为何在查询中索引未被使用 (文档 ID 1549181.1)
“为什么索引没有被使用”是一个涉及面较广的问题。有多种原因会导致索引不能被使用。首要的原因就是统计信息不准,第二原因就是索引的选择度不高,使用索引比使用全表扫描效率更差。还有一个比较常见的原因,就是对索引列进行了函数、算术运算或其他表达式等操作,或出现隐式类型转换,导致无法使用索引。还有很多其它原因会导致不能使用索引,这个问题在MOS(MOS即My Oracle Support)“文档1549181.1为何在查询中索引未被使用”中有非常详细的解释,作者已经将相关内容发布到BLOG(http://blog.itpub.net/26736162/viewspace-2113670/)上了。下面是一些非常有用的检查项目。
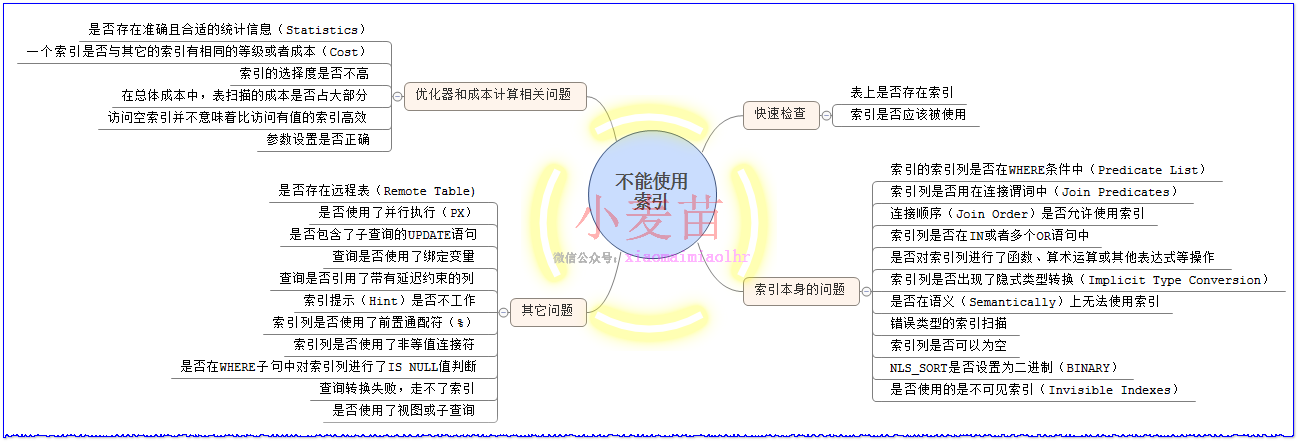
一、快速检查
n 表上是否存在索引?
n 索引是否应该被使用?
二、索引本身的问题
n 索引的索引列是否在WHERE条件中(Predicate List)?
n 索引列是否用在连接谓词中(Join Predicates)?
n 连接顺序(Join Order)是否允许使用索引?
n 索引列是否在IN或者多个OR语句中?
n 是否对索引列进行了函数、算术运算或其他表达式等操作?
n 索引列是否出现了隐式类型转换(Implicit Type Conversion)?
n 是否在语义(Semantically)上无法使用索引?
n 错误类型的索引扫描?
n 索引列是否可以为空?
n NLS_SORT是否设置为二进制(BINARY)?
n 是否使用的是不可见索引(Invisible Indexes)?
三、优化器和成本计算相关问题
n 是否存在准确且合适的统计信息(Statistics)?
n 一个索引是否与其它的索引有相同的等级或者成本(Cost)?
n 索引的选择度是否不高?
n 在总体成本中,表扫描的成本是否占大部分?
n 访问空索引并不意味着比访问有值的索引高效?
n 参数设置是否正确?
四、其它问题
n 是否存在远程表(Remote Table)?
n 是否使用了并行执行(PX)?
n 是否包含了子查询的UPDATE语句?
n 查询是否使用了绑定变量?
n 查询是否引用了带有延迟约束的列?
n 索引提示(Hint)是否不工作?
n 索引列是否使用了前置通配符(%)?
n 索引列是否使用了非等值连接符?
n 是否在WHERE子句中对索引列进行了IS NULL值判断?
n 是否查询转换失败导致不能选择索引?
n 是否使用了视图或子查询?
详细情况如下表所示:

文档内容
用途
排错步骤
快速检查
表上是否存在索引?
索引是否应该被使用?
索引本身的问题
索引列或者索引的前置列是否在单表(non-join)查询的 Where 条件中(predicate list)?
索引列是否用在连接谓词中(join predicates)?
索引列在 IN 或者多个 OR 语句中?
索引列是否被函数修改?
隐式类型转换(implicit type conversion)是什么?
是否在语义(semantically)上无法使用索引?
错误类型的索引扫描?
是否索引列为可空?
NLS_SORT是否设置为二进制(BINARY)?
是否使用的是不可见索引(invisible indexes)?
优化器和成本计算相关问题
是否存在准确且合适的统计信息(Statistics)?
一个索引是否与其它的索引有相同的等级或者成本(cost)?
索引的选择度不高?
在总体成本中,表扫描的成本占大部分
访问空索引并不意味着比访问有值的索引高效。
参数设置
其它问题
是否使用了视图/子查询?
是否存在远程表(remote table)?
是否使用并行执行(PX)?
是否是包含了子查询的Update语句?
查询是否使用了绑定变量?
查询是否引用了带有延迟约束的列?
索引提示(hint)不工作
有用的 hints:
参考
适用于:
Oracle Database - Standard Edition - 版本 8.1.7.4 和更高版本
Oracle Database - Personal Edition - 版本 8.1.7.4 和更高版本
Oracle Database - Enterprise Edition - 版本 8.1.7.4 和更高版本
本文档所含信息适用于所有平台
用途
这篇文章用来解答下面的问题:为什么我的索引没有被使用?
排错步骤
“为什么索引没有被使用”是一个涉及面较广的问题。有很多种原因会导致索引没有被使用。下面是一些非常有用的检查列表。请点击下面链接来查看文章的具体内容:
快速检查
表上是否存在索引?
检查您认为应该通过索引访问的表上是否真的有定义索引。那些索引可能已经被删掉或者在创建的时候就失败了 – 比如一种可能的场景是,在对表做导入或 load 操作后,由于软件或人为错误造成索引没有被创建。下面的语句可以用来检查索引是否存在。
SELECT index_name FROM user_indexes WHERE table_name = &Table_Name;索引是否应该被使用?
Oracle 不会仅仅因为有索引存在就一定要使用索引。如果一个查询需要检索出这个表里所有的记录(比如说表之间做连接操作),那为什么还要既访问索引的所有数据又访问表的所有数据呢?在这种情况下只访问表的数据会更快。对所有的查询 Oracle Optimizer 会基于统计信息来计算各种访问路径,包括索引,从而选出最优的一个。索引本身的问题
索引列或者索引的前置列是否在单表(non-join)查询的 Where 条件中(predicate list)?
如果不是,至少需要索引前置列在查询谓词列表中,查询才能使用索引。(例外:请见下面的 Skip Scan)。
示例:
在列 EMP.EMPNO 上定义了单列索引 EMPNO_I1,同时在列 EMP.EMPNO 和 EMP.DEPT 上定义了联合索引 EMPNO_DEPT_I2(EMP.EMPNO为索引前置列)。那么必须在查询谓词列表中(where从句)使用列 EMP.EMPNO,优化器才能使用这两个索引中的某一个。
SELECT ename, sal, deptno FROM emp WHERE empno<100;
例外:
只要索引中包含查询所需的所有列, 而且至少有一个索引列中含有非空约束,CBO 就能够使用索引快速全扫描(INDEX_FFS)。执行 INDEX_FFS 不需要索引前置列。需要注意的是 INDEX_FFS 不能保证返回的行是排序的。结果的顺序是与读取索引块的顺序一致的,只有当使用了 'order by' 子句时才能保证结果是排序的。请参照:
Document 344135.1 Ordering of Result DataCBO 能使用 Index Skip Scan (INDEX_SS). 执行 INDEX_SS 不需要索引前置列。请参照:
Document 70135.1 Index Fast Full Scan Usage To Avoid Full Table Scans
Document 212391.1 Index Skip Scan FeatureCBO 能够选用一个索引来避免排序,但是索引列必须存于在 order by 子句中才可以。
请参照
Document 67409.1 When will an ORDER BY use an Index to Avoid Sorting?
Document 10577.1 Driving ORDER BY using an Index索引列是否用在连接谓词中(join predicates)?
例如,下面这个连接谓词定义了如何在表 emp 和 dept 的 deptno 列上做连接:
emp.deptno = dept.deptno
如果索引列是连接谓词的一部分,那么查询在执行时使用了哪种类型的连接?
哈希/排序合并连接(Hash / Sort Merge Join): 对于哈希连接和排序合并,在连接执行的时候,外部表的信息还没有获得,因此无法进行对内部表的行检索。它的处理方式是将外部表和内部表分别查询后将结果合并。哈希连接和排序合并的内部表不能通过连接的索引列单独被访问。这是连接类型的执行机制的限制。嵌套循环连接有所不同,它们允许通过索引查询内部表的连接列。
嵌套循环连接(Nested Loops Join):嵌套循环连接读取外部表,然后利用所收集的信息访问内部表。该算法允许对内部表基于索引进行查询。
只有嵌套循环连接(Nested loops join)允许索引在内部表中仅基于连接列进行查找。
另外,连接的顺序(join order)是否允许使用索引?
一个嵌套循环连接的外部表必须已经访问过,才可以在内部表中使用索引。查看 explain plan,以确定哪些访问路径已经使用。由于这个限制,表的连接顺序是很重要的。
例如:如果我们通过"emp.deptno = dept.deptno"来对 EMP 和 DEPT 做连接,并且在 EMP.DEPTNO 有一个索引,并假设查询中没有与 EMP.DEPTNO 相关的其他谓词,EMP 是在 DEPT 前被访问,然后没有值可用于在 EMP.DEPTNO 索引中查询。在这种连接顺序下,要想使用这个索引我们只能使用全索引扫描或索引快速全扫描。在这种情况下,全表扫描(FTS)的成本可能更小。索引列在 IN 或者多个 OR 语句中?
比如:
或emp.deptno IN (10,23,34,....)
emp.deptno = 10 OR emp.deptno = 23 OR emp.deptno = 34 ....
这种情况下查询可能已经被转化为不能使用索引的语句。请参照:
Document 62153.1 Optimization of large inlists/multiple OR`s索引列是否被函数修改?
索引不能用于被函数修改的列。函数索引(function based indexes)可以用来解决这个问题。
Oracle Database Online Documentation 12c Release 1 (12.1) / Database Administration
Database Concepts
Chapter 3 Indexes and Index-Organized Tables
Overview of Function-Based Indexes
http://docs.oracle.com/database/121/CNCPT/indexiot.htm#CBBGIIFB
Oracle Database Online Documentation 12c Release 1 (12.1) / Database Administration
Database Performance Tuning Guide
Chapter 2 Designing and Developing for Performance
Section 2.5.3 Table and Index Design
http://docs.oracle.com/database/121/TGDBA/pfgrf_design.htm#CJHCJIDB隐式类型转换(implicit type conversion)是什么?
如果进行比较的两个值的数据类型不同,则 Oracle 必须将其中一个值进行类型转换使其能够比较。这就是所谓的隐式类型转换。通常当开发人员将数字存储在字符列时会导致这种问题的产生。Oracle 在运行时会强制转化其中一个值,(由于固定的规则)在索引字符列使用 to_number。由于添加函数到索引列所以导致索引不被使用。实际上,Oracle 也只能这么做,类型转换是一个应用程序设计因素。由于转换是在每行都进行的,这会导致性能问题。详见:
Document 232243.1 ORA-01722 ORA-01847 ORA-01839 or ORA-01858 From Queries with Dependent Predicates是否在语义(semantically)上无法使用索引?
出于对查询整体成本的考虑,一个成本较低的执行计划中可能是无法使用索引的。某索引可能已经被考虑在某种连接排序及方法中,但是成本最低的那个执行计划中却无法从“语义”角度使用该索引。错误类型的索引扫描?
例如:快速全索引扫描而不是索引范围扫描
这可能是优化器选择了所需的索引,但却使用了客户不希望的扫描方法。在这种情况下,利用 INDEX_FFS,INDEX_ASC 和 INDEX_DESC 提示来强制使用需要的扫描类型。 请参照:
Document 62339.1 Init.ora Parameter "FAST_FULL_SCAN_ENABLED" Reference Note
我们还可以定义索引的排序顺序为递增或递减。Oracle 对待降序索引就好像它是基于函数的索引,因此与缺省使用的升序的执行计划不同。通过查看执行计划,您看不到使用升序或降序,需要额外检查视图 DBA_IND_COLUMNS 的'DESCEND'列。是否索引列为可空?
索引不存储 NULL 值,除非该索引为联合索引(即多列索引),或者它是一个位图索引。
只有至少有一个索引列有值,联合索引才存储空值。联合索引中尾部的空值也会被存放在索引中。如果所有列的值都为空,这行将不会存储在索引中。由于索引中缺乏 NULL 值,那么一些结果中可能会返回 NULL 值(如count)的操作可能会被禁用索引。这是因为优化器不能保证在单独使用索引时可以获得准确的信息。关于使用 NOT IN 和 NULL 的其他一些考虑,请参考
Document 28934.1 Use of indexes with NOT IN subquery
位图索引允许存储空值。因此优化器会使用这些索引,无论它们的结果可信与否。索引上的空值有时很有用,特别对于某些类型的 SQL 语句,如与聚合函数 COUNT 查询。示例:
SELECT count(*) FROM emp;
位图索引的更多信息请参考
Document 70067.1 All about Bitmap IndexesNLS_SORT是否设置为二进制(BINARY)?
如果 NLS_SORT 未设置为二进制,索引将不会被使用。这是因为索引是基于 Key 值的二进制顺序来建立的(pre-sorted使用二进制值)。无论优化器设置为何种方法,NLS_SORT 不是二进制时,将使用全表扫描,。更多关于NLS_SORT和索引的使用,请参考:
Document 30779.1 Init.ora Parameter "NLS_SORT" Reference
Document 227335.1 Linguistic Sorting - Frequently Asked Questions (section 4.)是否使用的是不可见索引(invisible indexes)?
从 Oracle Database 11g Release 1开始,您可以创建不可见索引或将一个已经存在的索引标记为不可见。Optimizer 不会考虑不可见索引,除非在 session 或 system 级将参数 OPTIMIZER_USE_INVISIBLE_INDEXES 设置为 TRUE。DML 操作还是会维护这些不可见索引的。详见:
Oracle Database Online Documentation 12c Release 1 (12.1) / Database Administration
Database Administrator's Guide
Understand When to Use Unusable or Invisible Indexes
http://docs.oracle.com/database/121/ADMIN/indexes.htm#CIHJIDJG优化器和成本计算相关问题
是否存在准确且合适的统计信息(Statistics)?
CBO 依赖于准确的、最新的和完整的统计信息来确定一个特定查询的最佳执行计划。如果使用 CBO,请确保统计信息已经收集。如果没有统计信息, CBO 将使用预定义的统计信息,这样是很可能不会产生良好的计划或让应用程序使用索引。请参照:
Document 754931.1 Cost Based Optimizer - Common Misconceptions and Issues - 10g and Above请注意,CBO 会根据开销(COST)来决定使用不同的索引。除了基本的表和索引的信息之外,如果说在某些列上数据分布是不均匀的,那么还需要收集这些列的数据的分布。关于收集统计信息的建议,请参见以下文档:
Document 1369591.1 Optimizer Statistics - Central Point
Document 44961.1 Statistics Gathering: Frequency and Strategy Guidelines
在一般情况下,对象的数据或结构的改变会使以前的统计信息不准确,因此应该重新收集新的统计信息。例如,对表装载了大量的数据后,需要收集新的统计信息。安装新补丁集(Patchset)后,也建议重新收集统计信息。表访问最佳效果是统计信息是在相同版本的数据库中生成的。 下边的文档讨论了为什么数据库升级后查询的性能会下降:
Document 160089.1 TROUBLESHOOTING: Server Upgrade Results in Slow Query Performance一个索引是否与其它的索引有相同的等级或者成本(cost)?
对于相同开销(COST)的索引,CBO 会使用多种办法将不同的索引区分开,如将索引名称按字母顺序排序,完全匹配的索引扫描会选择更大的NDK(不同键值的个数)的索引(不适用于快速全扫描)或选择叶块数量较少的索引。请注意一般很少发生这种情况。 请查看
Document 73167.1 Handling of equally ranked (RBO) or costed (CBO) indexes索引的选择度不高?
索引的选择度不高
使用它可能不是一个好的选择...
列数据不是平均分布的。 CBO 假定列数据不会倾斜,并均匀分布。如果不是这样,那么统计信息可能没有反映真实情况,那么即使某些值的选择度高,索引也会因为整个列的选择度不高而不适用索引。 如果是这种情况,那么应考虑采用直方图记录更准确的列的数据分布或者采用提示(hint)。 统计信息不准确导致索引看起来选择性不高而不被选择。可能的规避方法: 收集更精确的统计值。 请查看
Document 1369591.1 Optimizer Statistics - Central Point对于数据分布不均匀的列考虑收集列的统计信息 使用 hint 或 outline。请参考
Document 44961.1 Statistics Gathering: Frequency and Strategy Guidelines
在总体成本中,表扫描的成本占大部分
通常来说,当使用索引的时候,我们需要再次检索表本身来找到索引中不存在的字段的值,这个操作比检索索引本身的开销要大很多。由于 optimizer 是基于总体的成本来计算执行计划,如果通过索引检索表的成本很大,并且超过了某个阀值,optimizer 就会考虑其他的访问路径。
比如
这条语句可能会使用基于列 empno的索引,因为所有需要的数据都存放在索引中所以不需要再对表做而外的访问。反之:SELECT empno FROM emp WHERE empno=5
这条语句会需要对表做而外的访问,因为 ename 字段没有存放在索引中。检索 ename 的开销会随着查询返回记录条数的增加而变得昂贵。SELECT ename FROM emp WHERE empno=5
Optimizer 使用"Clustering Factor"来判断如果使用 index 的话需要而外对表做多少次访问,详见:
Document 39836.1 Clustering Factor访问空索引并不意味着比访问有值的索引高效。
Reorganization, Truncation 或删除操作不一定会影响 SQL 语句执行的成本。需要注意的是删除操作并不会从对象中真正释放空间。也就是说,删除操作不会重置对象的高水位线。Truncate 操作会重置高水位线。空块的存在会使索引/表扫描的成本比实际应该的成本高。删掉并重建会重组对象的结构从而有可能会有帮助(也有可能变坏)。这类问题通常在比较两个有相同数据的不同系统查询性能时更容易看到。参数设置
某些参数的设置可能会影响索引的使用。比如在大多数情况下都建议使用 DB_FILE_MULTIBLOCK_READ_COUNT 和 OPTIMIZER_INDEX_COST_ADJ 的默认值。除非某些特定的操作有特定的建议,使用其它值会使索引的成本不现实的减少或变大从而极大的降低查询的性能。其它问题
是否使用了视图/子查询?
查询涉及到视图或者子查询时可能会被改写,导致不使用索引(尽管该改写的目标之一是扩展更多的访问路径)。这些改写(rewrite)一般来说都是合并(merging)操作。请查看
Document 199070.1 Optimizing statements that contain views or subqueries是否存在远程表(remote table)?
通常远程表不会使用索引。索引在分布式查询中的使用依赖于被发送到远程的查询。CBO 将评估远程访问的成本,并评估比较发送或者不发送索引的谓词到远程站点的成本。因此,CBO 可以做出有关远程表上使用索引的更加明智的决定。一个非常有效的方法就是,在远程建立包含相关谓词的视图并强制使用索引,之后在本地查询中使用这个视图。 请参考
Document 68809.1 Distributed Queries是否使用并行执行(PX)?
在并行执行时索引的采用比在串行执行((serial execution))时更加严格。一个快速检测的方法就是禁用并行,然后查看该索引是否被使用。是否是包含了子查询的Update语句?
在一些情况下,基于成本的考虑,索引没有被选使用是因为它依赖于一个子查询返回的值。这种情况下,可以使用提示(hint)来强制使用索引。请参考
Document 68084.1 Using hints to optimize an Update with a subquery that is not using an index on the updated table.查询是否使用了绑定变量?
CBO 对 like 或范围谓词的绑定变量不能产生准确的成本(cost)。这可能会导致索引不被选择。 请参考
Document 68992.1 Predicate Selectivity查询是否引用了带有延迟约束的列?
如果一个表中的某一列上含有延迟约束(比如 NOT NULL)并且这一列上有索引,那么不管这个约束当前是延迟状态或是被显式地设置为立即使用,我们都不会考虑使用这一列上的索引。例如:
CREATE TABLE tdc
( x INT CONSTRAINT x_not_null NOT NULL DEFERRABLE INITIALLY DEFERRED RELY,
y INT CONSTRAINT y_not_null NOT NULL,
z VARCHAR2(30)
);
CREATE INDEX t_idx ON tdc(x);SET CONSTRAINTS ALL IMMEDIATE; <-- 将所有延迟约束置为立即使用
SET AUTOTRACE TRACEONLY EXPLAINSELECT COUNT(1) FROM tdc; <-- 索引不会被使用
Execution Plan
----------------------------------------------------------
Plan hash value: 2532426293
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| TDC | 1 | 2 (0)| 00:00:01 |
-------------------------------------------------------------------这个现象在以下 bug 中记录,关闭为"not a bug":
Bug 17895663 optimizer ignoring deferrable constraints even when not deffered and not in tx索引提示(hint)不工作
请使用表的别名。 请参考
有用的 hints: FIRST_ROWS 相当于提示使用索引 ORDERED 强制查询的关联顺序(join order of a query)。Oracle 推荐使用 LEADING hint 因为它更好用。 LEADING 这个 hint 告诉 optimizer 先使用指定的表做连接。它比 ORDERED 更好用。 INDEX 强制使用索引扫描, 并禁用快速模式(INDEX_FFS) INDEX_FFS 强制使用快速索引扫描INDEX_FFS INDEX_ASC 强制使用升序的索引范围扫描(Ascending Index Range Scan) INDEX_DESC 强制使用降序的索引范围扫描(Descending Index Range Scan)
参见:
Document 29236.1 QREF: SQL Statement HINTS参考
NOTE:30779.1 - Init.ora Parameter "NLS_SORT" Reference Note
NOTE:67409.1 - When will an ORDER BY use an Index to Avoid Sorting?
NOTE:227335.1 - Linguistic Sorting - Frequently Asked Questions
NOTE:69992.1 - Why is my Hint Ignored?
NOTE:754931.1 - Cost Based Optimizer - Common Misconceptions and Issues - 10g and Above
NOTE:10577.1 - Driving ORDER BY using an Index (Oracle7)
NOTE:62153.1 - Optimization of Large Inlists / Multiple OR Conditions
NOTE:28426.1 - Partition Views and the use of Indexes (7.1 & 7.2)
NOTE:1369591.1 - Master Note: Optimizer Statistics
NOTE:44961.1 - Statistics Gathering: Frequency and Strategy Guidelines
NOTE:160089.1 - Troubleshooting a Server Upgrade Resulting in Slow Query Performance
NOTE:70135.1 - Index Fast Full Scan Usage To Avoid Full Table Scans
NOTE:43194.1 - Partition Views in 7.3: Examples and Tests
NOTE:50607.1 - How to specify an INDEX Hint
NOTE:212391.1 - Index Skip Scan Feature
NOTE:70067.1 - All about Bitmap Indexes
NOTE:28934.1 - Use of Indexes with NOT IN Subquery
NOTE:73167.1 - Handling of equally ranked (RBO) or costed (CBO) indexes
NOTE:199070.1 - Optimizing statements that contain views or subqueries
NOTE:68809.1 - Distributed Queries
NOTE:68084.1 - Using hints to optimize an Update with subquery not using index on updated table
NOTE:68992.1 - Predicate Selectivity
NOTE:344135.1 - Ordering of Result Data
NOTE:29236.1 - QREF: SQL Statement HINTS
About Me
...............................................................................................................................
● 本文来自MOS(1549181.1、67522.1)
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-06-02 09:00 ~ 2017-06-30 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。