冷扑大师 Libratus 与“冷门” NIPS 2017 最佳论文
CMU 教授 Tuomas Sandholm 及其学生 Noam Brown 所开发的人工智能德扑系统 Libratus,被国内同行翻译成 “冷扑大师”。冷扑大师在 2017年1月,与四位德扑职业高手对阵,大获全胜,赢得了接近总数的筹码 [1]。
2017年11月,Noam Brown 与 Tuomas Sandholm 合著的论文,“Safe and Nested Endgame Solving for Imperfect-Information Games”,获得 NIPS 2017 最佳论文奖 [2]。
但是这篇最佳论文,在国内业界引起的讨论,似乎不算特别热烈。原因可能有三条,
1. 这篇论文非常不好懂。光数学符号的定义,就整整占了一节内容。数学符号定义结束后,是很大篇幅的定理证明。初读一遍,云里雾里。
2. 非热门的理论根基。当下热门的机器学习领域,是深度学习和强化学习。而这篇论文的理论根基,是博弈论和运筹学。
3. 方法论的通用性。若干读者认为,冷扑大师的算法,可能仅仅适用于德扑,或者充其量能够扩展到其它棋牌类游戏。应用前景有限。
11月8日,Tuomas Sandholm 来北京参加新智元举办的世界人工智能大会AI World 2017,并做主题演讲。餐叙时,Sandholm 教授对笔者说,从应用前景来说,冷扑大师的算法,不仅可以用于赌博,也可以用于谈判,拍卖定价,投资决策等等。

11月8日,Tuomas Sandholm(中)来北京参加新智元举办的世界人工智能大会,餐叙时与新智元创始人兼CEO杨静(左)和本文作者邓侃博士交流
从方法论来说,冷扑算法的理论根基是博弈论和运筹学。而强化学习学习的理论根基是马尔科夫决策过程和动态规划。虽然来源不同,但是终将殊途同归。
冷扑算法与强化学习和深度学习殊途同归之日,必将大放异彩。
冯·诺依曼曾经这样说,“真实的生活,(不会像围棋那样)可以毫无遮拦地洞察整个棋局。真实生活中充斥着虚张声势、欺诈、揣度对方心理。这才是我所研究的博弈。”
读懂冷扑大师这篇最佳论文,关键是理解四个概念,
- 纳什均衡策略,
- 反事实最佳策略,
- 抽象,
- 终局。
冷扑大师的算法与纳什均衡策略:不让对方占便宜
目前冷扑大师只会打双人德扑。当然,把算法改进一下,多用几核 GPU,也可以打多人德扑。
打德州扑克时,先发给每个牌手两张暗牌,然后陆续发 5 张明牌,期间 4 轮下注,最后比大小 [3]。

德扑难在揣摩对手的两张暗牌。公开的信息,是 5 张明牌和双方下注的历史。但是,对方不会严格按照自己手中的暗牌来下注,而是有意夹杂着各种误导战术,譬如虚张声势等等。
冷扑大师是如何识别对手的下注策略呢?
其实,冷扑大师不推测对手的下注策略。
稍微具体一点,冷扑大师追求的目标,是能够达到纳什均衡(Nash Equilibrium)的策略。纳什,就是著名的数学家,电影《美丽心灵》的男主角。纳什均衡策略,是不让对方占便宜的策略。
纳什均衡策略是被动的防御策略,而不是主动的进攻策略。也就是说,纳什均衡策略不揣度对手的下注策略。
举个例子,假如对方的策略,是不论自己手上的暗牌是什么,不动脑子地一味跟着我方下注。打了几手以后,即便我方发现了对方的策略,根据纳什均衡,我方也不会趁自己牌好时,冒进地抬高赌注,赚对方便宜。
纳什均衡策略,不揣度对方的策略。但是,对方会不会寻找纳什均衡策略的漏洞?
理论上说,纳什均衡策略能够保证,在经过了多次牌局摈除了运气的成分后,是不存在被对方利用的漏洞的。
问题是,冷扑大师的算法,是不是严格意义上的纳什均衡策略?这篇论文,之所以大段大段证明数学定理,目的就是为了证明,至少在一对一的情况下,冷扑大师的算法,是逼近纳什均衡策略的。
如何寻求最佳下注策略?先做一个下注对应表
既然纳什均衡策略不揣度对手的下注策略,那么就可以用机器自我博弈的办法,尽可能枚举各种可能的牌局,寻求最佳的下注策略。
我们不妨做一张下注对应表(Action Mapping),七列,若干行。
- 第一列:我方手中的两张暗牌
- 第二列:牌桌上已经发了的明牌,最多有 5 张明牌
- 第三列:双方下注的历史
- 第四列:我方手上剩下的筹码
其实,可以通过第三列(双方下注的历史)来推算第四列(我方手上剩下的筹码)。设置第四列的目的,是为了方便。
- 第五列:对方手上的两张暗牌
- 第六列:我方决定马上要下注的筹码数量
- 第七列:对应第六列决策的收益
前四列是输入,论文中被称为局面(Information Set,InfoSet)。后三列是输出,分别是推测、决策和收益。
假如我们有足够的计算能力,我们枚举各种可能的局面(InfoSet)。
第一列,我方手上两张暗牌(pre-flop),总共有 (52 * 51) / (2 * 1) = 1,326 种组合。
第二列,先发三张明牌(flop),总共有 (50 * 49 * 48) / (3 * 2 * 1) = 19600 种组合。然后,再两次发单牌(turn、river)。加起来,总共有 19600 + 19600 * 47 + 19600 * 47 * 46 = 43,316,000 种组合。
如果把第一列和第二列的所有组合加在一起,那么总数是 1,326 * 43,316,000 = 57,437,016,000。
第三列下注及其历史,组合数量就更多了。所以,这张表的行数巨大,论文上说是 10^165 行。这个数量级太大了,即便用当今世界最强大的云计算系统,估计也得算上几十年。
不过,假如我们有足够的计算能力,能够遍历出这张表,那么我们就可以计算出面对特定的牌局,各种下注决策对应的平均收益。
譬如,发完全部 5 张明牌之后(river),对方手里的两张暗牌,总共有 (45 * 44) / (2 * 1) = 990 种组合。又假如,前三轮下注(pre-flop, flop, turn),总共有 N 种下注历史。这时候如果轮到我方下注,每一种下注策略,譬如下注手头剩下的全部筹码(all in),将面临 990 * N 种可能的收益。这 990 * N 种收益的平均值,就是这种下注策略的平均收益。
面对特定的牌局,我们计算出了各种下注决策对应的平均收益以后,就可以找出平均收益最高的那种下注决策。
平均收益最高的那种下注决策,是否就是纳什均衡策略?不是。
原因是,当对方手里的暗牌的牌力很低时,譬如对方手里的两张暗牌是一张红桃三一张梅花六(3h6c),对方大金额下注的概率很低。
那么,如何估算对方下注策略的概率?
这个问题比较复杂,因为对方下注,不仅仅依据对方手里的暗牌和桌面的明牌,而且,对方会根据我方下注的历史,来估算我方手里的暗牌。
反事实最佳策略:寻找纳什均衡策略的流行算法
反事实最佳策略(Counterfactual Best Response, CBR ),是一种近年来比较流行的,寻找纳什均衡策略的算法 [4]。
反事实最佳策略有三大要素:1. 模拟,2. 悔牌(regret),3. 迭代(iteration)。
面对各种局面(InfoSet),也就是前述的局面下注对应表的前四列,先假设我方以随机均等概率选择下注策略。这样经过一系列发牌和下注,牌局结束,然后清点我方的收益或损失。
这样模拟几亿次牌局,大致覆盖各种可能的局面。
然后悔牌。面对某种特定局面,也就是固定住对应表的前四列,换句话说,也就是我方有特定的两张暗牌,桌面上有最多五张特定的明牌,再加上特定的下注历史。悔牌的意思是,面对某种特定局面,我方不随机选择下注策略,而是只认定一种下注方式,譬如跟注(call)。
悔牌以后,后续亮出的明牌,不会改变。但是我方和对方,后续下注的历史会发生改变。
把刚才几亿次牌局,重新模拟一遍。重新模拟时,双方暗牌和桌面上的明牌不变,发牌顺序不变,悔牌以前的下注历史不变,但是悔牌以后的下注历史改变。每次下注时,除了悔牌那个特定策略,其余的下注策略不变。
这样重新模拟了一次以后,就可以计算出悔牌的策略,平均收益是多少。
然后换一种悔牌策略,也就是面对同样局面,只认定另一种下注方式。譬如前一次悔牌的策略是跟注(call),这一次模拟的悔牌策略,改为加码(raise),然后把刚才几亿次牌局,重新模拟第二遍。这样就可以计算出第二种悔牌策略的平均收益。
模拟了若干次以后,就可以估算出,面对同样的局面,各种可能的悔牌策略,及其平均收益。
重复以上模拟过程,确定各种局面的各种策略,及其平均收益。
然后,更新下注对应表(Action Mapping)。先清空表中第五列,也就是不枚举对方手上的两张暗牌。然后在第七列,填入每一种下注策略的平均收益。
以上是第一轮模拟和悔牌,然后进行第二轮模拟。
第二轮模拟时,先假设对方仍然按照随机均等的概率,选择下注策略。而我方根据第一轮更新后的下注对应表,选择下注决策。
面对同样一个局面,也就是表中的前四列,我方按以下方式选择下注策略。
- 先根据当前的局面,也就是暗牌明牌加下注历史,找到更新后的下注对应表中,所有相应的行。
- 更新后的下注对应表中,第六列是下注策略,第七列是平均收益。根据平均收益,选择下注策略。收益越高,相应下注策略被选中的概率越高。
这样,确定了第二轮模拟的暗牌明牌,发牌顺序,以及我方和对方最初下注历史。
然后,悔牌。并再做一个下注对应表,记录面对各种局面时,各种下注策略的平均收益。
第三轮模拟时,我方用第二版下注对应表,对方用第一版下注对应表。经过多次模拟过程,得到第三版下注对应表。
如此重复迭代。经过多轮模拟迭代以后,所得到的下注对应表,将是逼近纳什均衡的最佳策略。
简化牌局,降低计算负担
如第三节所述,下注对应表中,单单第一列和第二列的组合,就高达 57,437,016,000 种。如果在加上各种可能的下注历史,那么下注对应表的行数,是 10^165 数量级。
另外,用反事实最佳策略算法,来寻找纳什均衡策略,需要经过几十亿次模拟。
下注对应表的行数太多,反事实最佳策略算法的模拟次数太多,导致计算量太大,难以承受。
一个显而易见的解决办法,是简化牌局(Abstraction),以便精简下注对应表的行数。
譬如,一个对子,红桃八和黑桃八(8h8s),与另一个对子,方片八和梅花八(8d8c),这两个对子的牌力,是相似的。所以,可以把两个八的对子,总共 (4 * 3) / (2 * 1) = 6 种组合,都简化成下注对应表中的一行。
但是牌力的计算,需要很仔细,譬如一对八,与一个八一个九,哪一种组合的牌力大?假如 5 张明牌分别是七、十、勾、外加两张散牌,那么一个八一个九可以与明牌组合成从七到勾的顺子,而一对八与五张明牌的最大组合,仍然是一对八。
所以,牌力的计算,不仅要看牌面本身的大小,而且要枚举两张暗牌,与 5 张明牌的各种可能的组合。[5] 详细讲述了牌力的计算方法。另外,也讲述了如何根据牌力,对牌面进行抽象的做法(Card Abstraction)。
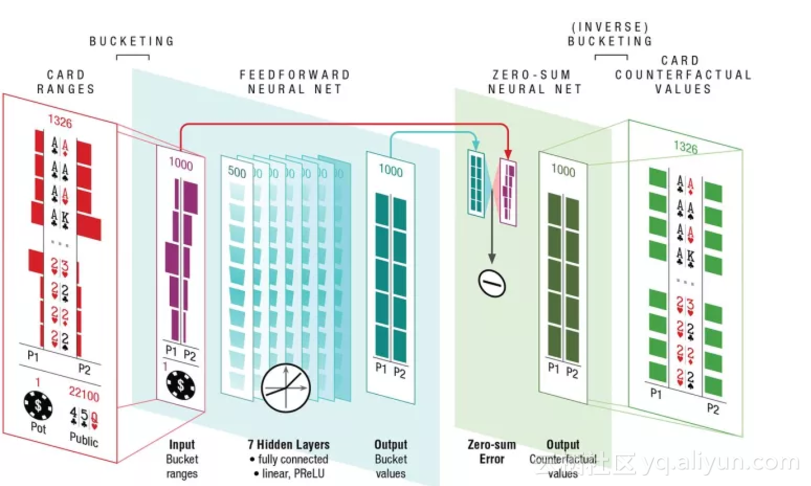
DeepStack对牌面进行抽象,详见[5]
不仅对牌面要进行抽象,而且对下注也要进行抽象,譬如只允许四种下注方式,弃牌(fold)、跟注(call)、加码(raise)、孤注一掷(all in)。
经过抽象后,牌局组合的总数,被大大降低。譬如 [4] 把总数为 10^165 的牌局组合,简化到 10^12。
牌局组合总数降低后,反事实最佳策略模拟迭代,就可行了。
终局,误算与精算
但是,简化牌局,会导致误算。譬如根据牌力,我们把一对七与一对八,归为同一种局面。但是,假如双方一路对赌到底,谁也不中途弃牌(fold),只好最后亮牌(showdown)。
亮牌的时候,我方一对七,对方一对八,虽然牌力区别微小,但是却决定最终胜负。这就是所谓误算(Off-tree Problem)。
解决误算的办法,是用精算(re-solving)来替代抽象(abstraction)。
精算的核心,是通过拟合双方下注历史,来反向推算对方手里的两张暗牌,及其概率。
假设我方的两张暗牌是 h1,对方的两张暗牌是 h2。又假设我方和对方,都按照反事实最佳策略来下注,那么就可以通过查找下注对应表,推算出各种下注策略的概率。
譬如,pre-flop 时,我方的暗牌是一对八,对方的暗牌是一对 A。假如首次下注由我方开始,我方加码(raise)的概率很大,但是 all-in 的概率几乎为 0。但是对方 all-in 的概率,会比 0 大很多。
现在给定一个特定的下注历史,我们可以通过查找下注对应表,计算出每一步下注的概率。所谓下注历史,就是一连串的下注,下注历史的概率,就是一连串概率的乘积。
通过计算下注历史的概率,我们不仅可以估算对方手里的暗牌,而且还可以估算对方背离正常的下注策略的幅度和波动,也就是说,我们能够估算得出对方虚张声势(bluffing)的概率。
估算出了对方的暗牌,以及对方 bluffing 的概率,终局的精算,就比较容易了。无非是把对方的暗牌,与我方的暗牌相比较,推算出我方胜出的概率,以此决定下注的金额。
原文发布时间为:2017-12-14
本文作者:邓侃
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号