elasticsearch2.x发布有一段时间了,抽空把集群搭起来,做点实验
-------------------------------------------------------------------------------------正文------------------------------------------------------------------------------------
elasticsearch1.7的搭建非常简单,只需要把tar.gz的包下载到linux服务器上解压缩,然后在bin目录下启动es即可,
集群的搭建也非常简单,保证cluster_name一致, node_name不一致就好了,
可以在同一个网段自动发现新节点,也可以在配置文件的discovery.zen.ping.unicast.hosts属性中指定集群的节点IP;
----------------------------------------------------------------------------------接下来开始填坑------------------------------------------------------------------------------
启动失败---->
坑一:Exception in thread "main" java.lang.RuntimeException: don't run elasticsearch as root.
填坑:解释为“防止attacker 获取root权限”, 如果是RPM包安装,会自动创建elastsearch组和elastsearch用户,设置好密码,换一个用户启动即可
坑二:Increase RLIMIT_MEMLOCK, soft limit: XXXXX, hard limit: XXXXX
填坑:es为了性能考虑,推荐关掉swap,并锁定一部分mem,按照日志中的指引操作即可

一般处理好这两个,注意一下文件和日志的权限,基本就能正常的启动了;
搭建集群失败-->
首先要注意的一点,在1.7的时候,es判断集群是否可用时,会用index.number_of_replicas去判断,
但是在2.1.1中,这个变成了discovery.zen.minimum_master_nodes,当集群的node低于设定值的时候,集群会无法访问
PS:这个参数在介绍中是用来防止选举master发生脑裂的一个参数,实际上当存活节点数低于这个值,就选举不出master了;
测试中采用四个node来搭建集群
坑三:手动把四个host写进了discovery.zen.ping.unicast.hosts,但是没有手动指定discovery.zen.minimum_master_nodes的值,每一个node启动以后都把自己设置为Master
填坑:network.host默认采用的是127.0.0.1,这个问题可能会受到hosts的影响,为了意义明确,写成机器的IP,问题解决
坑四:手动把四个host写进了discovery.zen.ping.unicast.hosts,并且手动指定discovery.zen.minimum_master_nodes的值,启动node以后出现报错,ping其他的node超时 or 不停的等待初始化;

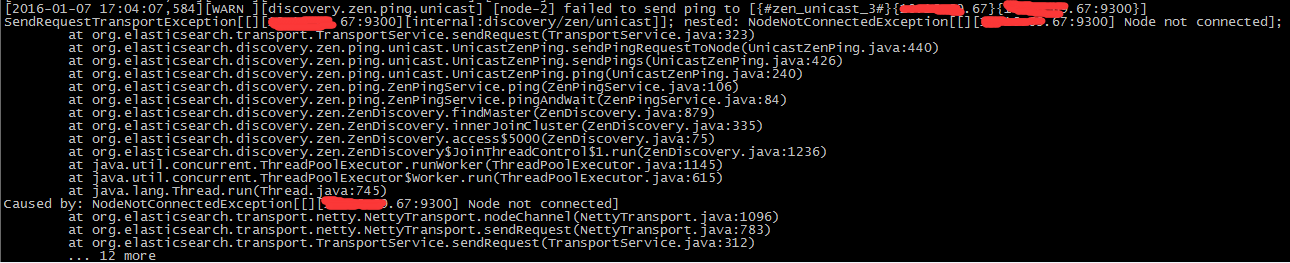
填坑:推测es自身应该是自动计算这个discovery.zen.minimum_master_nodes的, 如果手动指定以后,往集群中添加机器时,数量小于discovery.zen.minimum_master_nodes就会出现这种现象,
只需要继续往里面添加节点,直到超过手动指定的值,集群会自动选举Master,并正常运转起来。
总结:
不要用root启动,修改memlock的设置,手动指定network.host的值,discovery.zen.minimum_master_nodes可以手动写,也可以不写,保证cluster_name一致, node_name不一致,es2.1.1的集群就可以正常启动了
PS:jdk至少是1.7, 作为测试用的话,ES_HEAP_SIZE可以不写
