从执行计划的预估行数可以看出执行计划是否正确,作为优化的你曾经注意到了么?
今天在监控系统垃圾sql语句的时候发现一个sql语句跑了10个小时了,凭直觉这个sql肯定哪里出现问题了,好吧,老规矩,先看看内存中执行计划和具体的sql语句吧,这里的sql语句:
INSERT /*+ append */ INTO CJG_MID_ACCT(ACCT,PARTY_NO,CHINESE_NAME,DATE_OPENED,RMB_CURRENT_BAL,BILL_DATE,RMB_CRLIM,AI_LAST,PSTL_CD,BIRTHDAY,GENDER,APPLICATION_NO,RMB_BLOCK_CODE_1,RMB_BLOCK_CODE_1_MEMO,RMB_BLOCK_CODE_2,RMB_BLOCK_CODE_2_MEMO,USD_CURRENT_BAL,USD_BLOCK_CODE_1,USD_BLOCK_CODE_1_MEMO,USD_BLOCK_CODE_2,USD_BLOCK_CODE_2_MEMO,DATE_ACTIVE,CURRENT_CARD_CNT,EDUCATION_DEGREE,INDUSTRY_TYPE,COMPANY_ATTRIBUTE,SALES_CODE,ANNUAL_INCOME,SOURCE_CODE,UTILIZATION_FLAG,CURRENT_FLAG,MOB,AGE,SFNAME,CITY,AI_FIRST) SELECT A.*,C.ACCT_ACTIVE_DATE AS DATE_ACTIVE, B.CURRENT_CARD_CNT,D.EDUCATION_DEGREE, D.INDUSTRY_TYPE,D.COMPANY_ATTRIBUTE,D.SALES_CODE,D.ANNUAL_INCOME,D.SOURCE_CODE, 'N' AS CURRENT_FLAG,'N' AS CURRENT_CURRENT_FLAG, TRUNC(MONTHS_BETWEEN(TO_DATE(SUBSTR(:B1 ,1,6),'yyyymm'),TO_DATE(SUBSTR(DATE_OPENED,1,6),'yyyymm')),0) AS MOB, FLOOR((TO_DATE(:B1 ,'yyyymmdd')-TO_DATE(A.BIRTHDAY,'yyyymmdd'))/365) AS AGE, NVL(E.SFNAME,'其他') AS SFNAME,NVL(E.QXNAME,'其他') AS CITY,D.AI AS AI_FIRST FROM TEMP_MID_ACCT_TMP02 A LEFT JOIN TEMP_MID_ACCT_CARDCNT B ON A.ACCT=B.ACCT LEFT JOIN TEMP_MID_ACCT_ACTIVED C ON A.ACCT=C.POST_TO_ACCT LEFT JOIN RISKREPT.RKO_CDM_PROCESS D ON A.APPLICATION_NO=D.APPLICATION_NO LEFT JOIN DIC_ZIP_CODE E ON SUBSTR(A.PSTL_CD,1,4)=E.ZIPCODE;
执行:SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('djmga872c636s',0,'advanced')); 得到执行计划如下图:
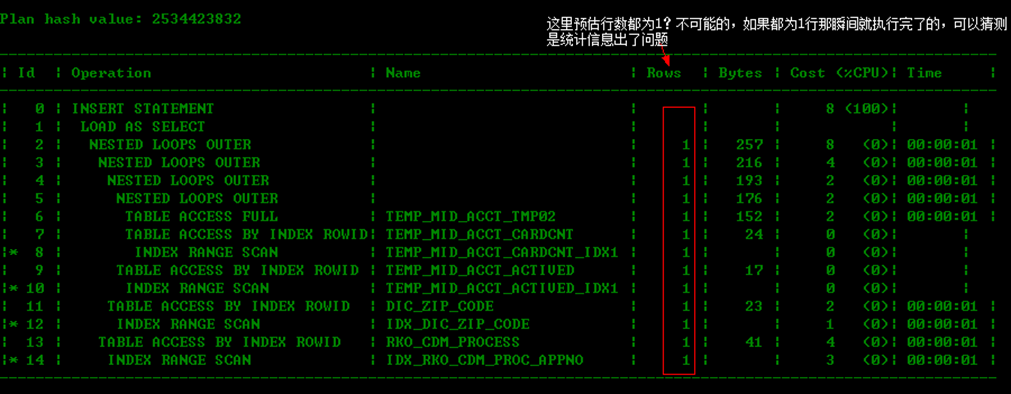
从执行计划其实就可以看出问题来了,我们这里再多走一步吧,先看看历史sql中,这个语句跑了多久呢?
select * from XB_SQL_MONITOR_LHR a where a.SQL_ID='djmga872c636s';

可以看出历史sql中这条语句仅仅跑了45分钟,好吧,我们再看看历史sql的执行计划吧:
select DBMS_XPLAN.display_awr(sql_id => 'djmga872c636s') from dual;
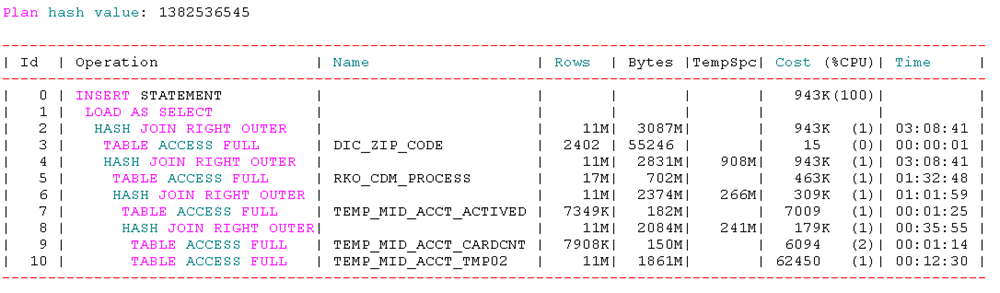
这里我截取了其中一个我认为正确的执行计划,大家从附件中可以看到有很多历史执行计划,,好了,,,,废话少说吧,,,,,,,,,
所有历史执行计划参考附件,建议使用UE或者ediplus打开: sqlid(djmga872c636s)的历史sql执行计划.sql
sqlid(djmga872c636s)的历史sql执行计划.sql
到这里我们知道,这个sql的执行计划改变过,正确的预估行数少的有2000行,多的有1000W+的数据,好吧,我们在从数据字典中具体查看一下涉及到的表的具体行数吧,请看:
SELECT *
FROM vq_table_lhr a
WHERE a.TABLE_NAME IN ('TEMP_MID_ACCT_TMP02',
'TEMP_MID_ACCT_CARDCNT',
'TEMP_MID_ACCT_ACTIVED',
'RKO_CDM_PROCESS',
'DIC_ZIP_CODE')
;

可以看出,相关的5个表,最小的1M,最大的有31G,怎么可能num_rows和blocks都为0呢?操蛋,,,,,oracle自动收集不智能,,,,,,当然也有可能是空表,高水位没有降下来,没事,我们收集统计信息后再看看就知道了,执行:
BEGIN
dbms_stats.gather_table_stats(USER, 'DIC_ZIP_CODE',cascade => TRUE,degree => 8);
dbms_stats.gather_table_stats(USER, 'TEMP_MID_ACCT_ACTIVED',cascade => TRUE,degree => 8);
dbms_stats.gather_table_stats(USER, 'TEMP_MID_ACCT_CARDCNT',cascade => TRUE,degree => 8);
dbms_stats.gather_table_stats(USER, 'TEMP_MID_ACCT_TMP02',cascade => TRUE,degree => 8);
dbms_stats.gather_table_stats('RISKREPT', 'RKO_CDM_PROCESS',cascade => TRUE,degree => 20);
END;
表比较多,分析比较慢,,,等等等等,,,,,,不要急嘛,,,在神马都是快节奏的今天我们更应该时不时的停下我们繁忙的脚步看看周边美丽的风景的,,,,,,,千呼万唤始出来,,,,,,,对表进行分析执行完成后,继续查看,行数和块数:
SELECT *
FROM vq_table_lhr a
WHERE a.TABLE_NAME IN ('TEMP_MID_ACCT_TMP02',
'TEMP_MID_ACCT_CARDCNT',
'TEMP_MID_ACCT_ACTIVED',
'RKO_CDM_PROCESS',
'DIC_ZIP_CODE')
;

好吧,大家可以看出num_rows和blocks都正确了,最大的表竟然有3500W+的数据,难怪跑这么慢,同时也证明了之前我们猜测可能是表的高水位没有降下来这个结论是错误的,我们再重新跑一跑之前的sql语句,捕捉一下执行计划,偷懒一下,直接用plsql developer工具来看吧:
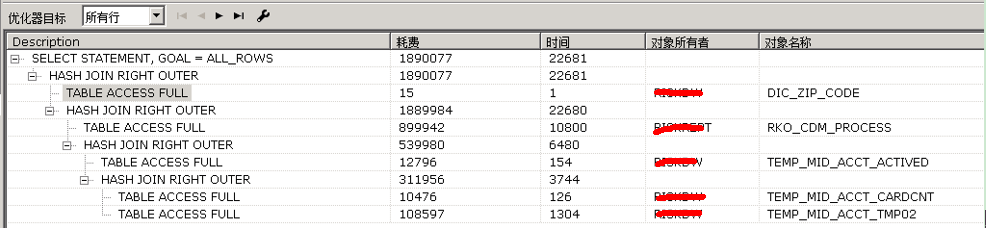
好了,应该没有神马问题了,,,,,,
结论
1、有关CBO模式下,统计信息一定要准确,不然可能出现N多不知神马的问题,sql执行计划瞎走,之前哥还遇到过统计信息不准确导致执行计划走了笛卡尔积连接了,晕晕晕 ,,,,,,啥事都有,,,,,,不过那个例子忘记截取下来了
,,,,,,啥事都有,,,,,,不过那个例子忘记截取下来了
2、另外,大家可以写一个定时的job,对这一类统计信息错误的表定时分析,或者如果表的数据量变化不是很大的情况下,我们可以锁定这些临时表的统计信息,不让系统的job对这些表重新分析
3、网上有大牛说我们看AWR报告的时候要有一双敏锐的鹰眼,这里我也提出看执行计划的时候我们同样应该具备一双更敏锐的鹰眼,瞅一眼就知道哪里的问题了,请看这只眼:



