在倒腾DB的时候,SQL会占据非常大的一部分时间,遇到执行效率不高的SQL时,就需要想办法找到执行效率不高的原因,这里简单记录分析SQL的三个步骤~
使用的数据库版本为MySQL-5.7.7-rc
-----------------------------------------------------------------------------------------正文------------------------------------------------------------------------------------------
Step1,使用explain or explain extended来查看MySQL的执行计划,
extended在后续的版本会被取消,所以加不加没什么太大的关系,因为在MySQL-5.7.7-rc里面,普通的explain已经有filter了,
个人理解:filter当做是过滤百分比,大体上就是找到最终结果需要扫描多少数据,基本上,低一些会比较好。
explain在网上有很多的介绍,这理解略过吧,基本上,在Extra列里面,尽可能不要出现Use Temporary Table 和 Using file sort,相比较而言,使用临时表的影响更大,file sort会小一些。
为什么SQL的分析不在这里就打住了?
原因很简单,MySQL在优化查询的时候是只用一个索引的,所以在有些情况下,SQL查询既存在排序,又存在比较复杂的where条件,那么到底是用索引提高where条件的筛选效率?还是用索引去省掉排序的开销?(优化器?MySQL的查询优化器出了名的拙计,而且除了优化器本身的一切缺陷导致Cost计算不准确以外,MySQL本身也会根据一些参数的设置去调整优化器的策略,而这些参数大多数时候我们并不了解)
Step2,当explain搞不定的时候,就需要profile来帮忙了,这个东西可以详细的列出在每一个步骤消耗的时间,前提是先执行一遍语句。
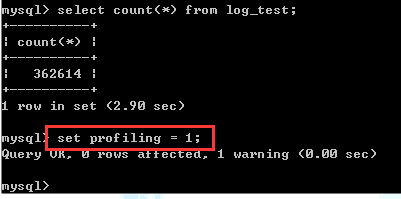
profile默认是关闭的,所以需要在client先打开,操作如下图
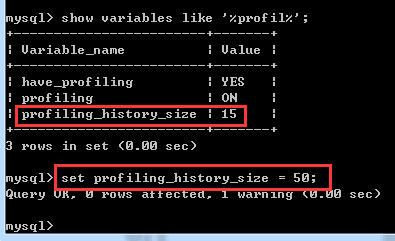
在实际的生产环境中,可能会需要加大profile的队列,保证想要查看的语句耗时结果还保存着,所以可以用如下操作来增加profile的队列大小
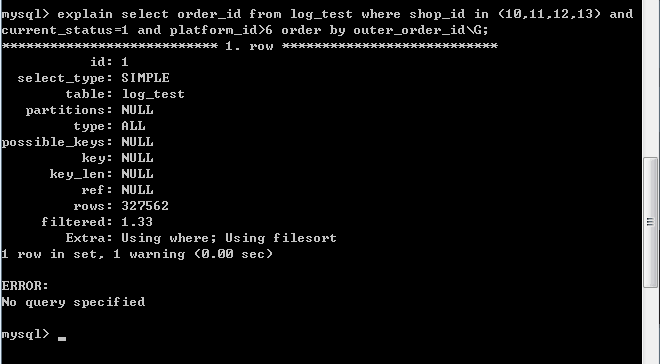
到这一步,profile的功能就已经打开了,这里简单试一下SQL语句,explain一下
显然这种语句是不合格的,那么在优化前,可以看看这条语句的耗时,先执行以下select,然后show profiles查看队列的内容,
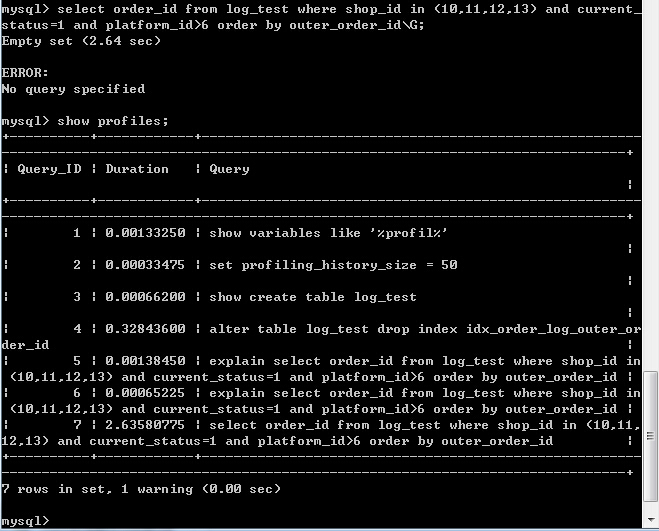
可以看到ID为7的那一行正式执行过的语句,这时候使用show profile block io,cpu for query 7来查看统计信息(红色为常用选项,可以不加的~)
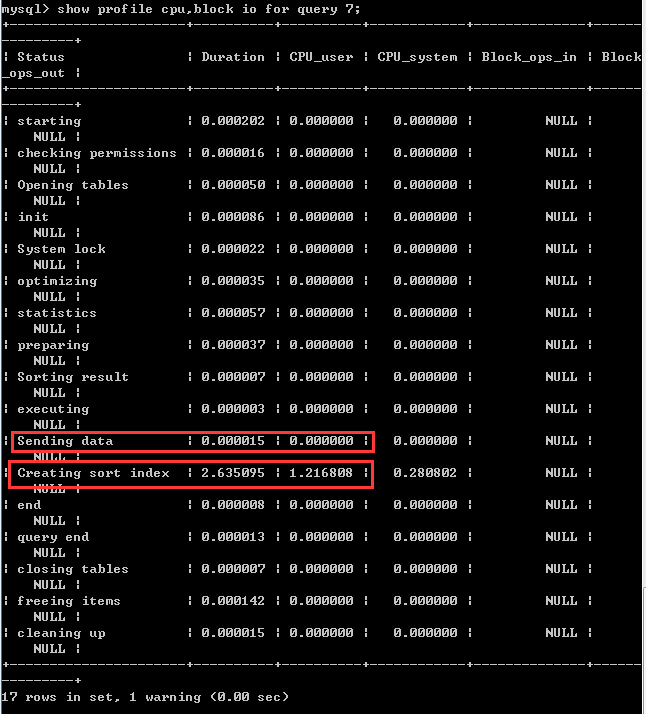
红色方框标出来了两行内容,Creating sort index消耗了接近99%的时间,说明这个查询的大部分时间消耗在了排序阶段
Sending data标出来是要特别注意一下,并不只是在服务器端和客户端之间sending data,还包括了从磁盘读取数据的时间,所以对大表执行全表扫描or索引的效率不高时,这个时间会比较高
找到了主要耗时的部分,那么就建立一个索引,再来看看profile的数据
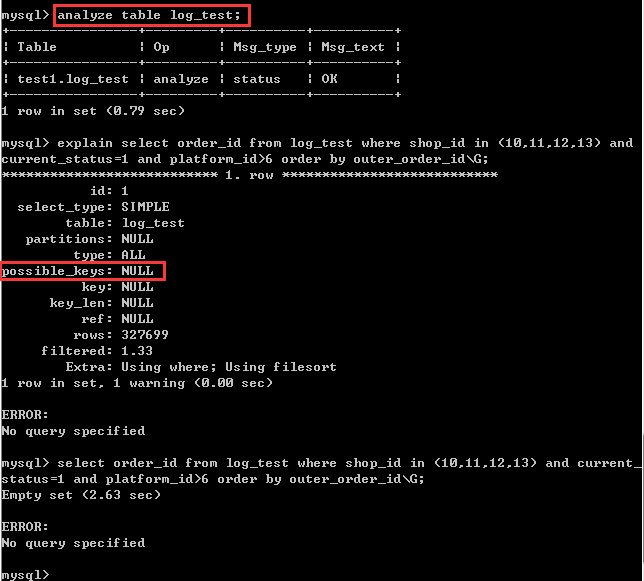
然而即便是analyze table以后,优化器依然不选择走索引,而是坚持全表扫描来执行这个语句,所以profile看了也没什么用,和之前的数据应该是差不多的, 那么为什么优化器不选择走索引 ?
Step3 Optimizer trace
Optimizer trace是MySQL5.6添加的新功能,可以看到大量的内部查询计划产生的信息,可以用如下方式打开
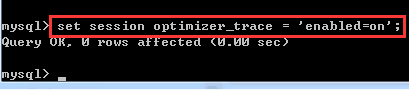
然后在information_chema.optimizer_trace的表里面查找这一条语句对应的信息
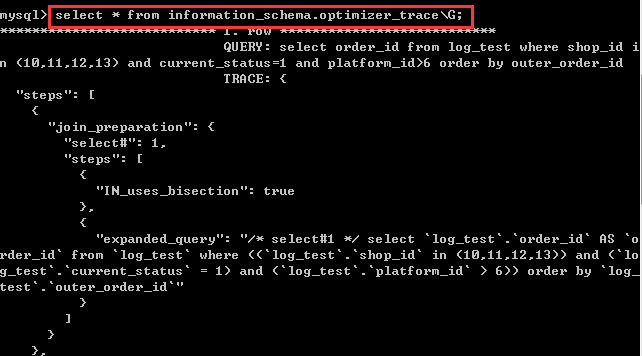
内容是json格式的,所以推荐找一个json的转换工具来辅助查看,这个json主要分为三个部分
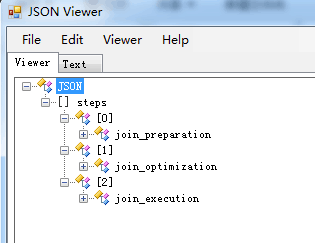
有关执行计划的选择,主要在第二部分里面
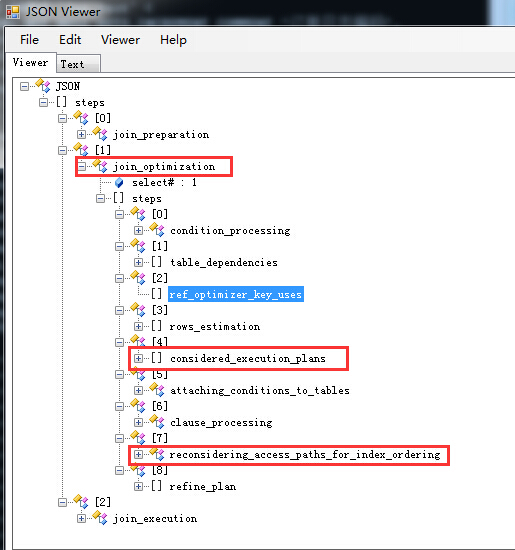
那么可以看看这两个分支的内容
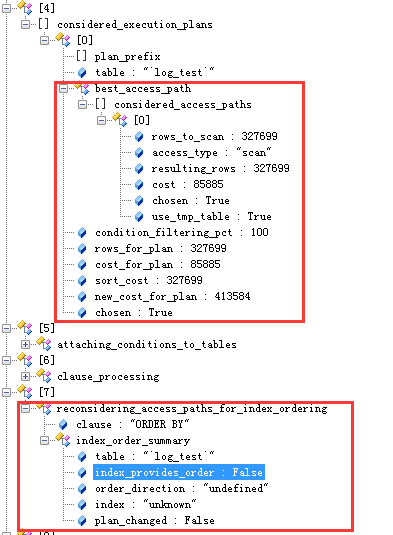
在这里面能看到详细的统计信息,包括cost,预计的rows,以及查询优化器最终的选择chosen,发现在考虑排序的影响时,并没有使用索引(index:“unknown”)
即便是加了use index,但是在Optimize trace里面依然选择了使用全表扫描,而使用了索引并没有什么优化到file sort,因为使用use index指定的index被放在了range index的考虑范围内
因为并没有读源码的计划,所以只能是做出推测:在有where条件的前提下,MySQL优化器并不会为order by 专门去计算一次cost,因为扫描这个索引并不会对where条件的行筛选有任何的帮助,到头来还是只能全表扫描,筛选出符合条件的行;如果非要用index.column,反而还要根据行标记回头去读取index的内容选出需要的数据,再重新来获得有序的行标记,本末倒置了。(_(:з」∠)_看起来有理有据让人信服的推断)
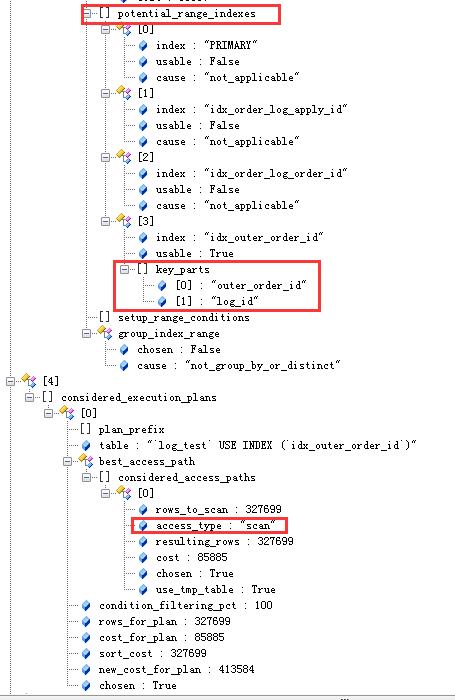

那么有什么办法能让file sort利用上索引么?
答案是:用联合索引把where筛选条件的那些列和order by 的列全部包含进去....(对于这个例子并不推荐,因为联合索引的列数量偏多;除非这种查询的数量极多)
输出信息分为两个部分,
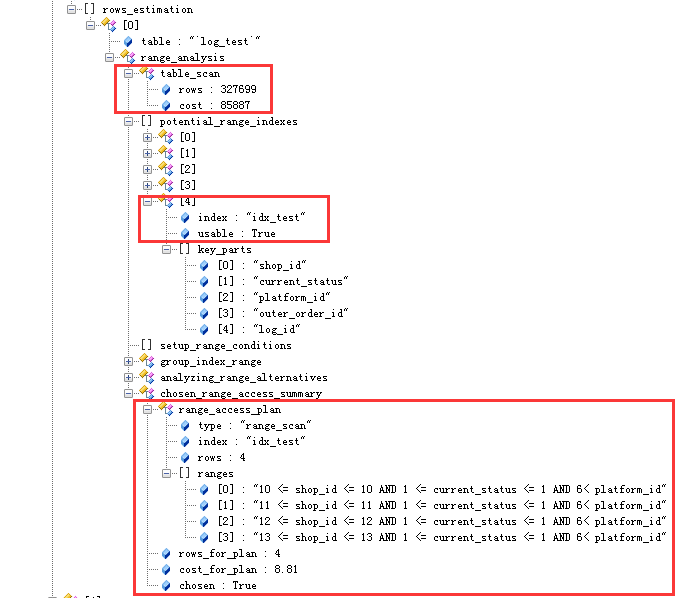
从这一部分可以看到,MySQL内部把=的操作全部换成了range,也计算了使用索引和全表扫描的cost,(用上了新的索引,意料之中)
下一部分可以看到最终决定的执行计划,以及order by阶段索引的使用情况
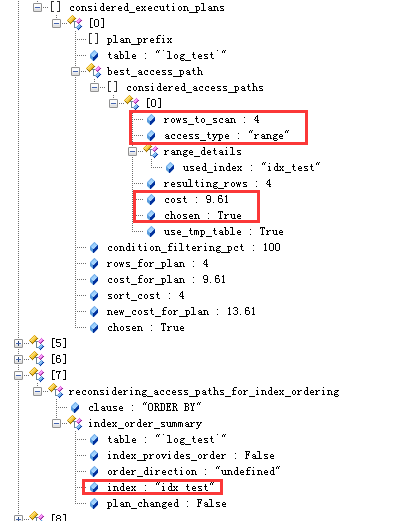
--------------------------------------------------------------------------稍显凌乱的博客的结尾处---------------------------------------------------------------------------
总结:explain可以应对大多数的状况;show profile可以帮我们更好的分析SQL优化的主要目标,是锁?还是磁盘读写?还是文件排序?等等...;而最后的optimize_trace则适合于各种疑难杂症了,比如说优化器为什么没有选择索引而是全表扫描?为什么优化器没有选择效率较好的索引,而是选择了一个效率较差的索引(order by)?等等乱七八糟的奇怪现象.....
使用的数据库版本为MySQL-5.7.7-rc
-----------------------------------------------------------------------------------------正文------------------------------------------------------------------------------------------
Step1,使用explain or explain extended来查看MySQL的执行计划,
extended在后续的版本会被取消,所以加不加没什么太大的关系,因为在MySQL-5.7.7-rc里面,普通的explain已经有filter了,
个人理解:filter当做是过滤百分比,大体上就是找到最终结果需要扫描多少数据,基本上,低一些会比较好。
explain在网上有很多的介绍,这理解略过吧,基本上,在Extra列里面,尽可能不要出现Use Temporary Table 和 Using file sort,相比较而言,使用临时表的影响更大,file sort会小一些。
为什么SQL的分析不在这里就打住了?
原因很简单,MySQL在优化查询的时候是只用一个索引的,所以在有些情况下,SQL查询既存在排序,又存在比较复杂的where条件,那么到底是用索引提高where条件的筛选效率?还是用索引去省掉排序的开销?(优化器?MySQL的查询优化器出了名的拙计,而且除了优化器本身的一切缺陷导致Cost计算不准确以外,MySQL本身也会根据一些参数的设置去调整优化器的策略,而这些参数大多数时候我们并不了解)
Step2,当explain搞不定的时候,就需要profile来帮忙了,这个东西可以详细的列出在每一个步骤消耗的时间,前提是先执行一遍语句。
profile默认是关闭的,所以需要在client先打开,操作如下图
在实际的生产环境中,可能会需要加大profile的队列,保证想要查看的语句耗时结果还保存着,所以可以用如下操作来增加profile的队列大小
到这一步,profile的功能就已经打开了,这里简单试一下SQL语句,explain一下
显然这种语句是不合格的,那么在优化前,可以看看这条语句的耗时,先执行以下select,然后show profiles查看队列的内容,
可以看到ID为7的那一行正式执行过的语句,这时候使用show profile block io,cpu for query 7来查看统计信息(红色为常用选项,可以不加的~)
红色方框标出来了两行内容,Creating sort index消耗了接近99%的时间,说明这个查询的大部分时间消耗在了排序阶段
Sending data标出来是要特别注意一下,并不只是在服务器端和客户端之间sending data,还包括了从磁盘读取数据的时间,所以对大表执行全表扫描or索引的效率不高时,这个时间会比较高
找到了主要耗时的部分,那么就建立一个索引,再来看看profile的数据
然而即便是analyze table以后,优化器依然不选择走索引,而是坚持全表扫描来执行这个语句,所以profile看了也没什么用,和之前的数据应该是差不多的, 那么为什么优化器不选择走索引 ?
Step3 Optimizer trace
Optimizer trace是MySQL5.6添加的新功能,可以看到大量的内部查询计划产生的信息,可以用如下方式打开
然后在information_chema.optimizer_trace的表里面查找这一条语句对应的信息
内容是json格式的,所以推荐找一个json的转换工具来辅助查看,这个json主要分为三个部分
有关执行计划的选择,主要在第二部分里面
那么可以看看这两个分支的内容
在这里面能看到详细的统计信息,包括cost,预计的rows,以及查询优化器最终的选择chosen,发现在考虑排序的影响时,并没有使用索引(index:“unknown”)
即便是加了use index,但是在Optimize trace里面依然选择了使用全表扫描,而使用了索引并没有什么优化到file sort,因为使用use index指定的index被放在了range index的考虑范围内
因为并没有读源码的计划,所以只能是做出推测:在有where条件的前提下,MySQL优化器并不会为order by 专门去计算一次cost,因为扫描这个索引并不会对where条件的行筛选有任何的帮助,到头来还是只能全表扫描,筛选出符合条件的行;如果非要用index.column,反而还要根据行标记回头去读取index的内容选出需要的数据,再重新来获得有序的行标记,本末倒置了。(_(:з」∠)_看起来有理有据让人信服的推断)
那么有什么办法能让file sort利用上索引么?
答案是:用联合索引把where筛选条件的那些列和order by 的列全部包含进去....(对于这个例子并不推荐,因为联合索引的列数量偏多;除非这种查询的数量极多)
输出信息分为两个部分,
从这一部分可以看到,MySQL内部把=的操作全部换成了range,也计算了使用索引和全表扫描的cost,(用上了新的索引,意料之中)
下一部分可以看到最终决定的执行计划,以及order by阶段索引的使用情况
--------------------------------------------------------------------------稍显凌乱的博客的结尾处---------------------------------------------------------------------------
总结:explain可以应对大多数的状况;show profile可以帮我们更好的分析SQL优化的主要目标,是锁?还是磁盘读写?还是文件排序?等等...;而最后的optimize_trace则适合于各种疑难杂症了,比如说优化器为什么没有选择索引而是全表扫描?为什么优化器没有选择效率较好的索引,而是选择了一个效率较差的索引(order by)?等等乱七八糟的奇怪现象.....
