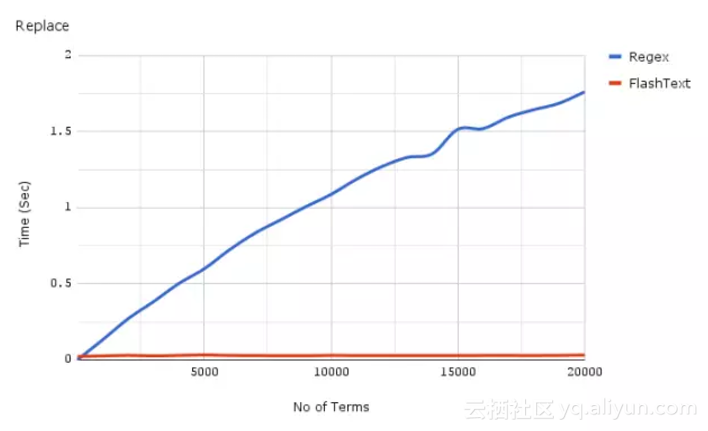
同样的,在词语数量增加时,FlashText的运行时间却几乎不受影响。
所以,什么是FlashText呢?
FlashText是GitHub上的一个开源Python库,正如之前所提到的,它在提取关键字和替换关键字任务上有着极高的性能。
在使用FlashText时,你首先要给它一个关键词列表。这份列表将用于在内部建立一个单词查找树的字典(Trie dictionary)。然后你将一个字符串传递给它,并告诉它是要执行替换还是搜索。
对于替换,它将用替换关键字创建一个新字符串。对于搜索,它将返回字符串中找到的关键字列表。这些任务都只需要遍历字符串一遍。
FlashText为什么这么快?
举个例子吧。我们有一个句子,它由三个单词组成——I like Python,并且假设我们有一个四个单词组成的语料库{Python, Java, J2ee, Ruby}。
如果我们从语料库中拿出每个单词,并且检查它是否出现在句子中,这需要我们遍历字符串四次。

如果语料库里有n个词,它将需要n个循环。并且每个搜索步骤(is <word> in sentence?)将花费自己的时间,这就是正则匹配(Regex match)的机制。
还有与第一种方法相反的另一种方法L对于句子中的每个单词,检查它是否存在于语料库中。

如果这个句子有m个词,它就有m个循环。在这种情况下,所花费的时间只取决于句子中的单词数。这个步骤( is <word> in corpus? )可以使用字典查找快速创建。
FlashText算法是基于第二种方法的,该灵感来自于Aho-Corasick算法和单词查找树数据结构(Trie data structure)。
它的工作方式是:
首先根据语料库创建一个单词查找树字典(Trie data structure)。如下图:
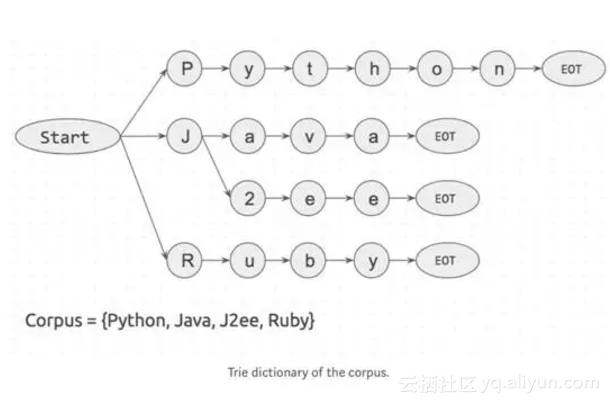
start和EOT(End Of Term)表示单词边界,可以是空格,句号或换行符。关键字只有在它的两边有单词边界时才能被匹配。这样可以防止apple和pineapple的匹配。
接下来,我们将输入一个字符串I like Python,并且一个字符一个字符搜索他、它。

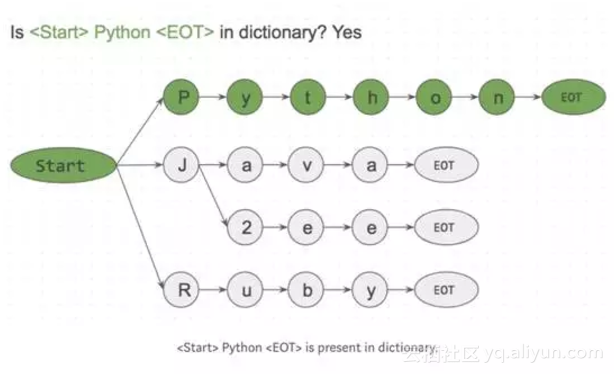
因为该算法是一个字符接一个字符匹配,在搜索<start>I时,我们可以很容易地跳过<start>like<EOT >在,因为I没有接在<start>后面。这一机制让我们可以很快跳过词库中不存在的词。
FlashText算法只检查输入字符串“I like Python”中的每个字符。即便我们的字典有一百万个关键字,这对它的运行几乎没有影响。这正是FlashText算法的能力所在。
所以你什么时候应用FlashText?
简要回答:当关键词数量>500时
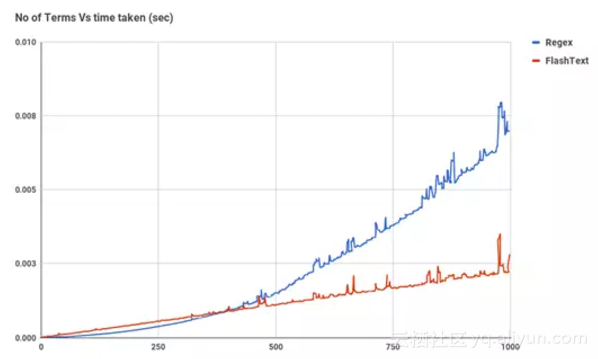
对于搜索而言,大约超过500个关键词后FlashText开始优于正则表达式。
补充:正则表达式可以搜索基于特殊字符为关键字,如^,$,*,\d,.但FlashText是不支持的。
所以如果你想匹配部分的单词(如“word\dvec”)是不行的,但它能很好地提取完整的单词(如“word2vec”)。
最后,奉上FlashText的基本功能调用代码!试一试,是不是比正则表达式快了很多呢?
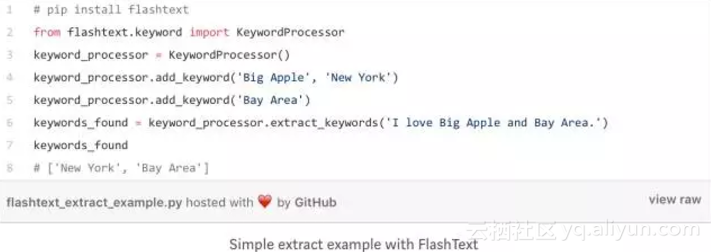
代码:用FlashText查找关键字
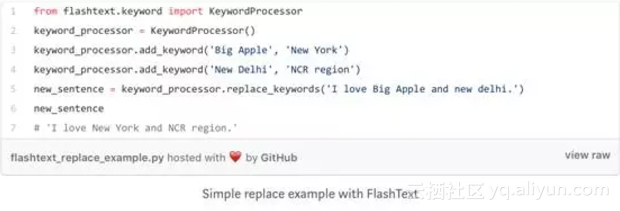
代码:用FlashText替换关键字
原文发布时间为:2017-12-14
本文作者:文摘菌
本文来自云栖社区合作伙伴“大数据文摘”,了解相关信息可以关注“大数据文摘”微信公众号