Oracle重做日志文件
--=========================================
-- Oracle 联机重做日志文件(ONLINE LOG FILE)
--=========================================
一、oracle中的几类日志文件
Redo log files -->联机重做日志
Archive log files -->归档日志
Alert log files -->告警日志
Trace files -->跟踪日志
user_dump_dest -->用户跟踪日志
backupground_dump_dest -->进程跟踪日志
--查看后台进程相关目录
SQL> show parameter dump
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
background_core_dump string partial
background_dump_dest string /u01/app/oracle/admin/orcl/bdump
core_dump_dest string /u01/app/oracle/admin/orcl/cdump
max_dump_file_size string UNLIMITED
shadow_core_dump string partial
user_dump_dest string /u01/app/oracle/admin/orcl/udump
关于Oracle 常用目录及路径请参考:Oracle 常用目录结构(10g)
关于Oracle 体系结构请参考:Oracle实例和Oracle数据库(Oracle体系结构)
二、联机重做日志的规划管理
1.联机重做日志
记录了数据的所有变化(DML,DDL或管理员对数据所作的结构性更改等)
提供恢复机制(对于意外删除或宕机利用日志文件实现数据恢复)
可以被分组管理
2.联机重做日志组
由一个或多个相同的联机日志文件组成一个联机重做日志组
至少两个日志组,每组一个成员(建议每组两个成员,分散放开到不同的磁盘)
由LGWR后台进程同时将日志内容写入到一个组的所有成员
LGWR的触发条件
在事务提交的时候(COMMIT)
Redo Log Buffer 三分之一满
Redo Log Buffer 多于一兆的变化记录
在DBWn写入数据文件之前
3.联机重做日志成员
重做日志组内的每一个联机日志文件称为一个成员
一个组内的每一个成员具有相同的日志序列号(log sequence number),且成员的大小相同
每次日志切换时,Oracle服务器分配一个新的LSN号给即将写入日志的日志文件组
LSN号用于唯一区分每一个联机日志组和归档日志
处于归档模式的联机日志,LSN号在归档时也被写入到归档日志之中
4.日志文件的工作方式
日志文件采用按顺序循环写的方式
当一组联机日志组写满,LGWR则将日志写入到下一组,当最后一组写满则从第一组开始写入
写入下一组的过程称为日志切换
切换时发生检查点过程
检查点的信息同时写入到控制文件
5.联机日志文件的规划
总原则
分散放开,多路复用
日志所在的磁盘应当具有较高的I/O
一般日志组大小应满足自动切换间隔至少15-20分钟左右业务需求
建议使用rdo结尾的日志文件名,避免误删日志文件。如redo1.rdo,redo2.rdo
规划样例
Redo Log Group1 Redo Log Group2 Redo Log Group3
Member1 Member1 Member1 -->Physical Disk 1
Member2 Member2 Member2 -->Physical Disk 2
Member3 Member3 Member3 -->Physical Disk 3
6.日志切换和检查点切换
ALTER SYSTEM SWITCH LOGFILE; --强制手动切换
ALTER SYSTEM CHECKPOINT;
强制设置检查点间隔
ALTER SYSTEM SET FAST_START_MTTR_TARGET = n
7.添加日志文件组
ALTER DATABASE ADD LOGFILE [GROUP n]
('$ORACLE_BASE/oradata/u01/logn1.rdo',
'$ORACLE_BASE/oradata/u01/logn2.rdo')
SIZE mM;
8.添加日志成员
ALTER DATABASE ADD LOGFILE MEMBER
'$ORACLE_BASE/oradata/u01/logn1.rdo' TO GROUP 1,
'$ORACLE_BASE/oradata/u01/logn2.rdo' TO GROUP 2;
9.删除日志成员
不能删除组内的唯一一个成员
不能删除处于active 和current 状态组内的成员
删除处于active 和current 状态组内的成员,应使用日志切换使其处于INACTIVE状态后再删除
对于组内如果一个成员为NULL 值,一个为INVALID,且组处入INACTIVE,仅能删除INVALID状态成员
删除日志成员,物理文件并没有真正删除,需要手动删除
删除日志文件后,控制文件被更新
对于处于归档模式下的数据库,删除成员时确保日志已被归档,查看v$log视图获得归档信息
ALTER DATABASE DROP LOGFILE MEMBER '$ORACLE_BASE/oradata/u01/logn1.rdo'
10.删除日志组
一个实例至少需要两个联机日志文件组
活动或当前的日志组不能被删除
组内成员状态有NULL 值或INVALID状态并存,组不可删除
日志组被删除后,物理文件需要手动删除(对于非OMF)
ALTER DATABASE DROP LOGFILE GROUP n
11.日志的重定位及重命名
所需权限
ALTER DATABASE 系统权限
复制文件到目的位置操作系统权限(写权限)
CURRENT状态组内的成员不能被重命名
建议该行为之前备份数据库
重命名或重定位之后建议立即备份控制文件
重定位及重命名的两种方法
添加一个新成员到日志组,然后删除一个旧的成员
使用ALTER DATABASE RENAME FILE 命令(不区分归档与非归档模式)
复制联机日志文件到新路径:ho cp
执行ALTER DATABASE RENAME FILE '' TO ''
对于处于CURRENT状态的需要改名且不切换的情况下
办法是切换到MOUNT状态下再执行上述操作
12.清空日志文件组
ALTER DATABASE CLEAR LOGIFLE GROUP n
ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP n --使用unarchived 避免归档
13.日志周期循环及切换分析
Group 1 Group 2 Group 3
Current Inactive Inactive
---------- Log Switch -------------
Active Current Inactive
---------- Log Switch -------------
Active Active Current
---------- Log Switch -------------
Current Inactive Inactive
--Active 和Current 称之为在一个循环周期之内(按顺序写日志)
--Inactive 称为一个周期之外(一个新的循环)
--新一轮循环开始如在归档状态则先归档再清空,否则直接清空日志
--数据库启动时Active 和Current 状态的日志不能丢失,否则出错
14.日志的监视
查看日志视图中的物理日志文件是否存在、位置、大小等
SELECT 'ho cp '||member FROM v$logfile;
查看日志文件所处的磁盘空间是否足够
SQL> ho df -h
查看组内是否存在多个成员,如为单一成员应考虑增加日志成员
日志切换的间隔时间,应满足15-20分钟业务需求,如果切换间隔很短,应当增加日志文件的大小
增加方法,先删除日志组,再重建该组(对于current和active的需要切换再做处理)
--查看切换时间间隔(下面的示例中为手工切换的时间,不作考虑)
SQL> SELECT TO_CHAR(first_time,'yyyy-mm-dd hh24:mi:ss'),group# FROM v$log;
TO_CHAR(FIRST_TIME, GROUP#
------------------- ----------
2010-07-20 09:43:18 1
2010-07-19 22:44:30 2
2010-07-19 22:44:32 3
15.日志的异常处理(参照演示中9小节)
不一致的情况(启动时)
ALTER DATABASE CLEAR LOGFILE GROUP n
ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP n
三、与日志有关的动态性能视图
V$LOG
V$LOGFILE
V$LOG中STATUS的状态值
UNUSED: 从未对该联机日志写入任何内容,一般为新增加联机日志文件或是使用resetlog后的状态
CURRENT:当前重做日志文件,表示该重做日志文件为活动状态,能够被打开和关闭
ACTIVE:处于活动状态,不属于当前日志,崩溃恢复需要该状态,可用于块恢复,可能归档,也可能未归档
CLEARING:表示在执行alter database clear logfile命令后正将该日志重建为一个空日志,重建后状态变为unused
CLEARING_CURRENT:当前日志处于关闭线程的清除状态。如日志某些故障或写入新日志标头时发生I/O错误
INACTIVE:实例恢复不在需要联机重做文件日志组,可能归档也可能未归档
V$LOGFILE中STATUS的状态值
INVALID :表明该文件不可访问
STALE :表明文件内容不完全
DELETED : 表明该文件不再使用
NULL :表明文件正在使用
四、演示
--1.查看当前数据库的日志
SQL> SELECT * FROM v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- ---------
1 1 5 52428800 1 NO CURRENT 2758062 19-JUL-10
2 1 3 52428800 2 YES INACTIVE 2695010 16-JUL-10
3 1 4 104857600 2 YES INACTIVE 2716552 18-JUL-10
SQL> SELECT * FROM v$logfile ORDER BY group#;
GROUP# STATUS TYPE MEMBER IS_
---------- ------- ------- ------------------------------------------------------- ---
1 ONLINE /u01/app/oracle/oradata/orcl/redo01.log NO
2 STALE ONLINE /u01/app/oracle/oradata/orcl/redo02.log NO
2 STALE ONLINE /u01/app/oracle/oradata/orcl/redo2.log NO
3 STALE ONLINE /u01/app/oracle/oradata/orcl/redo03.log NO
3 STALE ONLINE /u01/app/oracle/oradata/orcl/redo3.log NO
--2.添加日志组
SQL> SELECT * FROM v$logfile;
GROUP# STATUS TYPE MEMBER IS_
---------- ------- ------- ------------------------------------------------------- ---
2 STALE ONLINE /u01/app/oracle/oradata/orcl/redo2.log NO
2 STALE ONLINE /u01/app/oracle/oradata/orcl/redo02.log NO
1 ONLINE /u01/app/oracle/oradata/orcl/redo01.log NO
3 STALE ONLINE /u01/app/oracle/oradata/orcl/redo3.log NO
3 STALE ONLINE /u01/app/oracle/oradata/orcl/redo03.log NO
4 ONLINE /u01/app/oracle/oradata/orcl/redo4.log NO
4 ONLINE /u01/app/oracle/oradata/orcl/redo04.log NO
--3.添加日志成员
SQL> ALTER DATABASE ADD LOGFILE MEMBER '/u01/app/oracle/oradata/orcl/redo1.log' TO GROUP 1;
Database altered.
SQL> SELECT * FROM v$logfile WHERE group# = 1 ;
GROUP# STATUS TYPE MEMBER IS_
---------- ------- ------- ------------------------------------------------------- ---
1 ONLINE /u01/app/oracle/oradata/orcl/redo01.log NO
1 INVALID ONLINE /u01/app/oracle/oradata/orcl/redo1.log NO
--4.删除日志成员
SQL> ALTER DATABASE DROP LOGFILE MEMBER '/u01/app/oracle/oradata/orcl/redo01.log';
ALTER DATABASE DROP LOGFILE MEMBER '/u01/app/oracle/oradata/orcl/redo01.log'
*
ERROR at line 1: --redo01.log处于NULL状态且该日志组为current状态不能删除
ORA-00362: member is required to form a valid logfile in group 1
ORA-01517: log member: '/u01/app/oracle/oradata/orcl/redo01.log'
SQL> ALTER DATABASE DROP LOGFILE MEMBER '/u01/app/oracle/oradata/orcl/redo04.log';
Database altered.
SQL> ALTER DATABASE DROP LOGFILE MEMBER '/u01/app/oracle/oradata/orcl/redo4.log';
ALTER DATABASE DROP LOGFILE MEMBER '/u01/app/oracle/oradata/orcl/redo4.log'
*
ERROR at line 1: --最后一个日志成员不能被删除
ORA-00361: cannot remove last log member /u01/app/oracle/oradata/orcl/redo4.log for group 4
--5.日志切换
SQL> SELECT * FROM v$log; --当前的日志组处于CURRENT状态
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- ---------
1 1 5 52428800 2 NO CURRENT 2758062 19-JUL-10
2 1 3 52428800 2 YES INACTIVE 2695010 16-JUL-10
3 1 4 104857600 2 YES INACTIVE 2716552 18-JUL-10
4 1 0 31457280 1 YES UNUSED 0
SQL> ALTER SYSTEM SWITCH LOGFILE; --进行日志切换
System altered.
SQL> SELECT * FROM v$log; --原来的日志组4的unused状态变为current状态
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- ---------
1 1 5 52428800 2 YES ACTIVE 2758062 19-JUL-10
2 1 3 52428800 2 YES INACTIVE 2695010 16-JUL-10
3 1 4 104857600 2 YES INACTIVE 2716552 18-JUL-10
4 1 6 31457280 1 NO CURRENT 2759277 19-JUL-10
SQL> ALTER SYSTEM SWITCH LOGFILE; --再次进行日志切换
System altered.
SQL> SELECT * FROM v$log; --日志组1变为current且组4变为active 状态
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- ---------
1 1 5 52428800 2 YES ACTIVE 2758062 19-JUL-10
2 1 7 52428800 2 NO CURRENT 2759293 19-JUL-10
3 1 4 104857600 2 YES INACTIVE 2716552 18-JUL-10
4 1 6 31457280 1 YES ACTIVE 2759277 19-JUL-10
由上可得知,在日志切换时对于unused组将优先作为下一组切换对象
--再次删除redo01.log还是收到错误提示
SQL> ALTER DATABASE DROP LOGFILE MEMBER '/u01/app/oracle/oradata/orcl/redo01.log';
ALTER DATABASE DROP LOGFILE MEMBER '/u01/app/oracle/oradata/orcl/redo01.log'
*
ERROR at line 1:
ORA-00362: member is required to form a valid logfile in group 1
ORA-01517: log member: '/u01/app/oracle/oradata/orcl/redo01.log'
SQL> ALTER SYSTEM SWITCH LOGFILE; --再次进行日志切换
System altered.
SQL> SELECT * FROM v$log; --group1变为inactive
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- ---------
1 1 5 52428800 2 YES INACTIVE 2758062 19-JUL-10
2 1 7 52428800 2 YES ACTIVE 2759293 19-JUL-10
3 1 8 104857600 2 NO CURRENT 2759420 19-JUL-10
4 1 6 31457280 1 YES INACTIVE 2759277 19-JUL-10
--反复多切几次日志之后redo01.log被成功删除
SQL> ALTER DATABASE DROP LOGFILE MEMBER '/u01/app/oracle/oradata/orcl/redo01.log';
Database altered.
--6.删除日志组(CURRENT和ACTIVE状态的不能被删除)
SQL> SELECT * FROM v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- ---------
1 1 9 52428800 1 YES ACTIVE 2759487 19-JUL-10
2 1 11 52428800 2 NO CURRENT 2759502 19-JUL-10
3 1 8 104857600 2 YES ACTIVE 2759420 19-JUL-10
4 1 10 31457280 1 YES ACTIVE 2759499 19-JUL-10
SQL> ALTER DATABASE DROP LOGFILE GROUP 4;
ALTER DATABASE DROP LOGFILE GROUP 4
*
ERROR at line 1: --处于活动状态的group4 用于灾难恢复,不能被删除
ORA-01624: log 4 needed for crash recovery of instance orcl (thread 1)
ORA-00312: online log 4 thread 1: '/u01/app/oracle/oradata/orcl/redo4.log'
SQL> ALTER SYSTEM SWITCH LOGFILE; --进行日志切换
System altered.
SQL> /
System altered.
SQL> SELECT * FROM v$log; --group 4的状态变为inactvie
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- ---------
1 1 13 52428800 1 NO CURRENT 2759720 19-JUL-10
2 1 11 52428800 2 YES ACTIVE 2759502 19-JUL-10
3 1 12 104857600 2 YES ACTIVE 2759718 19-JUL-10
4 1 10 31457280 1 YES INACTIVE 2759499 19-JUL-10
SQL> ALTER DATABASE DROP LOGFILE GROUP 4; --成功删除group 4
Database altered.
SQL> ho ls /u01/app/oracle/oradata/orcl/redo*
/u01/app/oracle/oradata/orcl/redo01.log /u01/app/oracle/oradata/orcl/redo1.log
/u01/app/oracle/oradata/orcl/redo02.log /u01/app/oracle/oradata/orcl/redo2.log
/u01/app/oracle/oradata/orcl/redo03.log /u01/app/oracle/oradata/orcl/redo3.log
/u01/app/oracle/oradata/orcl/redo04.log /u01/app/oracle/oradata/orcl/redo4.log
SQL> ho rm /u01/app/oracle/oradata/orcl/redo04.log --删除物理文件
SQL> ho rm /u01/app/oracle/oradata/orcl/redo4.log --删除物理文件
--7.日志的重定位及重命名(仅演示ALTER DATABASE RENAME FILE 命令)
SQL> SELECT name,log_mode FROM v$database;
NAME LOG_MODE
--------- ------------
ORCL ARCHIVELOG
SQL> SELECT * FROM v$logfile ORDER BY group#;
GROUP# STATUS TYPE MEMBER IS_
---------- ------- ------- ------------------------------------------------------- ---
1 ONLINE /u01/app/oracle/oradata/orcl/redo01.log NO
2 ONLINE /u01/app/oracle/oradata/orcl/redo02.log NO
2 ONLINE /u01/app/oracle/oradata/orcl/redo2.log NO
3 STALE ONLINE /u01/app/oracle/oradata/orcl/redo03.log NO
3 STALE ONLINE /u01/app/oracle/oradata/orcl/redo3.log NO
SQL> ho cp /u01/app/oracle/oradata/orcl/redo01.log /u01/app/oracle/oradata/redo01.rdo
SQL> ALTER DATABASE RENAME FILE '/u01/app/oracle/oradata/orcl/redo01.log'
2 TO '/u01/app/oracle/oradata/redo01.rdo';
Database altered.
SQL> SELECT * FROM v$logfile WHERE group# = 1;
GROUP# STATUS TYPE MEMBER IS_
---------- ------- ------- ------------------------------------------------------- ---
1 ONLINE /u01/app/oracle/oradata/redo01.rdo NO
--8.清空日志文件组(只有非active 和非current状态的组才能被清空)
SQL> SELECT * FROM v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- ---------
1 1 13 52428800 1 YES ACTIVE 2759720 19-JUL-10
2 1 14 52428800 2 NO CURRENT 2761383 19-JUL-10
3 1 12 104857600 2 YES INACTIVE 2759718 19-JUL-10
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 1;
ALTER DATABASE CLEAR LOGFILE GROUP 1
*
ERROR at line 1: --active 状态不能被清空
ORA-01624: log 1 needed for crash recovery of instance orcl (thread 1)
ORA-00312: online log 1 thread 1: '/u01/app/oracle/oradata/redo1.rdo'
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 2;
ALTER DATABASE CLEAR LOGFILE GROUP 2
*
ERROR at line 1: --current 状态不能被清空
ORA-01624: log 2 needed for crash recovery of instance orcl (thread 1)
ORA-00312: online log 2 thread 1: '/u01/app/oracle/oradata/orcl/redo2.log'
ORA-00312: online log 2 thread 1: '/u01/app/oracle/oradata/orcl/redo02.log'
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 3;
Database altered.
SQL> SELECT * FROM v$log; --group 3被清空后状态变为unused
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- ---------
1 1 13 52428800 1 YES INACTIVE 2759720 19-JUL-10
2 1 14 52428800 2 NO CURRENT 2761383 19-JUL-10
3 1 0 104857600 2 YES UNUSED 2759718 19-JUL-10
--9.日志异常处理
--启动时提示日志不一致
SQL> startup
ORACLE instance started.
Total System Global Area 251658240 bytes
Fixed Size 1218796 bytes
Variable Size 83887892 bytes
Database Buffers 163577856 bytes
Redo Buffers 2973696 bytes
Database mounted.
ORA-00341:log 1 of thread 1,wrong log # in header
ORA-00312:online log 1 thread 1:'/u01/app/oracle/oradata/orcl/redo1a.rdo'
ORA-00312:online log 1 thread 1:'/u01/app/oracle/oradata/orcl/redo1b.rdo'
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 1;
Database altered.
SQL> ALTER DATABASE OPEN;
Database opened.
--日志文件丢失(非current状态日志组)
SQL> startup
ORACLE instance started.
Total System Global Area 251658240 bytes
Fixed Size 1218796 bytes
Variable Size 88082196 bytes
Database Buffers 159383552 bytes
Redo Buffers 2973696 bytes
Database mounted.
ORA-00313: open failed for members of log group 1 of thread 1
ORA-00312: online log 1 thread 1: '/u01/app/oracle/oradata/orcl/redo1a.rdo'
ORA-00312: online log 1 thread 1: '/u01/app/oracle/oradata/orcl/redo1b.rdo'
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 1;
Database altered.
SQL> ALTER DATABASE OPEN;
Database altered.
--日志文件丢失(current状态日志组)
SQL> startup
ORACLE instance started.
Total System Global Area 251658240 bytes
Fixed Size 1218796 bytes
Variable Size 83887892 bytes
Database Buffers 163577856 bytes
Redo Buffers 2973696 bytes
Database mounted.
ORA-00313: open failed for members of log group 3 of thread 1
ORA-00312: online log 3 thread 1: '/u01/app/oracle/oradata/orcl/redo3a.rdo'
ORA-00312: online log 3 thread 1: '/u01/app/oracle/oradata/orcl/redo3b.rdo'
--查看告警日志
SQL> ho tail -n 30 /u01/app/oracle/admin/orcl/bdump/alert_orcl.log
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
ORA-00312: online log 3 thread 1: '/u01/app/oracle/oradata/orcl/redo3a.rdo'
ORA-27037: unable to obtain file status
linux Error: 2: No such file or directory
Additional information: 3
Tue Jul 20 10:45:58 2010
Errors in file /u01/app/oracle/admin/orcl/bdump/orcl_lgwr_4112.trc:
ORA-00313: open failed for members of log group 3 of thread 1
ORA-00312: online log 3 thread 1: '/u01/app/oracle/oradata/orcl/redo3b.rdo'
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
ORA-00312: online log 3 thread 1: '/u01/app/oracle/oradata/orcl/redo3a.rdo'
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
Tue Jul 20 10:45:58 2010
ARC0: STARTING ARCH PROCESSES
Tue Jul 20 10:45:58 2010
ARC1: Becoming the 'no FAL' ARCH
ARC1: Becoming the 'no SRL' ARCH
Tue Jul 20 10:45:58 2010
ARC2: Archival started
ARC0: STARTING ARCH PROCESSES COMPLETE
ARC0: Becoming the heartbeat ARCH
ARC2 started with pid=18, OS id=4137
Tue Jul 20 10:45:58 2010
ORA-313 signalled during: ALTER DATABASE OPEN...
--查看物理日志文件是否存在
SQL> ho ls /u01/app/oracle/oradata/orcl/redo3a.rdo
ls: /u01/app/oracle/oradata/orcl/redo3a.rdo: No such file or directory
SQL> ho ls /u01/app/oracle/oradata/orcl/redo3b.rdo
ls: /u01/app/oracle/oradata/orcl/redo3b.rdo: No such file or directory
--尝试使用清空日志组命令
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 3;
ALTER DATABASE CLEAR LOGFILE GROUP 3
*
ERROR at line 1: --系统处于非归档模式,且group 3状态为CURRENT
ORA-00350: log 3 of instance orcl (thread 1) needs to be archived
ORA-00312: online log 3 thread 1: '/u01/app/oracle/oradata/orcl/redo3a.rdo'
ORA-00312: online log 3 thread 1: '/u01/app/oracle/oradata/orcl/redo3b.rdo'
--尝试使用不归档清空日志
SQL> ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP 3;
ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP 3
*
ERROR at line 1:
ORA-00313: open failed for members of log group 3 of thread 1
ORA-00312: online log 3 thread 1: '/u01/app/oracle/oradata/orcl/redo3b.rdo'
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
ORA-00312: online log 3 thread 1: '/u01/app/oracle/oradata/orcl/redo3a.rdo'
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
--使用带控制文件的介质恢复
SQL> RECOVER DATABASE USING BACKUP CONTROLFILE;
ORA-00279: change 2835232 generated at 07/20/2010 10:40:23 needed for thread 1
ORA-00289: suggestion : /u01/app/oracle/flash_recovery_area/ORCL/archivelog/2010_07_20/o1_mf_1_39_%u_.arc
ORA-00280: change 2835232 for thread 1 is in sequence #39
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
ORA-00308: cannot open archived log'/u01/app/oracle/flash_recovery_area/ORCL/archivelog/2010_07_20/o1_mf_1_39_%u_.arc'
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
--使用resetlogs选项打开数据库
SQL> ALTER DATABASE OPEN RESETLOGS;
Database altered.
SQL> SELECT * FROM v$log; --系统重建group 3
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM
---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- ---------
1 1 2 31457280 2 NO CURRENT 2835234 20-JUL-10
2 1 1 31457280 2 YES INACTIVE 2835233 20-JUL-10
3 1 0 31457280 2 YES UNUSED 0
SQL> SELECT * FROM v$logfile; --为group 3增加了两个成员redo3a.rdo ,redo3b.rdo
GROUP# STATUS TYPE MEMBER IS_
---------- ------- ------- ------------------------------------------------------- ---
2 ONLINE /u01/app/oracle/oradata/orcl/redo2a.rdo NO
2 ONLINE /u01/app/oracle/oradata/orcl/redo2b.rdo NO
1 ONLINE /u01/app/oracle/oradata/orcl/redo1a.rdo NO
3 ONLINE /u01/app/oracle/oradata/orcl/redo3a.rdo NO
3 ONLINE /u01/app/oracle/oradata/orcl/redo3b.rdo NO
1 ONLINE /u01/app/oracle/oradata/orcl/redo1b.rdo NO
对于CURRENT组的也可以使用隐藏参数来解决
步骤:
alter system set "_allow_resetlogs_corruption" = true scope = spfile;
recover database using bakcup controlfile;
alter database open resetlogs;
shutdown immediate;
startup mount;
alter database open resetlogs;
alter system reset "_allow_resetlogs_corruption" scope = spfile sid = '*'
对于归档模式下的日志文件丢失,同样可以按上述步骤处理
联机重做日志文件概念
联机日志文件又叫重做日志文件,记录了对数据库修改的信息,包括用户对数据修改和数据库管理员对数据库结构的修改。它主要用于在发生故障的时候和数据库备份文件配合恢复数据库,一般发生故障有2个情况:一个是介质损坏另外一个是用户误操作。每个数据库至少有两个日志文件组,每组至少包含1个或者多个日志成员,这里要多个日志成员的原因是防止日志文件组内某个日志文件损坏后及时提供备份,所以同一组的日志成员一般内容信息相同,但是存放位置不同。
在Oracle数据库中,执行数据修改操作后,并不是马上写入数据文件,而是首先生成重做信息,并写入SGA中的一块叫LOG_BUFFER的固定区域,LOG_BUFFER的空间并不是无限大,事实上它非常小,一般设置在3~5MB左右。LOG_BUFFER有一定的触发条件,当满足触发条件后,会有相应进程将LOG_BUFFER中的内容写入一个特定类型的文件,就是传说中的联机重做日志文件。
联机重做日志文件是循环使用的(见下图)。当第一个日志文件达到一定数量时,就会停止写入,而转向第二个日志文件,第二个满转向第三个日志文件.第三个满就向第一个日志文件写入.而第一个日志文件有没有自动备份就涉及到归档或者不归档的问题.当数据库自动对原来的日志文件进行备份的话就叫归档模式,不需要对数据库进行自动备份就叫非归档模式.
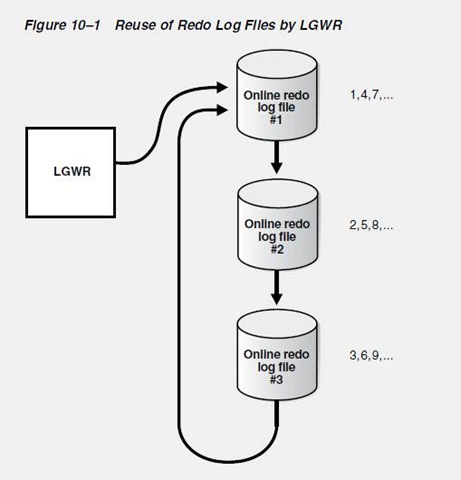
那么什么情况触发LGWR进程写日志文件呢?以下情况将触发LGWR进程写操作:
1).当commit事务发生
2).当redo log buffer存储达到1/3
3).当重做日志缓冲区有超过一个兆字节的更改记录
4).在DBWN将buffer cache修改过的数据块的信息写入到数据文件之前
触发CHECK POINT事件的情况:
1).每次日志切换时。
2).实例通过normal,transactional,immediate选项关闭时
3).通过设置初始化参数FAST_START_MTTR_TARGET强制发生
4) .数据库管理员手工设置ALTER SYSTEM CHECKPOINT、 ALTER TABLESPACE, DATAFILE OFFLINE时。
5).使用alter tablespace[OFFLINE NORMAL|READ ONLY|BEGIN BACKUP] 语句导致指定数据文件发生检查点
非归档模式只能做冷备份,归档模式可以做热备份并且可以做增量备份和部分恢复.
在非归档模式下执行数据库备份时,基本上数据管理员通过重做日志文件不能够恢复全部的数据,所以必须备份所有的数据文件和控制文件,而且必须使用 shutdown normal等命令关闭数据库.
而在归档模式下.当出现介质损坏(硬盘损坏或者误删数据文件)或者例程失败(服务器断电),数据库管理员可以通过归档日志来防止数据丢失,而非归档模式只能应对instance失败.在归档模式下,数据库处于open状态,仍然可以备份数据库,而不影响数据库的正常使用.不仅可以做完全恢复而且可以将数据库恢复到特定的点.
非归档模式和归档模式各有各的优点,选择时可以参考:1,数据库中数据变化的频繁程度;2,企业对数据丢失的态度;3,数据库是否需要7x24运行,因为非归档模式需要关闭数据库才能进行备份.
查看归档模式
ORACLE数据库拥有2种归档模式,ARCHIVELOG和NOARCHIVELOG。可以通过下面方式查看数据库的归档模式

(1): SELECT NAME, LOG_MODE FROM V$DATABASE (2): SQL> archive log list 数据库日志模式 存档模式 自动存档 启用 存档终点 USE_DB_RECOVERY_FILE_DEST 最早的联机日志序列 106 下一个存档日志序列 108 当前日志序列 108 SQL> archive log list Database log mode No Archive Mode Automatic archival Disabled Archive destination USE_DB_RECOVERY_FILE_DEST Oldest online log sequence 2861 Current log sequence 2866
日志模式切换
非归档模式切换归档模式
| 1、关闭服务: SQL> SHUTDOWN IMMEDIATE; 2、不加载数据文件(只加载控制文件和日志文件)启动服务: SQL> STARTUP MOUNT; 3、查看日志归档模式: SQL> ARCHIVE LOG LIST 数据库日志模式 非存档模式 自动存档 禁用 存档终点 USE_DB_RECOVERY_FILE_DEST 最早的联机日志序列 163 当前日志序列 165 4、配置数据库启用日志归档模式 SQL> ALTER DATABASE ARCHIVELOG; 数据库已更改。 5、加载并打开数据文件: SQL> ALTER DATABASE OPEN; 数据库已更改。 6、再次查看日志归档模式 SQL> ARCHIVE LOG LIST 数据库日志模式 存档模式 自动存档 启用 存档终点 USE_DB_RECOVERY_FILE_DEST 最早的联机日志序列 163 下一个存档日志序列 165 当前日志序列 165 SQL> ARCHIVE LOG START 已处理的语句 7:修改参数LOG_ARCHIVE_START SQL> ALTER SYSTEM SET LOG_ARCHIVE_START=TRUE SCOPE=SPFILE; 系统已更改。 归档模式切换到非归档模式 1、关闭服务 SQL> SHUTDOWN IMMEDIATE; 2、启动服务(不加载数据文件) SQL> STARTUP MOUNT; 3、设置数据库为非归档模式 SQL> ALTER DATABASE NOARCHIVELOG; 数据库已更改。 4、加载并打开数据文件 SQL> ALTER DATABASE OPEN; 数据库已更改。 日志切换和检查点切换 SQL>ALTER SYSTEM SWITCH LOGFILE; 日志切换就是停止写当前日志组,转而写另外一个新的日志组、系统可以自动切换,也可以手工切换。当发生SWITCH LOGIFLE时,系统会在后台完成CHECKPOINT的操作。CHECKPOINT是一个事件,它用于减少instant recovery的时间.当CHECKPOINT发生时,它会触发DBWR进程,把database buffer中变化了的数据写入数据文件,同时chkp进程更新control file和datafile header,以使它们保持一致。检查点其实是一个后台进程,用来保证所有修改过的数据库缓冲区的东西都写入数据库文件。它由参数LOG_CHECKPOINT_TIMEOUT和LOG_CHECKPOINT_INTERVAL来决定。检查点完成后,系统将更新数据库头和控制文件,也保证数据库的同步。这里主要体现在一个系统改变号上SCN(也叫检查点号)。它分别出现在v$log表的FIRST_CHANGE#列和V$DATAFILE的CHECKPOINT_CHANGE#列还有V$DATABASE的CHECKPOINT_CHANGE#上。 只要说明三个值相同,那么数据库就没有不同步的现象。否则就要进行介质恢复。这里可以通过日志切换改变新的检验点号。当然引起SCN改变的情况还有很多。 SQL>ALTER SYSTEM CHECKPOINT; 强制设置检查点间隔 ALTER SYSTEM SET FAST_START_MTTR_TARGET = n 联机日志文件的规划 联机日志文件的规划原则如下: 1:分散放开,多路复用。一般会将同一组的不同日志成员文件放到不同的磁盘或不同的裸设备上。以提高安全性。 2:把重做日志放在速度最快的硬盘上(即:日志所在的磁盘应当具有较高的I/O),一般会将日志文件放在裸设备上。 3:把重做日志文件设为合理大小:例如,增大日志文件大小可以加快一些大型的INSERT、UPDATE、DELETE操作,也能降低日志文件切换频率。减少一些日志等待事件。一般根据具体业务情况有所不同。一般日志组大小应满足自动切换间隔至少15-20分钟左右业务需求 4:ORACLE推荐,同一个重做日值组下的所有重做日志文件大小、成员个数一致. 联机重做日志状态 日志文件组的状态一般有INACTIVE、ACTIVE、CURRENT、UNUSED、CLEARING、CLEARING_CURRNT等六种状态: SQL> SELECT STATUS FROM V$LOG; UNUSED : 表示该联机重做日志文件组对应的文件还从未被写入过数据,通常刚刚创建的联机重做日志文件组会显示成这一状态。当日志切换到这一组时,就会改变状态。 CURRENT : 表示当前正在使用的日志文件组。该联机重做日志组是活动的。当前Oracle数据库正在使用的联机重做日志文件组。 ACTIVE : 表示该组是活动的但不是当前组,实例恢复时需要这组日志。如果处于这一状态,表示虽然当前并未使用,不过该文件中内容尚未归档,或者文件中的数据没有全部写入数据文件,一旦需要实例恢复,必须借助该文件中保存的内容。 INACTIVE: 表示实例恢复已不再需要这组联机重做日志组了。表示对应的联机重做日志文件中的内容已被妥善处理,该组联机重做日志当前处于空闲状态。 CLEARING:表示该组重做日志文件正被重建(重建后该状态会变成UNUSED)。 CLEARING_CURRENT:表示该组重做日志重建时出现错误。 日志文件的状态有STALE,INVALID 、DELETED、空白 四种状态。可以通过下面语句查看 SELECT STATUS FROM V$LOGFILE INVALID : 表示该文件是不可以被访问的。 STALE : 表示该文件中的内容是不完全的。 空白 : 表示该文件正在使用。 DELETED : 表示该文件已不再有用了。 ARCHIVED列值为YES表示已经归档,NO表示未归档。 SEQUENCE列值表示日志序列号,每进行一次日志切换就+1。 创建新的日志组 ALTER DATABASE ADD LOGFILE GROUP 1('/oradata/redo01_1.log', '/oradata/redo01_2.log') SIZE 8G REUSE; 一开始增加的日志文件,日志序列为0,状态为UNUSED,因为没有使用过,进行切换后,就可以正常使用了。 删除旧的日志组 ALTER DATABASE DROP LOGFILE GROUP 1; 注意事项: 1)执行删除日志组命令后,其实只是在数据字典中删掉了对于日志信息。你查看对应的日志文件,你会发现日志文件还在,只有手动删除日志文件,才能真正的删除日志文件。 2)不能删除仅有的2个文件组; 例如,数据库只有两组重做日志文件,删除其中一组ALTER DATABASE DROP LOGFILE GROUP 2; ORA-01567: 删除日志 2 时将为实例 orcl (线程 1) 保留两个以下的日志文件 ORA-00312: 联机日志 2 线程 1: 'E:\APP\KERRY\ORADATA\ORCL\REDO02.LOG' 3)不能删除正在活动的文件组(即CURRENT、ACTIVE状态的日志文件); Windows平台: Linux平台:
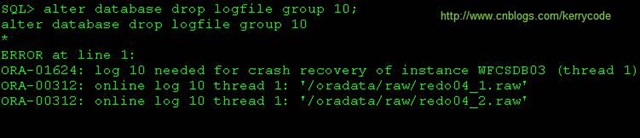
SQL> alter database drop logfile group 10; ERROR at line 1: ORA-01623: log 10 is current log for instance WFCSDB03 (thread 1) - cannot drop ORA-00312: online log 10 thread 1: '/oradata/raw/redo04_1.raw' ORA-00312: online log 10 thread 1: '/oradata/raw/redo04_2.raw'
SQL> alter system switch logfile; System altered. SQL> select * from v$log; GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIM ---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- --------- 1 1 265 1.0733E+10 2 NO INACTIVE 54310652 08-AUG-12 7 1 263 4194304000 2 NO INACTIVE 54310551 08-AUG-12 8 1 264 4194304000 2 NO INACTIVE 54310641 08-AUG-12 9 1 266 4194304000 2 NO INACTIVE 54310659 08-AUG-12 10 1 267 4194304000 2 NO ACTIVE 54310666 08-AUG-12 11 1 268 4194304000 2 NO CURRENT 56534648 09-AUG-12 12 1 262 4194304000 2 NO INACTIVE 54310376 08-AUG-12 7 rows selected. SQL> alter database drop logfile group 10; alter database drop logfile group 10 * ERROR at line 1: ORA-01624: log 10 needed for crash recovery of instance WFCSDB03 (thread 1) ORA-00312: online log 10 thread 1: '/oradata/raw/redo04_1.raw' ORA-00312: online log 10 thread 1: '/oradata/raw/redo04_2.raw'
4)不能删除当前组的成员,当日志组只有一个成员时,不能删除日志组成员。 5)不能删除还没有归档的文件组。 增加日志组文件 ALTER DATABASE ADD LOGFILE MEMBER 'E:\APP\KERRY\ORADATA\ORCL\REDO011.LOG' TO GROUP 1 删除日志组文件 |
| 不能删除日志组中唯一的日志文件,可以使用删除组的方法直接删除组;不能删除没有归档或者还在活动的日志; ALTER DATABASE DROP LOGFILE MEMBER 'E:\APP\KERRY\ORADATA\ORCL\REDO011.LOG' 重命名日志组文件 ALTER DATABASE RENAME FILE 'E:\APP\KERRY\ORADATA\ORCL\REDO02.LOG' TO 'D:\REDO02.LOG'; 注意2点: 一不能移动正在使用的日志文件,否则执行脚本会报如下错误: 二确保执行命令前把目标文件已经移动到新目录下了,否则会报如下错误: ORA-01511:重命名日志/数据文件时出错 ORA-01512:重命名日志文件E:\APP\KERRY\ORADATA\ORCL\REDO02.LOG出错,未找到新文件D:\REDO02.LOG ORA-27041: 无法打开文件。 |




清空日志文件数据
清空是说删除日志文件的内容。主要用于数据库无法进行有效恢复的时候。比如标识为current的日志文件组所有文件都坏了等。只有非active 和非current状态的组才能被清空
ALTER DATABASE CLEAR LOGFILE 'XXX\XXX\XX.LOG'; ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP NUMBER;
查询日志组相关信息
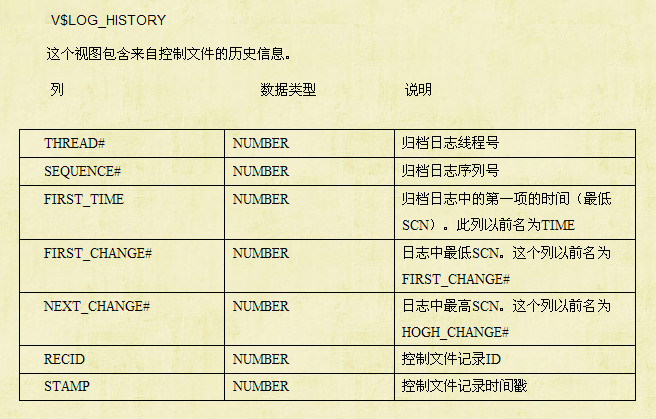
下面是重做日志相关的数据字典
SELECT * FROM V$LOG; SELECT * FROM V$LOGFILE; SELECT * FROM V$ARCHIVED_LOG; SELECT * FROM V$RECOVER_FILE SELECT * FROM V$LOG_HISTORY; SELECT * FROM V$LOGHIST;
--查看闪回日志使用状况
SELECT * FROM V$FLASH_RECOVERY_AREA_USAGE;
--查看日志组切换时间间隔
SELECT N.RECID AS RECID , N.FIRST_TIME AS FIRST_TIME , M.FIRST_TIME AS END_TIME , ROUND((M.FIRST_TIME - N.FIRST_TIME) * 24 * 60, 2)AS MINUTES FROM V$LOG_HISTORY M, V$LOG_HISTORY N WHERE M.RECID = N.RECID + 1 ORDER BY M.RECID
【体系结构】 Oracle物理结构之Redo Log
原文地址:http://blog.csdn.net/yujin2010good/article/details/7737581
一、重做日志文件的作用:
1、 记录所有数据的改变
2、 提供恢复机制
3、 组方式管理(最少两组,默认为3组,每组一个重做日志文件, oracle官方建议,所有的每组重做日志文件大小最好相同;当然如果是为重做日志文件组添加成员的时候不能指定大小,因为每个重做日志文件相互冗余,所以必须一致)
二、重做日志文件状态
通过lgwr写到日志文件里面
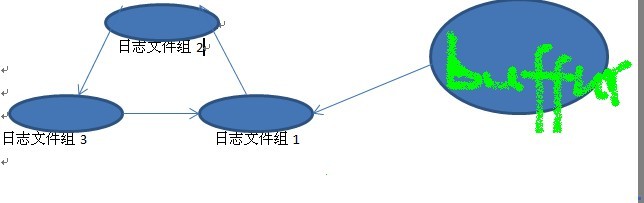
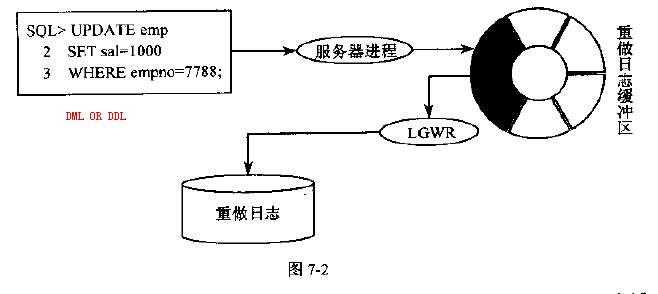
日志组1写满了,就会切换到日志组2,然后到3;3再到1,循环使用。反正日志组是不停的工作。
重做日志文件一般具有4种状态(也可以分为6种)
1、 unused:说明此重做日志文件组没被用过
2、 current:说明是当前重做日志组,lgwr正在写
3、 active:说明此重做日志文件组刚写完,记录在重做日志文件组中的事务所造成的数据块的改变,没有完全从缓冲区写入到数据文件,重做日志文件组属于这种状态,是不允许被覆盖的,一旦写完成,就变问inactive状态。
4、 inactive:说明记录在重做日志文件组中的事务所造成的数据块的改变,已经从缓冲区写入到数据文件,这种状态允许被覆盖。
上面4中状态是重做日志文件常见的状态,下面两种状态是在重做日志组损坏或者特殊情况下的状态。
5、clearing:说明该重做日志文件正被重建(重建后状态变为unused)
6、clearing_cyrrent:说明此重做日志文件重建是出现错误
下面是日志大小设置问题
日志文件设置大小问题,值得我们思考
v$log_history 这个动态视图查询日志切换的频率,根据这个频率来判断日志的大小是否合适
SQL> desc v$log_history;
Name Null? Type
----------------------------------------- -------- ----------------------------
RECID NUMBER
STAMP NUMBER
THREAD# NUMBER
SEQUENCE# NUMBER
FIRST_CHANGE# NUMBER
FIRST_TIME DATE
NEXT_CHANGE# NUMBER
RESETLOGS_CHANGE# NUMBER
RESETLOGS_TIME DATE

日志组空间太小的话,第一会导致dbwr写的频率增加,增加了i/o;第二会造成事务的等待,延长事务周期,导致数据库假死,后果严重。
如果太大的话,记录的事务多了,这时日志文件损坏,丢失数据就会很多;如果发生崩溃,那么redo的时间会很长。(原因:数据在修改时不是直接写入datafile,而是操作记录在redo log,当ckpt发生,他才会从redo log读取已经修改的数据,写入datafile,而要想让他写入datafile的条件之一就是日志切换,如果不考虑其他条件,只有等日志切换时,才会写入datafile,一般情况下没事,但是发生日志损坏)
还有要考虑业务的繁忙程度,按照最忙的时候去设置日志的大小
总之一句话要保证lgwr有可写的日志组去写日志。按照官方建议,日志切换时间一般在10-15分钟比较适合
三、下面是一些基本概念
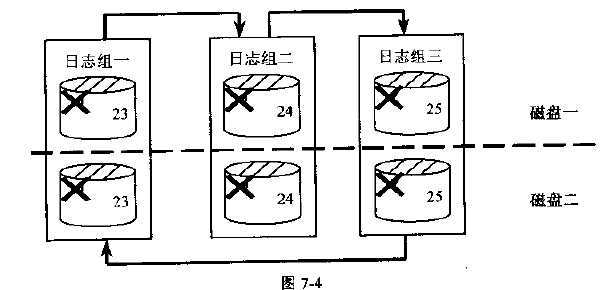
1、重做日志组(Redo Log Group)
日志组由一组完全相同的重做日志文件组成,每个日志组至少包含一个重做日志文件。如果一个日志组包含多个重做日志文件,后台进程LGWR会将相同的事务变化写入到同一个日志组的各个重做日志文件中。日志组汇总的每个重做日志文件都被称为日志成员,同一个日志组中所有日志成员都具有相同的日志序列号和尺寸。
2、重做日志条目(Redo Entry)
重做记录,由一组变化向量组成,这些变化向量包含表块变化(快位置、变化数据)、UNDO块变化和UNDO事务表的变化。
3、lgwr发生的条件
http://blog.csdn.net/yujin2010good/article/details/7709120
LGWR,用于将重做日志缓冲区所记载的全部内容写入到重做日志文件中。
Oracle 总是“先日志后修改”(先记载变化然后修改数据);
在DBWR工作之前,LGWR首先将事务变化写入到重做日志。
LGWR工作触发条件:
1、提交事务(commit)
2、每隔3秒钟
3、当重做日志信息超过1M
4、重做日志缓冲区超过1/3满
4、SCN(System Change Number)
SCN用于标识数据变化的唯一标识号,其数值顺序递增。执行事务操作时,系统会为每个事务变化生成相应的SCN.
基本上是发生dml操作时scn+1,正常关闭或者commit时也scn+1
5、日志序列号
日志序列号是重做日志的使用标识号,其数值也是循序递增的,当进行日志切换时,日志序列会自动增一,并将该信息写入到控制文件中去。
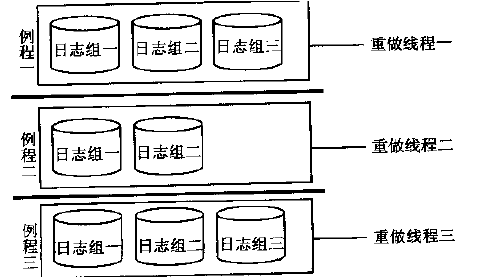
6、重做线程(Redo Thread)
重做线程由一组相关的重做日志组成。对于单实例的数据库系统来说,只有一个重做线程,而对于RAC(Real Application Cluster)来说,多个实例会同时访问数据库,并 且每个实例都有独立的重做线程。
7、日志切换
日志切换至后台进程LGWR停止写一个日志组,并开始写另一个日志组的事件,默认情况下,当日志组写满后,后台进程LGWR会自动进行日志切换。
当日志切换时,当前日志序列号会自动递增
也有手工切换日志
SQL> alter system switch logfile;
System altered.
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARC
---------- ---------- ---------- ---------- ---------- ---------- ---
STATUS FIRST_CHANGE# FIRST_TIM NEXT_CHANGE# NEXT_TIME
---------------- ------------- --------- ------------ ---------
1 1 10 52428800 512 1 YES
ACTIVE 1137238 08-JUL-12 1139309 08-JUL-12
2 1 11 52428800 512 1 NO
CURRENT 1139309 08-JUL-12 2.8147E+14
3 1 9 52428800 512 1 YES
INACTIVE 1132531 08-JUL-12 1137238 08-JUL-12
SQL> alter system switch logfile;
System altered.
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARC
---------- ---------- ---------- ---------- ---------- ---------- ---
STATUS FIRST_CHANGE# FIRST_TIM NEXT_CHANGE# NEXT_TIME
---------------- ------------- --------- ------------ ---------
1 1 10 52428800 512 1 YES
ACTIVE 1137238 08-JUL-12 1139309 08-JUL-12
2 1 11 52428800 512 1 YES
ACTIVE 1139309 08-JUL-12 1139367 08-JUL-12
3 1 12 52428800 512 1 NO
CURRENT 1139367 08-JUL-12 2.8147E+14
SQL> alter system archive log current;(手动归档)
System altered.
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES BLOCKSIZE MEMBERS ARC
---------- ---------- ---------- ---------- ---------- ---------- ---
STATUS FIRST_CHANGE# FIRST_TIM NEXT_CHANGE# NEXT_TIME
---------------- ------------- --------- ------------ ---------
1 1 13 52428800 512 1 NO
CURRENT 1139443 08-JUL-12 2.8147E+14
2 1 11 52428800 512 1 YES
ACTIVE 1139309 08-JUL-12 1139367 08-JUL-12
3 1 12 52428800 512 1 YES
ACTIVE 1139367 08-JUL-12 1139443 08-JUL-12
日志切换是,chpt发出checkpoint,然后促使scn写入控制文件和数据文件头,lgwr写完之后,dbwr开始把缓冲区脏数据写入数据文件。
当数据块处于归档模式时,日志切换时促使后台进程arch讲日志内容保存到归档日志
如下:
# pwd
/oracle/products/diag/rdbms/wolf/wolf/alert
# ls
log.xml
# tail -f log.xml
Completed checkpoint up to RBA [0xd.2.10], SCN: 1139443
<msg time="2012-07-08T21:35:06.308-05:00" org_id="oracle" comp_id="rdbms"
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module=''
pid='6160592'>
Incremental checkpoint up to RBA [0xd.273.0], current log tail at RBA [0xd.2aa.0]
<msg time="2012-07-08T21:44:00.575-05:00" org_id="oracle" comp_id="rdbms"
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module='sqlplus@oracle (TNS V1-V3)'
pid='14680092'>
ALTER SYSTEM ARCHIVE LOG
<msg time="2012-07-08T21:44:00.713-05:00" org_id="oracle" comp_id="rdbms"
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module=''
pid='6357218'>
<txt>Beginning log switch checkpoint up to RBA [0xe.2.10], SCN: 1140448
<msg time="2012-07-08T21:44:00.713-05:00" org_id="oracle" comp_id="rdbms"
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module=''
pid='6357218'>
Thread 1 advanced to log sequence 14 (LGWR switch)
<msg time="2012-07-08T21:44:00.713-05:00" org_id="oracle" comp_id="rdbms"
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module=''
pid='6357218'>
Current log# 2 seq# 14 mem# 0: /oracle/products/oradata/wolf/redo02.log
<msg time="2012-07-08T21:44:00.890-05:00" org_id="oracle" comp_id="rdbms"
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module='sqlplus@oracle (TNS V1-V3)'
pid='14680092'>
Archived Log entry 10 added for thread 1 sequence 13 ID 0xffffffffdfbf1c80 dest 1:
<msg time="2012-07-08T21:49:47.708-05:00" org_id="oracle" comp_id="rdbms"
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module=''
pid='6160592'>
Completed checkpoint up to RBA [0xe.2.10], SCN: 1140448
<msg time="2012-07-08T22:05:15.112-05:00" org_id="oracle" comp_id="rdbms"
client_id='' type='UNKNOWN' level='16'
host_id='oracle' host_addr='192.168.8.254' module=''
pid='6160592'>
Incremental checkpoint up to RBA [0xe.295.0], current log tail at RBA [0xe.b9b.0]
8、检查点
检查点(Checkpoint)是一个数据库事件,它拥有同步数据库的所有数据文件,控制文件和重做日志。当发出检查点时,后台进程CKPT会将检查点时刻的SCN(System Change Number)写入到控制文件和数据文件头部,同时促使后台进程DBWR将所有的脏缓冲区写入到数据文件中。当Oracle发出检查点时,后台进程CKPT促使后台进程DBWR开始工作,而后台进程DBWR又促使后台进程LGWR开始工作。因为当发出检查点时CKPT、DBWR、LGWR同时工作,所以数据文件、控制文件和重做日志的SCN完全一致,从而使三种数据库文件保持完全同步。
Chpt反生-------他会叫dbwr写-------他会叫lgwr写------lgwr他写完了---dbwr在写-写完
日志切换,日志组写满后,后台进程lgwr会进行日志切换,切换时,系统会促使后台进程ckpt发出checkpoint。
关闭数据库,正常关闭数据库,后台进程会发出检查点,而且要检查点完成之后才关闭数据库,就是上面的一个流程走完。
alter system switch logfile;一般在备份的时候,为了把脏数据块写入数据文件,就手工执行命令,强制ckpt发出checkpoint。
Fast_start_mttr_target,手工指定恢复最大时间,(如果人为设置不科学)当然oracle也会根据参数去调整。
9、实例恢复
实例恢复是指当出现实例失败时有后台进程SMON自动同步数据文件、控制文件和重做日志并打开数据库的过程。
Smon实例恢复过程:
1)确定不同步的物理文件。通过比较数据文件、控制文件和重做日志的SCN,后台进程SMON可以确定哪些文件处于不同步状态。
2)REDO.确定了不同步的数据文件后,SMON会重新应用哪些在数据文件未执行的事务操作,并且DBWR会将提交和未提交的数据写到数据文件及UNDO段上。
3)REDO之后会打开数据库,此时客户应用可以访问数据库。
4)UNDO。在第二步后,数据文件既包含被提交的数据,也包含被提交的数据。打开数据库后,SMON会自动使用UNDO段取消未提交的数据。
四、基本操作
(建议日子切换时间在15-30分钟之间,太短了日志可能归档来不及,太长了,恢复时间增加了)
1) 查看当前日志
SQL> select * from v$log;
2) 查看日志文件路径
SQL> select * from v$logfile;
3) 手动强制切换日志
SQL> alter system switch logfile;
4) 手动归档
SQL> alter system archive log current;
5) 查看历史文件
SQL> select * from v$log_history;
desc v$log_history
select SEQUENCE#,to_char(FIRST_TIME,'yyyy-mm-ddhh24:mi:ss') from v$log_history;
6) 查看归档模式
SQL> select log_mode from v$database;
SQL> archive log list;
7) 增加日志组
SQL> col member for a50
SQL> select * from v$logfile;
GROUP# STATUS TYPE MEMBER
---------- ------- ------- --------------------------------------------------
IS_
---
3 ONLINE /oracle/products/oradata/wolf/redo03.log
NO
2 ONLINE /oracle/products/oradata/wolf/redo02.log
NO
1 ONLINE /oracle/products/oradata/wolf/redo01.log
NO
SQL> alter database add logfile '/oracle/products/oradata/wolf/redo04.log' size 50m;
Database altered.
SQL> select * from v$logfile;
GROUP# STATUS TYPE MEMBER
---------- ------- ------- --------------------------------------------------
IS_
---
3 ONLINE /oracle/products/oradata/wolf/redo03.log
NO
2 ONLINE /oracle/products/oradata/wolf/redo02.log
NO
1 ONLINE /oracle/products/oradata/wolf/redo01.log
NO
GROUP# STATUS TYPE MEMBER
---------- ------- ------- --------------------------------------------------
IS_
---
4 ONLINE /oracle/products/oradata/wolf/redo04.log
NO
SQL> alter database add logfile group 6 '/oracle/redo06.log' size 50m;
上面两种方法都可以添加日志组,不多截图了,占空间。
当然日子组的个数也是有限制的。查看限制也有几种方法
盖总写的
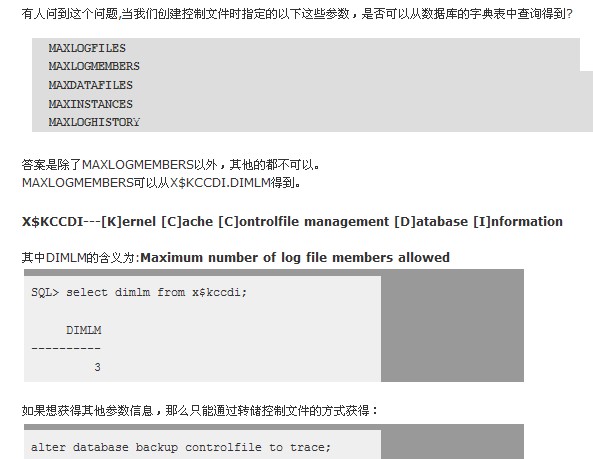
自己按照这个方法去找,没找到,谁帮忙看看?(trace)
SQL> show parameter user_dump_dest
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
user_dump_dest string /oracle/products/diag/rdbms/wo
lf/wolf/trace
SQL> alter system set events 'immediate trace name controlf level 10'
Database altered.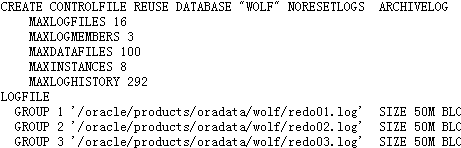
8)删除日志组
SQL> alter database drop logfile group 6;
9) 增加和删除日志成员
alter database add logfile member '/oracle/redo09.log' to group 5;
alter database add logfile member '/oracle/redo10.log' to group 5;
SQL> alter database drop logfile member '/oracle/redo10.log';
在oracle里面删除之后,文件需要手动去删除
10) 移动日志文件或者修改名字
SQL> alter database rename file '/oracle/products/oradata/wolf/redo04.log' to '/oracle/redo04.log';
移动之后目录下redo04.log文件还存在,需要手动删除
11) 如果日志文件发生损坏或者丢失,试用下面的命令恢复
SQL> alter database clear logfile group 5;
SQL> alter database clear logfile group 4;
这里强调一下一定要注意一个问题:无论是移动还是删除日志,日志组的时候一定要看清楚是否是inactive,不然可能报错
SQL> startup force;
\ORACLE instance started.
Total System Global Area 1570009088 bytes
Fixed Size 2207128 bytes
Variable Size 1090519656 bytes
Database Buffers 469762048 bytes
Redo Buffers 7520256 bytes
Database mounted.
ORA-03113: end-of-file on communication channel
Process ID: 8978452
Session ID: 191 Serial number: 3
About Me
...............................................................................................................................
● 本文整理自网络
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-07-01 09:00 ~ 2017-07-31 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。




