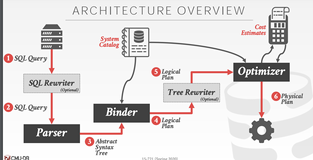
1. Dynamic Sampling (动态采样)
The purpose of dynamic sampling is to improve server performance by determining more accurate selectivity and cardinality estimates.
More accurate selectivity and cardinality estimates allow the optimizer to produce better performing plans.
(动态采样的目的是为了通过更精确的seletivity值cardinality值来提高服务器性能,更精确的seletivity值cardinality值可以让优化器提供更好的执行计划。)
Estimate single-table predicate selectivities when collected statistics cannot be used or are likely to lead to significant errors in estimation.
Estimate table cardinality for tables without statistics or for tables whose statistics are too out of date to trust.
(当没有使用statistics统计信息或者可能导致评估错误的时候,可以提前预估出来单表的selectivities值。
当表没有收集统计信息时,或者表的统计信息过期的时候,可以估算出表的cardinality值。)
2. How Dynamic Sampling Works(动态采样如何工作)
The primary performance attribute is compile time.
Oracle determines at compile time whether a query would benefit from dynamic sampling.
If so, a recursive SQL statement is issued to scan a small random sample of the table's blocks,
and to apply the relevant single table predicates to estimate predicate selectivities.
The sample cardinality can also be used, in some cases, to estimate table cardinality.
(主要的性能影响被归因于编译时间。ORACLE来判断在编译的时候,动态采样是否对查询是否有意。如果是,那么sql语句会发起
相对应表的快的小部分随机采样,然后应用相关的单表去前瞻性预估相应的selectivities值。
3. When to Use Dynamic Sampling(什么时候使用动态采样)
(1) A better plan can be found using dynamic sampling.
使用动态采样可以更好的生成执行计划
(2) The sampling time is a small fraction of total execution time for the query.
动态采样的时间占查询执行的时间一小部分
(3) The query will be executed many times.
查询语句将被执行许多次
4. How to Use Dynamic Sampling to Improve Performance
(如何使用动态采样提高性能)
Level 0: dynamic sampling will not be done.
(动态采样不会收集)
Level 1: (default value) dynamic sampling will be performed if all of the following conditions are true:
默认值,如果如下的条件全部满足的时候,那么动态采样将被执行
(1) There is more than one table in the query.
有超过一个表的查询
(2) Some table has not been analyzed and has no indexes.
一些表没有被分析,而且没有index
(3) The optimizer determines that a relatively expensive table scan would be required for this unanalyzed table. 优化器认为这个没有被分析的表会消耗相当昂贵的表扫描资源)
Level 2: Apply dynamic sampling to all unanalyzed tables.
The number of blocks sampled is the default number of dynamic sampling blocks.
(针对所有没有被分析的表应用动态采样,采样blocks的数量是默认的动态采样的数量)
Level 3: Apply dynamic sampling to all tables that meet Level 2 criteria, plus all tables for which standard selectivity estimation used a guess for some predicate
that is a potential dynamic sampling predicate.
The number of blocks sampled is the default number of dynamic sampling blocks.
(根据level2的标准,应用动态采样到所有的表,以及为一些标准selectivity值的表使用一些采样预测,采样blocks的数量是默认的动态采样的数量)
Level 4: Apply dynamic sampling to all tables that meet Level 3 criteria, plus all tables that have single-table predicates that reference 2 or more columns.
The number of blocks sampled is the default number of dynamic sampling blocks.
(根据level3的标准,应用动态采样到所有的表,以及一些大于2列的单表的预测。采样blocks的数量是默认的动态采样的数量)
Level 5: Apply dynamic sampling to all tables that meet the Level 4 criteria using 2 times the default number of dynamic sampling blocks.
(根据level4的标准,应用动态采样到所有的表,并且采样blocks的数量是默认的动态采样的数量的2倍)
Level 6: Apply dynamic sampling to all tables that meet the Level 5 criteria using 4 times the default number of dynamic sampling blocks.
(根据level5的标准,应用动态采样到所有的表,并且采样blocks的数量是默认的动态采样的数量的4倍)
Level 7: Apply dynamic sampling to all tables that meet the Level 6 criteria using 8 times the default number of dynamic sampling blocks.
(根据level6的标准,应用动态采样到所有的表,并且采样blocks的数量是默认的动态采样的数量的8倍)
Level 8: Apply dynamic sampling to all tables that meet the Level 7 criteria using 32 times the default number of dynamic sampling blocks.
(根据level7的标准,应用动态采样到所有的表,并且采样blocks的数量是默认的动态采样的数量的32倍)
Level 9: Apply dynamic sampling to all tables that meet the Level 8 criteria using 128 times the default number of dynamic sampling blocks.
(根据level8的标准,应用动态采样到所有的表,并且采样blocks的数量是默认的动态采样的数量的128倍)
Level 10: Apply dynamic sampling to all tables that meet the Level 9 criteria using all blocks in the table.
(根据level9的标准,应用动态采样到所有的表,并且采样表中所有的blocks)
Increasing the value of the parameter results in more aggressive application of dynamic sampling, in terms of both the type of tables sampled (analyzed or unanalyzed) and the amount of I/O spent on sampling.
Dynamic sampling is repeatable if no rows have been inserted, deleted, or updated in the table being sampled.
(增加这个参数的值,从表的采样和I/O消耗的角度来说,动态采样将导致更多资源的征用。
在被采样的表中,即使没有记录被insert, deleted, update,采样的操作仍会被重复。)
来自:http://space.itpub.net/9252210/viewspace-608724