附上MySQL之SQL分析三部曲地址http://blog.itpub.net/29510932/viewspace-1709732/
姐妹篇http://blog.itpub.net/29510932/viewspace-1732876/ (其实是难兄难弟篇)
-------------------------------------------------------------------------------------------------正文---------------------------------------------------------------------------------------------------------------
由于是生产环境下进行的,截图和SQL都隐去了一些信息
背景:有用户在抱怨生产系统上,某一个Web的页面太慢,忍无可忍
问题分析过程:略
问题聚焦:最终确定是某一个SQL语句太慢,查询时间用了4s(慢查询日志给出的信息)
SQL分析三部曲之一:explain,结果如下图
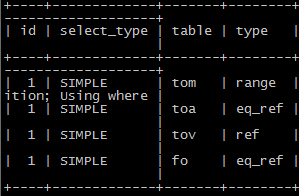

OMG, 明显有pay_tim和shop_id的联合索引,为什么要用pay_time的单列索引,简单验证下联合索引的执行计划

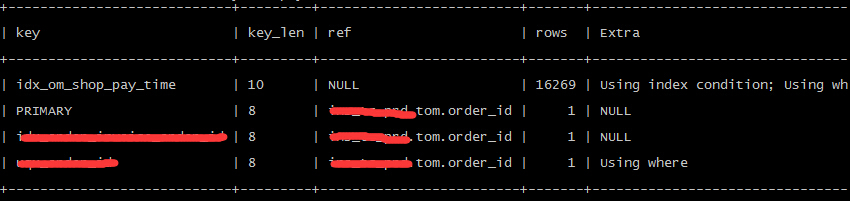
和案例一非常相似的情形,明明可以使用联合索引的地方,却使用了单列的索引,导致了预估的行数非常之高, 那么,会和案例一一样是因为统计信息的不全,导致了错误的执行计划么?
PS:案例一的情况,在没有进行任何数据库层面改动的前提下,仅仅是睡了个午觉,执行计划就变回正确的了,所以当时候判定为统计信息的问题。
然而残酷的事实就是:不管analyze table多少次,执行计划也没有改变,(没有optimize table的权限...)
SQL分析三部曲之三:optimizer_trace,操作过程略,部分结果如图
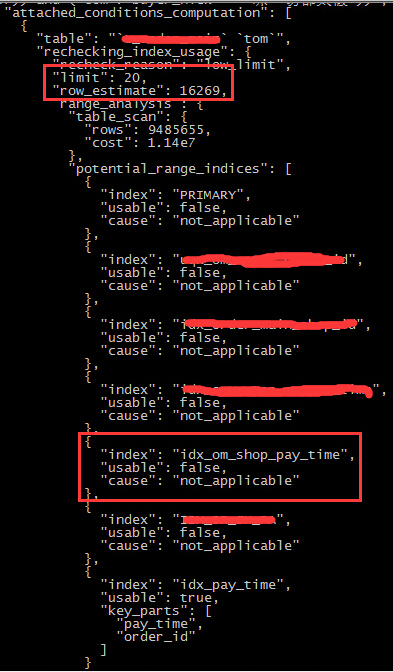
可以看到和案例一类似,由于limit的存在,导致执行计划发生了变化,但是和案例一不同的是, 这个SQL里面,limit和row_estimate的值相差的非常远!
PS:案例一中为40和51
值得注意的是,limit的数量也会影响到执行计划的选择, 比如说,limit的行数小于执行计划的row_estimate的时候,优化器会认为当前执行计划搜索出了太多的结果,进行了无谓的磁盘IO,所以会重新考虑执行计划。
在本例中, 由于在limit之前带上了order by,而且order by的列本身还是具备索引,因此,在优化器的判断逻辑中就出现了如下的一种情形:可以使用pay_time索引列,从尾部开始读取数据,然后取出前20行结果组装成结果集。所以优化器重新选择了使用pay_time的单列索引作为执行计划(这也是其他的索引均显示了“not_applicable”的原因)。
案例一的真相还原:为什么睡个午觉,执行计划就正常了?
由于在某个时间点重新统计了表的信息,行数的估计值产生了变化, 导致limit和row_estimate的大小关系发生了变化,结果就是row_estimate的值小于了limit,自然也就不会存在 rechecking_index_usage了。
在这里简单的修改了几处条件来验证之前的结论,
条件修改一:使用ignore index(idx_pay_time)
预计:如果order by的列本身并没有索引,那么在recheck里面也就没有其他的执行计划可选了,最终应该选择range_scan中的联合索引
从执行计划中可以看到idx_pay_time已经ignore了,最终执行计划选择range_scan中的联合索引

看看trace的信息
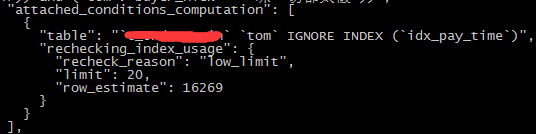
在recheck中根本就没有可选索引,所以执行计划并没有改变
条件修改二:增加limit数量直至超过row_estimate
预计:不会有recheck,执行计划采用联合索引
查看explain和trace

recheck无内容

条件修改三:去掉order by
预计:recheck无可选条件,使用联合索引
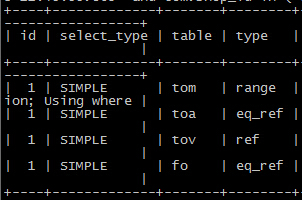
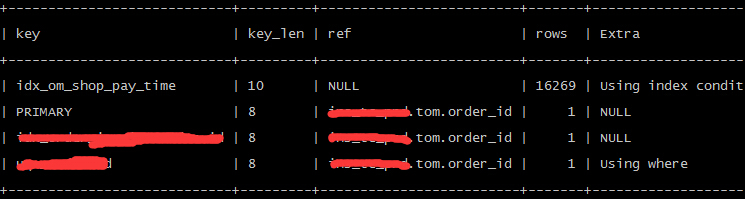
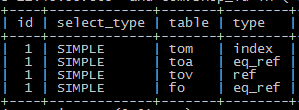
意外的收获:采用其他的索引列进行order by(仅以此献给能坚持看完这么长的内容的米娜~)
预计:执行计划采用其他的单列索引

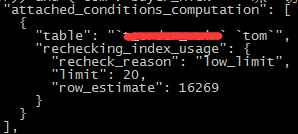
trace内容
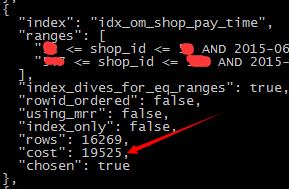
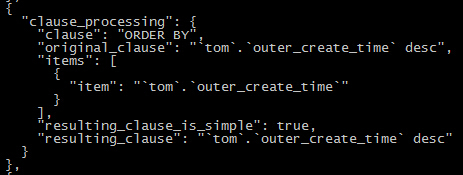
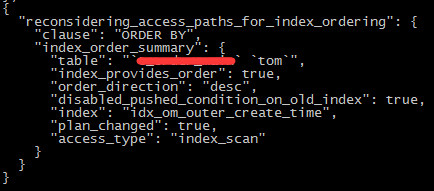
由于order by的原因,执行计划使用的索引又变了.... 究竟这么变是好是坏?(有生之年系列+1,今天实在是写不动了)
写在最后: 遇上order by+limit的时候,要么就用联合索引把where条件和order by的列全部包进去,要么就不要在order by的那一列上面建立单独的索引
PS:从字面上看,merge_index的特性也许会有奇效也说不定......(有生之年系列+1,天天在挖坑来坑自己.........~( ̄ε(# ̄)╰╮o( ̄皿 ̄///))
姐妹篇http://blog.itpub.net/29510932/viewspace-1732876/ (其实是难兄难弟篇)
-------------------------------------------------------------------------------------------------正文---------------------------------------------------------------------------------------------------------------
由于是生产环境下进行的,截图和SQL都隐去了一些信息
背景:有用户在抱怨生产系统上,某一个Web的页面太慢,忍无可忍
问题分析过程:略
问题聚焦:最终确定是某一个SQL语句太慢,查询时间用了4s(慢查询日志给出的信息)
点击(此处)折叠或打开
点击(此处)折叠或打开
- select *
- from tom
- inner join toa on tom.order_id=toa.order_id
- left join tov on tom.order_id=tov.order_id
- left join fo on tom.sale_type=2 and fo.order_id=tom.order_id
- WHERE(tom.pay_time>='2015-06-23 11:45:55.869' and tom.pay_time<='2015-07-23 11:45:55.869' and tom.shop_idin(1,2) and tom.buyer_nick='你们真是够了23333')
- order by tom.pay_time desc
- limit 0,20
OMG, 明显有pay_tim和shop_id的联合索引,为什么要用pay_time的单列索引,简单验证下联合索引的执行计划
和案例一非常相似的情形,明明可以使用联合索引的地方,却使用了单列的索引,导致了预估的行数非常之高, 那么,会和案例一一样是因为统计信息的不全,导致了错误的执行计划么?
PS:案例一的情况,在没有进行任何数据库层面改动的前提下,仅仅是睡了个午觉,执行计划就变回正确的了,所以当时候判定为统计信息的问题。
然而残酷的事实就是:不管analyze table多少次,执行计划也没有改变,(没有optimize table的权限...)
SQL分析三部曲之三:optimizer_trace,操作过程略,部分结果如图
可以看到和案例一类似,由于limit的存在,导致执行计划发生了变化,但是和案例一不同的是, 这个SQL里面,limit和row_estimate的值相差的非常远!
PS:案例一中为40和51
值得注意的是,limit的数量也会影响到执行计划的选择, 比如说,limit的行数小于执行计划的row_estimate的时候,优化器会认为当前执行计划搜索出了太多的结果,进行了无谓的磁盘IO,所以会重新考虑执行计划。
在本例中, 由于在limit之前带上了order by,而且order by的列本身还是具备索引,因此,在优化器的判断逻辑中就出现了如下的一种情形:可以使用pay_time索引列,从尾部开始读取数据,然后取出前20行结果组装成结果集。所以优化器重新选择了使用pay_time的单列索引作为执行计划(这也是其他的索引均显示了“not_applicable”的原因)。
案例一的真相还原:为什么睡个午觉,执行计划就正常了?
由于在某个时间点重新统计了表的信息,行数的估计值产生了变化, 导致limit和row_estimate的大小关系发生了变化,结果就是row_estimate的值小于了limit,自然也就不会存在 rechecking_index_usage了。
在这里简单的修改了几处条件来验证之前的结论,
条件修改一:使用ignore index(idx_pay_time)
预计:如果order by的列本身并没有索引,那么在recheck里面也就没有其他的执行计划可选了,最终应该选择range_scan中的联合索引
从执行计划中可以看到idx_pay_time已经ignore了,最终执行计划选择range_scan中的联合索引
看看trace的信息
在recheck中根本就没有可选索引,所以执行计划并没有改变
条件修改二:增加limit数量直至超过row_estimate
预计:不会有recheck,执行计划采用联合索引
查看explain和trace
recheck无内容
条件修改三:去掉order by
预计:recheck无可选条件,使用联合索引
意外的收获:采用其他的索引列进行order by(仅以此献给能坚持看完这么长的内容的米娜~)
预计:执行计划采用其他的单列索引
trace内容
由于order by的原因,执行计划使用的索引又变了.... 究竟这么变是好是坏?(有生之年系列+1,今天实在是写不动了)
写在最后: 遇上order by+limit的时候,要么就用联合索引把where条件和order by的列全部包进去,要么就不要在order by的那一列上面建立单独的索引
PS:从字面上看,merge_index的特性也许会有奇效也说不定......(有生之年系列+1,天天在挖坑来坑自己.........~( ̄ε(# ̄)╰╮o( ̄皿 ̄///))


