今天照例巡查垃圾sql时,发现一个跑了很长时间的sql,且其执行计划也非常的大,这个sql非常可疑,得排查排查:

第一步,照例查询内存中的执行计划:
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('17t226txddfy5',0,'advanced'));
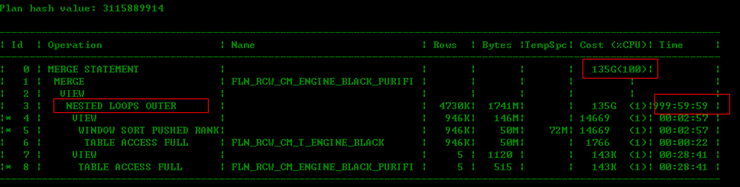

可以看出执行计划的cost花费非常的大,且Predicate Information(即谓语)部分全是filter过滤的,怎么会没有access访问呢???????拿出其具体的sql语句:
MERGE INTO FLN_RCW_CM_ENGINE_BLACK_PURIFI BLACK_PURIFI
USING (SELECT *
FROM (SELECT T.*,
ROW_NUMBER() OVER(PARTITION BY CERTIFICATION_NO_18, INFO_CHARACTER, FILTER_CONFIG_ID ORDER BY CERTIFICATION_NO_18) NUM
FROM FLN_RCW_CM_T_ENGINE_BLACK T) T
WHERE NUM = 1) BLACK
ON (BLACK_PURIFI.CERTIFICATION_NO_18 = BLACK.CERTIFICATION_NO_18 AND BLACK_PURIFI.INFO_CHARACTER = BLACK.INFO_CHARACTER AND (BLACK.FILTER_CONFIG_ID IS NULL OR BLACK_PURIFI.FILTER_CONFIG_ID = BLACK.FILTER_CONFIG_ID) AND BLACK_PURIFI.DATE_DELETE IS NULL)
WHEN MATCHED THEN
UPDATE
SET BATCH_DATE = :B1,
FLAG_DELETE = 'N',
PURIFICATION_DATE = :B1
WHEN NOT MATCHED THEN
INSERT
VALUES
(:B1,
BLACK.CERTIFICATION_NO_18,
BLACK.FILTER_GRADE,
BLACK.FILTER_GRADE_CONTENT,
BLACK.INFO_CHARACTER,
BLACK.INFO_CHARACTER_CONTENT,
'Y',
TO_DATE(:B1,
'yyyy-mm-dd'),
'N',
NULL,
SYSDATE,
SYSDATE,
:B1,
BLACK.FILTER_CONFIG_ID)
;
我们看看其数据量吧,我之前提出过一个观念:任何离开数据量来谈sql优化都是没有意义的:
select * from vw_table_lhr v where v.TABLE_NAME in ('FLN_RCW_CM_ENGINE_BLACK_PURIFI','FLN_RCW_CM_T_ENGINE_BLACK');

可以看出,统计信息是最近收集的,一张是小表,一张是大表,根据sql语句可以看出该sql是属于典型的用小表来更新大表,根据原来的执行计划看出走的是NL连接,且内表是全表扫描,这样的话内表大约要要访问94W+次,每次都对10G的大表来全表扫描的,大家知道,NL连接至少要保证内表的关联列有个索引,外表返回的结果集非常的小这个时候效率才非常的高,但是这里呢????神马都不满足,,,,,你还敢走NL??????脑残,,,,,所以这个执行计划很恐怖的,当然也是错误的执行计划,这里应该走hash连接,或者利用一下索引神马的,当然,这里如果只是单纯的update语句的话,我们可以采用快速游标更新法,效率是非常好的,但是这里同时涉及到update和insert语句,根据经验这个应该修改为merge语句的非关联形式的表对表的更新,所以优化后的sql如下:
优化后的sql:
MERGE INTO RISKREPT.FLN_RCW_CM_ENGINE_BLACK_PURIFI BLACK_PURIFI
USING (SELECT BLACK_PURIFI.ROWID ROWIDS,
BLACK.*
FROM (SELECT *
FROM (SELECT T.*,
ROW_NUMBER() OVER(PARTITION BY CERTIFICATION_NO_18, INFO_CHARACTER, FILTER_CONFIG_ID ORDER BY CERTIFICATION_NO_18) NUM
FROM FLN_RCW_CM_T_ENGINE_BLACK T) T
WHERE NUM = 1) BLACK,
RISKREPT.FLN_RCW_CM_ENGINE_BLACK_PURIFI BLACK_PURIFI
WHERE BLACK_PURIFI.CERTIFICATION_NO_18 = BLACK.CERTIFICATION_NO_18
AND BLACK_PURIFI.INFO_CHARACTER = BLACK.INFO_CHARACTER
AND (BLACK.FILTER_CONFIG_ID IS NULL OR
BLACK_PURIFI.FILTER_CONFIG_ID = BLACK.FILTER_CONFIG_ID)
AND BLACK_PURIFI.DATE_DELETE IS NULL) T
ON (BLACK_PURIFI.ROWID = T.ROWIDS)
WHEN MATCHED THEN
UPDATE
SET BATCH_DATE = :B1,
FLAG_DELETE = 'N',
PURIFICATION_DATE = :B1
WHEN NOT MATCHED THEN
INSERT
VALUES
(:B1,
T.CERTIFICATION_NO_18,
T.FILTER_GRADE,
T.FILTER_GRADE_CONTENT,
T.INFO_CHARACTER,
T.INFO_CHARACTER_CONTENT,
'Y',
TO_DATE(:B1,
'yyyy-mm-dd'),
'N',
NULL,
SYSDATE,
SYSDATE,
:B1,
T.FILTER_CONFIG_ID)
;
优化后的执行计划:
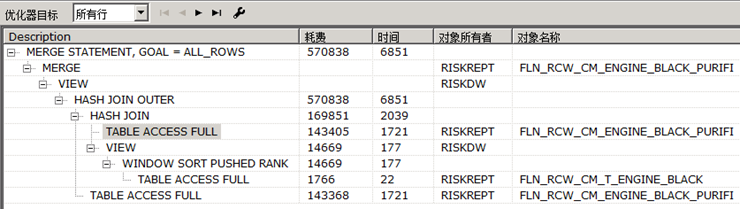
从执行计划来看,对这个sql的简单优化进行的差不多了。
注:这篇文章是几天前就写好的,但是博客审核有点问题,今天重新发布一下,就在发布之前我看了一下该语句仍然在跑,也就是已经运行了大概4天的时间还没有跑完,,,,,时间就这么过去了,,,,,,所以对系统垃圾sql语句的监控仍然是比较重要的。
这篇博客的后传地址:http://blog.itpub.net/26736162/viewspace-1222417/
- 大家看博文的时候应该注意解决问题的整体思路,这个才是重点
- 有关连接方式的另一篇博文 http://blog.itpub.net/26736162/viewspace-1208814/