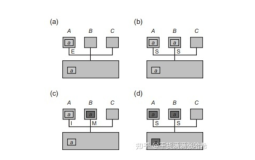
SQL> select * from v$version;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.1.0.6.0 - Production
PL/SQL Release 11.1.0.6.0 - Production
CORE 11.1.0.6.0 Production
TNS for 32-bit Windows: Version 11.1.0.6.0 - Production
NLSRTL Version 11.1.0.6.0 - Production
SQL> select event#,
2 name,
3 parameter1 p1,
4 parameter2 p2,
5 parameter3 p3
6 from v$event_name
7 where name like '%log%file%' or name ='log bufer space';
EVENT# NAME P1 P2 P3
---------- --------------------------------------------- ---- ----- -----
118 log file sequential read log# block# blocks
119 log file single write log# block# blocks
120 log file parallel write files blocks requests
124 log file switch (checkpoint incomplete)
125 log file switch (private strand flush incomplete)
126 log file switch (archiving needed)
127 switch logfile command
128 log file switch completion
129 log file sync buffer#
544 log file switch (clearing log file)
已选择10行
。
log file switch(archiving needed)
日志文件转换,必须归档。在使用归档方式下的数据库时,只有arch进程通过将REDO文件复制到归档日志文件中(完成归档),LGWR进程才可以改写或转换该重做日志文件。 对归档文件的写入失败,可能会中止归档进程,在警告日志中报告。
无参数 等待时间:1秒
这个等待事件出现时通常是因为日志组循环写满以后,第一个日志归档尚未完成,出现该等待。出现该等待
,可能表示io 存在问题。
解决办法:
1 考虑增大日志文件和增加日志组
2 移动归档文件到快速磁盘
3 调整log_archive_max_processes
log file switch(checkpoint imcomplete)
由于对REDO的检查点进程未完成而使日志文件的转换变得不可能。你的日志组都写完以后,LGWR 试图写第
一个log file,如果这时数据库没有完成写出记录在第一个log file 中的dirty 块时(例如第一个检查点未
完成),该等待事件出现。
原因:该等待事件通常表示你的DBWR 写出速度太慢或者IO 存在问题。
解决方法:
1 考虑增加额外的DBWR
2 增加你的日志组或日志文件大小。
无参数 等待时间:1秒
log file switch completion
当日志文件转换完成时产生的等待事件
无参数 等待时间:1秒
log file single write
等待写logfile写完成,在更新logfile头部时发生,在增加一个log file成员的时候增加序列号时发生。
等待时间:物理io完成时间计时
P1: session当前写的日志(组)号
P2: block号
P3: 写的blocks数
log file sequential read
当进程等待从REDO文件中读入块时会产生该等待事件。
参数说明:
P1: 写的log file序列号
P2: os的blocks数
P3: io请求的数量
等待时间:完成请求读取的IO所占用的实际时间。
log file parallel write
当会话等待LGWR 进程将redo log buffer中的redo写入redo log中时产生该事件。LGWR会等待该事件的完
成,用户会话则等待log file sync事件。仅当使用异步IO时LGWR并行写入到redo log,否则它会顺序写入
到每个online redo log。出现该事件意味着重做日志所在的磁盘设备IO缓慢或IO争用。
写入时机:
1 每隔3秒写入一次
2 在提交或回滚时
3 在满足_LOG_IO_SIZE阈值时
4 在日志缓冲区有1MB的重做项时
5 由DBWR提交时
等待参数:
P1: 写的log file序列号
P2: os的blocks数
P3: io请求的数量
等待时间:完成所有IO所占用的实际时间,对于异步IO,则等到最后一个IO操作完成整个写入才算完成。
解决办法:
1 改进IO的性能,使用较快的磁盘设备,不要将redo放在RAID5上。
2 设法降低重做的数量。
只要有可能就使用NOLOGGING选项。
CTAS操作也应该使用该选项
3 热备可能创建大量的重做项,从而增加log file parallel write等待事件,所以热备份应该在非高峰时
间内运行,并且应该尽可能将表空间排除在热备份模式外。
log buffer space
当会话由于log buffer不足而无法将redo条目复制到log buffer时,将会出现log buffer space等待。
LGWR周期性的写出redo条目,以产生可用的log buffer space。该等待事件表示:应用程序生成重做日志的
速度比LGWR进程将其写入重做日志文件的速度快。
这个等待时间没有p1,p2,p3参数
产生该等待的原因及解决办法:
过小的日志缓冲区
1 检查当前LOG BUFFER的设置,并根据需要做适当的调整
缓慢的I/O子系统
1 确保log file parallel write等待事件的平均等待时间在可接受的范围内,否则需要改进IO性能。
2 根据应用程序的情况,在适当的位置设置NOLOGGING选项。
3 作为辅助手段借助Oracle Log miner深入研究来自于v$sql视图或重做日志文件的DML,发现异常行为。
--会话级统计必须等待日志缓冲区的次数。
SELECT s.SID , s.VALUE
FROM v$sesstat s
WHERE s.statistic# =
(SELECT t.statistic#
FROM v$statname t
WHERE t.NAME = 'redo buffer allocation retries');
--系统级统计必须等待日志缓冲区的次数
SELECT s.STATISTIC#, s.CLASS, s.NAME , s.VALUE
FROM v$sysstat s
WHERE s.statistic# =
(SELECT t.statistic#
FROM v$statname t
WHERE t.NAME = 'redo buffer allocation retries')
log file sync
此等待事件用户发出提交或回滚声明后,等待提交完成的事件,提交命令会去做日志同步,也就是写日志缓存
到redo logfile,用户进程将通知LGWR执行写出操作,LGWR完成任务以后会通知用户进程. 在提交命令未完成前,用户将会看见此等待事件,对于回滚操作,该事件记录从用户发出rollback命令到回滚完成的时间.注意,它专指因提交,回滚而造成的写缓存到日志文件的等待.在LGWR同步期间,LGWR进程在log file parallel write事件上等待同步写入完成,而用户会话则在log
file sync事件上等待LGWR的完成。
如果该等待事件过多,可能说明LGWR的写出效率低下,或者系统提交过于频繁.
log file sync等待事件与事务的终止(提交或回滚)相关。当进程在log file sync事件上花费大量时间时,
通常表明过多的提交或短事务。
该等待事件的主要原因:
1 高提交率
高提交率会增加开始与结束事务时的系统开销(事务表的更新、提交后的清除、回滚段的使用被记录在日
志缓冲区中等等)。
2 缓慢的IO子系统
如果日志的I/O系统较为缓慢的话,LGWR的写出效率低下,而用户会话则在log file sync事件上等待LGWR的
完成。
SELECT s.event, s.time_waited, s.average_wait
FROM v$system_event s
WHERE s.event IN ('log file parallel write', 'log file sync')
注:'log file parallel write'事件的平均等待时间大于10ms(1cs),这通常表示存在缓慢的IO吞吐量。
3 过大的日志缓冲区
日志缓冲区过大,会造成LGWR进程写入频率变慢,一次写入量变大,花费较多的时间。
4 较大的processes参数值
在每个同步操作期间,LGWR必须扫描所有进程的数据结构查找哪些会话正在这个事件上等待,并将它们的
重做写入到硬盘
针对该问题,可以关注:
log file parallel write等待事件
user commits,user rollback等统计信息可以用于观察提交或回滚次数
解决方案:
1.提高LGWR性能,尽量使用快速磁盘,不要把redo log file存放在raid 5的磁盘上
2.使用批量提交
3.适当使用NOLOGGING/UNRECOVERABLE等选项
4.设置合适的processes 的大小
附上几个关于redo io 和查询提交频繁的用户的sql语句
1 可以通过如下公式计算平均redo写大小:
avg.redo write size = (Redo block written/redo writes)*512 bytes
select trunc(a.value/b.value*512) as "REDO每次写入字节数",
trunc(1024*1024/3) as "系统设置写入字节数"
from
(SELECT s.VALUE FROM v$sysstat s
WHERE s.NAME = 'redo blocks written') a,
(SELECT s.VALUE FROM v$sysstat s
WHERE s.NAME = 'redo writes') b
2 查询会话中谁执行了大量的提交:
SELECT a.sid,
a.event,
a.time_waited,
round(a.time_waited / c.sum_time_waited * 100, 2) || '%' pct_wait_time,
d.VALUE user_commits,
round((SYSDATE - b.logon_time) * 24) hours_connected
FROM v$session_event a,
v$session b,
(SELECT sid, SUM(time_waited) sum_time_waited
FROM v$session_event
WHERE event NOT IN
('smon timer', 'pmon timer', 'rdbms ipc message', 'Null event',
'parallel query dequeue', 'pipe get', 'client message',
'SQL*Net message to client', 'SQL*Net message from client',
'SQL*Net more data from client', 'dispatcher timer',
'virtual circuit status',
'lock manager wait for remote message', 'PX Idle Wait',
'PX Deq: Execution Msg', 'PX Deq: Table Q Normal',
'wakeup time manager', 'slave wait', 'i/o slave wait',
'jobq slave wait', 'null event', 'gcs remote message',
'gcs for action', 'ges remote message', 'queue messages')
HAVING SUM(time_waited) > 0
GROUP BY sid) c,
v$sesstat d
WHERE a.sid = b.sid
AND a.sid = c.sid
AND a.sid = d.sid
AND d.statistic# =
(SELECT statistic# FROM v$statname WHERE NAME = 'user commits')
AND a.time_waited > 10000
AND a.event = 'log file sync'
ORDER BY hours_connected DESC, pct_wait_time
3 使用以下SQL查出谁在频繁提交数据:
SELECT sid, VALUE
FROM v$sesstat s
WHERE s.statistic# =
(SELECT statistic# FROM v$statname WHERE NAME = 'user commits')
ORDER BY VALUE
SELECT b.NAME, a.VALUE, round(SYSDATE - c.startup_time) day_old
FROM v$sysstat a, v$statname b, v$instance c
WHERE a.statistic# = b.statistic#
AND b.NAME IN ('redo wastage', 'redo size')
注:由于LGWR不象DBWR那样能够有多个,所以尽可能将REDO放在IO快的磁盘结构上,不要放在象RAID5这样的磁盘上。
4 可以使用下需的查询来找到每次写入的平均重做日志块的数量,以及以字节为单位的LGWR IO平均大小:
SELECT round((a.VALUE / b.VALUE) + 0.5, 0) AS avg_redo_blks_per_write,
round((a.VALUE / b.VALUE) + 0.5, 0) * c.lebsz AS avg_io_size -- 字节为单位
FROM v$sysstat a, v$sysstat b, x$kccle c
WHERE c.lenum = 1
AND a.NAME = 'redo blocks written'
AND b.NAME = 'redo writes'
注:x$kccle.lebsz字段包含每个日志块的大小。